
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日共 10 篇 · 扩散语言模型与非自回归生成 1 篇 · 视频生成与编辑 2 篇 · 推理加速与长上下文 3 篇 · 扩散强化学习与奖励模型 2 篇 · 测试时扩展与智能体 1 篇 · Agentic RL 1 篇 · 重点 1 篇深度解读
字节跳动提出层次潜扩散语言模型,挑战自回归范式 | ETH | arXiv:2605.06548
关键词: 扩散模型·语言模型·潜空间·自回归·非自回归
核心问题: 大语言模型绑定于固定左到右自回归序列,难以同时实现生成效率、可扩展表征学习和全局语义建模
大语言模型在自回归范式下取得显著成功,但高质量文本生成不必绑定于固定的从左到右顺序。现有替代方案仍难以同时实现生成效率、可扩展表征学习和有效全局语义建模。字节跳动提出 Cola DLM,通过层次化信息分解框架重新定义文本生成范式。
前序工作及局限:
与前序工作的本质区别: Cola DLM 从马尔可夫路径统一视角出发,将扩散过程定义为潜先验传输而非 token 级观测恢复,首次提出层次化连续潜先验建模,天然支持语义压缩和跨模态扩展
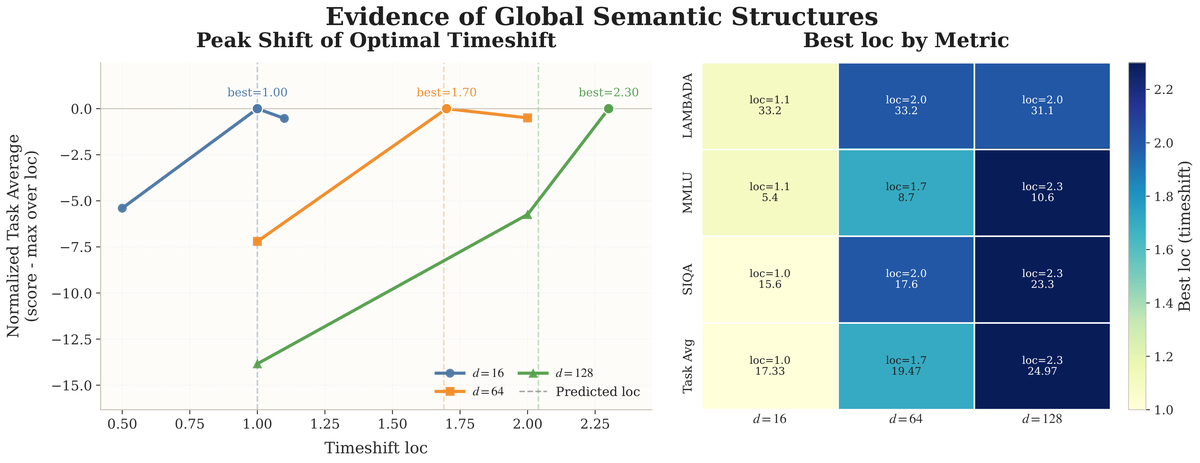
Cola DLM 采用层次潜扩散语言模型架构:首先通过 Text VAE 学习稳定的文本到潜变量映射,然后使用块因果 DiT 在连续潜空间建模全局语义先验,最后通过条件解码输出文本。从统一的马尔可夫路径视角,扩散过程被定义为潜先验传输而非 token 级观测恢复,从而将全局语义组织与局部文本实现分离。
深度点评:
技术演进定位: 扩散语言模型路线的重大突破,首次将层次化连续潜先验建模应用于 ~2B 参数规模,与 LLaDA 等前序工作相比在扩展性和多模态统一性上有本质区别
可能的后续方向:
Relit-LiVE: Relight Video by Jointly Learning Environment Video | ETH
视频重光照 内在分解 环境图预测 时序一致性 ETH
⚠️ 前序问题: 视频重光照现有方法依赖精确的内在分解,但真实世界视频的内在分解高度不可靠,导致外观失真、材质破损和时序伪影累积。
本文贡献: 提出 Relit-LiVE 框架,将原始参考图像显式引入渲染过程,提出环境视频预测公式在单一扩散过程中同时生成重光照视频和每帧环境图,实现强几何-光照对齐。
实验效果: 在合成和真实基准测试上始终超越现有视频重光照和神经渲染方法,支持场景级渲染、材质编辑、物体插入和流式视频重光照等多种下游应用。
MARBLE: Multi-Aspect Reward Balance for Diffusion RL | ETH
扩散RL 多维奖励 梯度平衡 QP优化 SD3.5
⚠️ 前序问题: RL 微调扩散模型需同时优化多维评价标准,朴素加权求和因样本级不匹配导致监督稀释,各维度梯度冲突。
本文贡献: 提出 MARBLE 梯度空间优化框架,维护独立 advantage 估计器,计算每维度策略梯度,通过二次规划协调为统一更新方向,摊销公式降低计算成本。
实验效果: 在 SD3.5 Medium 上同时提升 5 个奖励维度,将最差维度的梯度余弦从 80% 小批次负转为一致正向,训练速度仅降 0.97 倍。
Continuous-Time Distribution Matching for Few-Step Diffusion Distillation | ETH
蒸馏加速 连续时间优化 Flow匹配 SD3 少步生成
⚠️ 前序问题: DMD 等离散时间蒸馏仅在固定锚点执行分布匹配,导致模式寻求偏差、视觉伪影和过度平滑,需 GAN/Reward 等复杂辅助模块修复保真度。
本文贡献: 提出 CDM 框架,首次将分布匹配蒸馏从离散锚点迁移到连续时间优化:随机长度动态调度在采样轨迹任意点执行匹配,连续时间对齐目标在学生速度场外推的偏轨潜变量上进行主动匹配。
实验效果: 在 SD3-Medium 和 Longcat-Image 上实现少步生成高竞争力视觉保真度,无需 GAN/Reward 等复杂辅助目标,代码已开源。
StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction | ETH
智能体RL 轨迹抽象 长程决策 GRPO ALFWorld
⚠️ 前序问题: 现有智能体 RL 方法多为纯反应式,削弱了扩展轨迹上的探索和信用分配能力。
本文贡献: 提出 StraTA 框架,引入显式轨迹级策略到智能体 RL,从初始任务状态采样紧凑策略,使用层次 GRPO 风格 rollout 设计联合训练策略生成和动作执行,增强多样化 rollout 和关键自判断。
