搜索到
25
篇与
AIGC
的结果
-
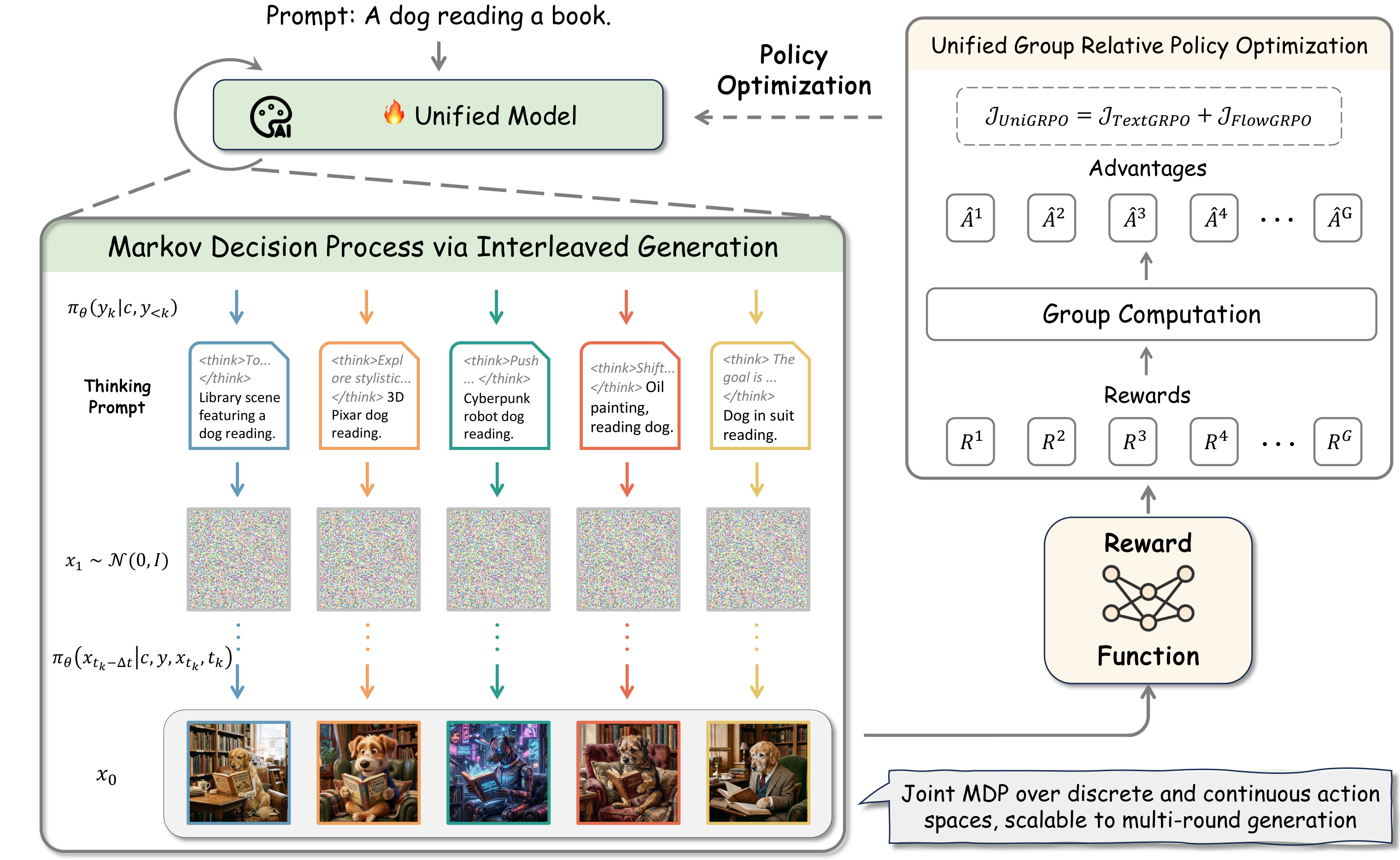
 AIGC 每日速读|2026-03-26 AIGC 视觉生成领域 · 每日论文解读 (2026-03-26) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 生成理解一体化: 1 篇 (UniGRPO 统一 GRPO 框架) 视频生成: 4 篇 (ViBe 超高分辨率 + RealMaster 渲染提升 + InterDyad 语音到视频 + FG-Portrait 肖像动画) 图像编辑: 3 篇 (InverFill 少步修复 + GroupEditing 多图编辑 + Dress-ED 试穿编辑) 图像生成: 1 篇 (Zero-Shot Personalization 零样本个性化) 评测方法: 2 篇 (MuQ-Eval 音乐质量 + Q-Tacit 图像质量) 推理加速: 1 篇 (VHS 潜在验证器) CVPR 2026 × 3 篇 (InverFill, GroupEditing, FG-Portrait) 重点论文深度解读 1. UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation 统一推理驱动视觉生成 | Shanghai AI Lab / The University of Sydney | arXiv:2603.23500 关键词: 统一生成模型, GRPO, FlowGRPO, 推理驱动生成, 强化学习 研究动机 统一生成模型(交错文本和图像生成)已成为多模态AI的重要范式,但如何有效地进行后训练优化以同时提升推理和视觉生成质量仍是开放挑战。现有的强化学习方法要么只针对文本推理,要么只针对视觉生成,缺乏统一的优化框架来联合优化两种模态。 方法原理 提出 UniGRPO,将交错生成建模为具有稀疏终端奖励的马尔可夫决策过程,联合优化文本推理和视觉生成策略。无缝集成文本推理的标准 GRPO 和视觉合成的 FlowGRPO。引入两个关键改进:(1) 消除 Classifier-Free Guidance 以维持线性非分支轨迹,使框架可扩展到多轮交互和条件生成(如编辑);(2) 用速度场上的 MSE 惩罚替代标准潜在 KL 惩罚,提供更稳健的正则化信号来缓解奖励黑客攻击。 核心创新 首个统一优化文本推理和视觉生成的强化学习框架 消除 CFG 实现线性非分支轨迹,支持多轮交互和编辑等复杂场景 速度场 MSE 惩罚替代 KL 散度,更有效缓解奖励黑客攻击 极简设计理念,为未来交错模型后训练提供可扩展基线 实验结果 统一训练配方显著增强了推理驱动的图像生成质量,为完全交错模型的后训练提供了稳健且可扩展的基线方案。 方法流程 交错输入 — 文本提示 + 推理扩展 文本GRPO — 优化推理链质量 FlowGRPO — 优化视觉生成质量 无CFG线性轨迹 MSE惩罚 — 速度场正则化 防奖励黑客 联合输出 — 高质量推理+图像 技术脉络 核心问题: 如何统一优化交错文本推理和视觉生成 前序工作及局限: GRPO (DeepSeek 2024):文本推理的群组相对策略优化 FlowGRPO (2025):Flow Matching 模型的策略优化 与前序工作的本质区别: UniGRPO 首次将两者无缝集成,消除 CFG 实现线性轨迹,速度场 MSE 替代 KL 惩罚 技术演进定位: 统一生成模型后训练优化的开拓性基线工作 可能的后续方向: 多轮交错生成优化 视频+音频的统一生成优化 更高效的奖励信号设计 批判性点评 新颖性: 极简设计理念值得赞赏——无缝集成已有 GRPO 和 FlowGRPO,速度场 MSE 惩罚替代 KL 散度是巧妙的工程创新。