实验效果: 在 ALFWorld 达到 93.1%、WebShop 达到 84.2% 成功率,SciWorld 上 63.5% 总分超越前沿闭源模型。
MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference | Nvidia, GLM
稀疏注意力 长上下文 MoE 推理优化 Nvidia
⚠️ 前序问题: DSA 索引器使用大量 query heads(DeepSeek-V3.2 上达 64 个)共享同一 token 选择集,成为长上下文推理的主要成本瓶颈。
本文贡献: 提出 MISA,将索引器 heads 视为 MoE 池,轻量路由器使用块级统计选择少量活跃 heads,保留原始池的多样性同时显著降低每查询成本,还提出层级变体用路由通过放大候选集再由 DSA 重排恢复最终 token。
实验效果: 仅用 8 个活跃 heads 在 LongBench 上匹配密集 DSA 索引器,比 DSA 和 HISA 快 3.82 倍,保持 128K token 上下文全绿 Needle。
Sparkle: Realizing Lively Instruction-Guided Video Background Replacement via Decoupled Guidance
视频编辑 背景替换 数据集 解耦引导 开源
⚠️ 前序问题: 视频背景替换需要合成全新时序一致场景并保持前景-背景交互,高质量训练数据极度稀缺,OpenVE-3M 常生成静态不自然背景。
本文贡献: 设计前景/背景解耦引导+严格质量过滤的可扩展数据合成管线,构建 Sparkle 数据集(~140K 视频对,5 类背景主题)和 Sparkle-Bench 最大背景替换评测基准。
实验效果: 在 OpenVE-Bench 和 Sparkle-Bench 上显著超越所有现有基线(包括 Kiwi-Edit),数据集、基准和模型完全开源。
MDN: Parallelizing Stepwise Momentum for Delta Linear Attention | NJU, NTU
线性注意力 动量 长序列 Mamba2 NJU
⚠️ 前序问题: 线性注意力中朴素 SGD 更新存在快速信息衰减和次优收敛问题,基于动量的优化器在训练效率和效果上难以兼顾。
本文贡献: 开发了带逐步动量规则的线性注意力分块并行算法,通过几何重排更新系数解决效率和效果矛盾;从动力学系统分析动量递推为二阶系统,设计稳定门控约束。
实验效果: 400M 和 1.3B 参数模型在 ALFWorld、WebShop、SciWorld 等下游任务上持续超越 Transformers、Mamba2 和 GDN 基线,训练吞吐量与 Mamba2 可比。
Think, then Score: Decoupled Reasoning and Scoring for Video Reward Modeling | Institute of Software Chinese Academy of Sciences
视频奖励模型 思维链 解耦推理 强化学习 后训练
⚠️ 前序问题: 判别式 RM 无显式推理易走捷径,生成式 CoT-RM 推理与评分耦合导致优化瓶颈和训练不稳定。
本文贡献: 提出 DeScore「先想后评」范式:MLLM 先生成显式 CoT 推理,专用判别模块(可学习查询 token+回归头)独立输出奖励;两阶段训练——判别冷启动(随机掩码)+双目标 RL。
实验效果: 在视频奖励建模多场景评估中展现更强泛化能力和可解释性,高质量推理直接转化为更优模型性能。
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling | Meta
推理时扩展 TTS 智能体发现 Meta 自动化
⚠️ 前序问题: 现有 TTS 策略多为手工设计,依赖研究者的直觉和经验,算力分配空间探索不足。
本文贡献: 提出 AutoTTS 环境驱动框架,将 TTS 策略发现从手工设计转向环境自动化构建;将 width-depth TTS 形式化为控制器综合问题,通过 beta 参数化使搜索可处理。
实验效果: 在数学推理基准上发现的策略相比强手工设计基线在准确率-成本权衡上更优,泛化到 held-out 基准和模型规模,发现成本仅 $39.9 和 160 分钟。
人工智能炼丹君 整理 | 2026-05-11
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注


评论 (0)