但理论贡献有限。 可复现性: 消除 CFG 的决策对不同模型架构的通用性需要更多验证,且实验对比基线不够全面。 影响力: 为统一模型后训练提供了重要基线,但能否成为标准范式还取决于多轮场景下的表现。 2. ViBe: Ultra-High-Resolution Video Synthesis Born from Pure Images 纯图像驱动超高分辨率视频合成 | SJTU | arXiv:2603.23326 关键词: 超高分辨率, 视频合成, Relay LoRA, 高频感知, 纯图像训练 研究动机 基于 Transformer 的视频扩散模型依赖 3D 空间-时间注意力,其二次方复杂度使得超高分辨率视频的端到端训练成本极高。直接用高分辨率图像微调视频模型会因图像-视频模态差距引入明显噪声。如何在不使用任何视频训练数据的情况下,让预训练的视频扩散模型生成超高分辨率视频? 方法原理 提出纯图像适应框架,通过 Relay LoRA 两阶段策略升级视频 DiT。第一阶段:用低分辨率图像将视频扩散模型适应到图像域,弥合模态差距。第二阶段:用高分辨率图像进一步适应以获得空间外推能力。推理时仅保留高分辨率适应,保持视频生成模态。另外提出高频感知训练目标(HF-ATO),通过专用重建损失显式鼓励模型从退化潜在表示中恢复高频细节。 核心创新 首个纯图像适应实现超高分辨率视频合成的框架,无需任何视频训练数据 Relay LoRA 两阶段策略解耦模态对齐和空间外推 高频感知训练目标(HF-ATO)增强细粒度细节合成 VBench 基准超越基于高分辨率视频训练的 SOTA 模型 0.8 分 实验结果 在 VBench 基准上超越此前最先进的高分辨率视频训练模型 0.8 分,生成的超高分辨率视频具有丰富的视觉细节。代码即将开源。 方法流程 预训练Video DiT — 原始分辨率视频模型 Stage 1: 模态对齐 — 低分辨率图像 LoRA 弥合图像-视频差距 Stage 2: 空间外推 — 高分辨率图像 LoRA 获取超分能力 HF-ATO — 高频感知训练目标 恢复细节 超高分辨率视频 — 无需视频训练数据 技术脉络 核心问题: 如何在不使用视频数据的情况下实现超高分辨率视频合成 前序工作及局限: Video DiT (Sora 2024):大规模视频扩散 Transformer 预训练 LoRA (Hu et al. 2022):低秩适应微调方法 与前序工作的本质区别: ViBe 提出 Relay LoRA 两阶段策略解耦模态对齐和空间外推,HF-ATO 恢复高频细节 技术演进定位: 挑战了视频训练的必要性,开辟了纯图像数据提升视频质量的新路径 可能的后续方向: 更高分辨率(8K+)视频生成 纯图像训练的长视频一致性改进 与视频训练的融合策略 批判性点评 新颖性: Relay LoRA 两阶段策略巧妙解耦了模态对齐和空间外推,HF-ATO 训练目标是重要的技术贡献。核心洞察(图像训练可替代视频训练)具有深远影响。 可复现性: 方法简洁清晰,但高分辨率图像数据的质量和规模对结果的影响需要更多消融实验。 影响力: 如果确实不需要视频数据就能生成超高分辨率视频,将大幅降低视频生成的训练成本,具有很高的实用价值。 3. InverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting 一步逆变换加速少步扩散修复 | VinAI Research | CVPR 2026 | arXiv:2603.23463 关键词: 图像修复, 少步扩散, 一步逆变换, 语义对齐噪声, CVPR 2026 研究动机 基于扩散的图像修复模型虽然实现了照片级真实感,但需要大量采样步骤。少步文本到图像模型提供更快生成速度,但直接用于修复会导致背景和修复区域之间的协调性差和伪影。问题根源在于随机高斯噪声初始化,在低函数评估次数下会导致语义错位和保真度降低。 方法原理 提出 InverFill,一种专为修复定制的一步逆变换方法。将输入掩码图像的语义信息注入到初始噪声中,实现高保真少步修复。利用少步 T2I 模型在混合采样管线中处理,以语义对齐噪声作为输入。不需要训练修复模型,不需要真实图像监督,只增加极小推理开销。 核心创新 一步逆变换将掩码图像语义注入初始噪声,解决少步扩散修复的语义错位问题 无需训练专门的修复模型,直接利用少步 T2I 模型 混合采样管线在低 NFE 下匹配专门修复模型的质量 CVPR 2026 主会议论文,即插即用,不需要真实图像监督 实验结果 持续提升基线少步模型表现,改善图像质量和文本连贯性,在低 NFE 下甚至匹配专门的修复模型,无需昂贵的重训练或迭代优化。 方法流程 掩码图像 — 待修复区域+已知背景 一步逆变换 — 提取语义信息 注入初始噪声 语义对齐噪声 — 替代随机高斯噪声 混合采样管线 — 少步T2I模型生成 高保真修复 — 2-4步即达到高质量 技术脉络 核心问题: 如何在极少采样步数下实现高质量图像修复 前序工作及局限: Blended Diffusion (Avrahami 2022):混合扩散采样修复 LCM (Luo 2023):潜在一致性模型实现少步生成 与前序工作的本质区别: InverFill 通过一步逆变换将掩码图像语义注入噪声,解决少步下的语义错位 技术演进定位: 少步扩散修复的即插即用加速方案,CVPR 2026 可能的后续方向: 视频修复的少步化 与 Turbo/Lightning 模型的深度集成 实时交互式修复应用 批判性点评 新颖性: 将修复问题归因于噪声初始化的分析精准,一步逆变换方案简洁有效。即插即用、无需训练是重要的实用优势。 可复现性: 方法描述清晰,推理开销极小,非常适合实际部署。代码承诺开源。 影响力: 直接提升现有少步模型的修复能力,为快速修复应用提供了低成本解决方案。 批判性点评精选 1. 统一RL框架成为多模态后训练新标配? UniGRPO 的极简集成策略展示了一条清晰的技术路线:在统一模型中,针对不同模态使用各自成熟的优化方法,通过共享奖励信号统一训练。这种模块化思路可能比重新设计全新算法更实用。 2. 视频训练数据的必要性被动摇 ViBe 证明了纯图像数据+精心设计的适应策略就能超越用视频数据训练的模型。这一发现可能引发对数据策略的重新思考:高质量图像数据的价值可能被低估了。 3. 噪声初始化:被忽视的性能瓶颈 InverFill 揭示了少步扩散中一个长期被忽视的问题——随机噪声初始化是质量下降的根本原因。这一洞察可能推动更多研究关注「智能初始化」而非仅仅关注采样策略。 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 1 Group Editing (Edit Multiple Images in One Go) 多图编辑 · 几何对应 · CVPR 2026 利用 VGGT 几何对应和伪视频时序先验实现多图一致性编辑,构建大规模 GroupEditData 数据集,CVPR 2026 论文。 首次实现多视图一致性编辑,在多图编辑质量和一致性上显著超越现有方法 2 Dress-ED (Instruction-Guided Editing for Virtual Try-On and Try-Off) 虚拟试穿 · 服装编辑 · 大规模基准 首个统一虚拟试穿、脱衣和文本引导服装编辑的大规模基准(146K 四元组),含多模态扩散基线框架。 提供 146K 高质量四元组数据集,多模态扩散基线在三项任务上达到强性能 3 VHS (Tiny Inference-Time Scaling with Latent Verifiers) 推理加速 · 潜在验证器 · DiT 直接在 DiT 中间隐藏状态上操作轻量验证器进行推理时缩放,无需完整解码即可评估生成质量。 减少 63% 推理时间和 51% FLOPs,GenEval 提升 2.7%,高效推理时质量筛选 4 FG-Portrait (3D Flow Guided Editable Portrait Animation) 肖像动画 · 3D 流引导 · CVPR 2026 引入 3D 流作为几何驱动运动对应,通过深度引导采样和 3D 流编码实现高保真可编辑肖像动画,CVPR 2026。 在肖像动画质量和可编辑性上超越现有方法,支持表情/头部姿态精细控制 5 InterDyad (Interactive Dyadic Speech-to-Video Generation) 语音到视频 · 双人交互 · MLLM 基于 MLLM 提取语言意图和角色感知双高斯引导,实现交互式双人语音到视频生成的自然动力学合成。 首次实现双人交互式语音到视频生成,自然对话动力学模拟逼真 6 Zero-Shot Personalization (Personalization of Objects via Textual Inversion) 零样本个性化 · 文本逆变换 · 免训练 学习网络预测物体专属文本逆变换嵌入,单次前向实现任意物体的零样本个性化生成,首个通用免训练方案。 单次前向即可实现高质量个性化生成,无需每个物体微调,通用性强 7 MuQ-Eval (Open-Source Per-Sample Quality Metric for AI Music Generation) 音乐质量评估 · 开源指标 · MuQ 开源的逐样本 AI 音乐质量评估指标,基于冻结 MuQ-310M 特征实现高精度质量评分。 系统级 SRCC=0.957,单曲级 SRCC=0.838,为 AI 音乐评估提供标准工具 8 Q-Tacit (Image Quality Assessment via Latent Visual Reasoning) 图像质量评估 · 潜在推理 · 结构化先验 提出潜在质量空间推理新范式,注入结构化视觉质量先验并校准推理轨迹,用更少 token 实现强 IQA 性能。 用更少 token 达到 SOTA 级图像质量评估性能,推理效率显著提升 9 RealMaster (Lifting Rendered Scenes into Photorealistic Video) 渲染转真实 · 视频扩散 · IC-LoRA 利用视频扩散模型将 3D 引擎渲染视频提升为逼真视频,通过锚点传播和 IC-LoRA 保持完整几何对齐。 将合成渲染视频转化为逼真视频,保持完整几何对齐和时间一致性 趋势观察 统一生成+推理 — UniGRPO 将 GRPO 扩展到交错文本-图像生成的联合优化,推理驱动生成成为新趋势 无视频训练的视频升级 — ViBe 仅用图像数据实现超高分辨率视频合成,挑战了视频训练的必要性 少步扩散实用化 — InverFill 通过语义噪声注入让 2-4 步修复达到专用模型水平,少步推理持续成熟 人工智能炼丹师 整理 | 2026-03-26
AIGC 每日速读|2026-03-26 AIGC 视觉生成领域 · 每日论文解读 (2026-03-26) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 生成理解一体化: 1 篇 (UniGRPO 统一 GRPO 框架) 视频生成: 4 篇 (ViBe 超高分辨率 + RealMaster 渲染提升 + InterDyad 语音到视频 + FG-Portrait 肖像动画) 图像编辑: 3 篇 (InverFill 少步修复 + GroupEditing 多图编辑 + Dress-ED 试穿编辑) 图像生成: 1 篇 (Zero-Shot Personalization 零样本个性化) 评测方法: 2 篇 (MuQ-Eval 音乐质量 + Q-Tacit 图像质量) 推理加速: 1 篇 (VHS 潜在验证器) CVPR 2026 × 3 篇 (InverFill, GroupEditing, FG-Portrait) 重点论文深度解读 1. UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation 统一推理驱动视觉生成 | Shanghai AI Lab / The University of Sydney | arXiv:2603.23500 关键词: 统一生成模型, GRPO, FlowGRPO, 推理驱动生成, 强化学习 研究动机 统一生成模型(交错文本和图像生成)已成为多模态AI的重要范式,但如何有效地进行后训练优化以同时提升推理和视觉生成质量仍是开放挑战。现有的强化学习方法要么只针对文本推理,要么只针对视觉生成,缺乏统一的优化框架来联合优化两种模态。 方法原理 提出 UniGRPO,将交错生成建模为具有稀疏终端奖励的马尔可夫决策过程,联合优化文本推理和视觉生成策略。无缝集成文本推理的标准 GRPO 和视觉合成的 FlowGRPO。引入两个关键改进:(1) 消除 Classifier-Free Guidance 以维持线性非分支轨迹,使框架可扩展到多轮交互和条件生成(如编辑);(2) 用速度场上的 MSE 惩罚替代标准潜在 KL 惩罚,提供更稳健的正则化信号来缓解奖励黑客攻击。 核心创新 首个统一优化文本推理和视觉生成的强化学习框架 消除 CFG 实现线性非分支轨迹,支持多轮交互和编辑等复杂场景 速度场 MSE 惩罚替代 KL 散度,更有效缓解奖励黑客攻击 极简设计理念,为未来交错模型后训练提供可扩展基线 实验结果 统一训练配方显著增强了推理驱动的图像生成质量,为完全交错模型的后训练提供了稳健且可扩展的基线方案。 方法流程 交错输入 — 文本提示 + 推理扩展 文本GRPO — 优化推理链质量 FlowGRPO — 优化视觉生成质量 无CFG线性轨迹 MSE惩罚 — 速度场正则化 防奖励黑客 联合输出 — 高质量推理+图像 技术脉络 核心问题: 如何统一优化交错文本推理和视觉生成 前序工作及局限: GRPO (DeepSeek 2024):文本推理的群组相对策略优化 FlowGRPO (2025):Flow Matching 模型的策略优化 与前序工作的本质区别: UniGRPO 首次将两者无缝集成,消除 CFG 实现线性轨迹,速度场 MSE 替代 KL 惩罚 技术演进定位: 统一生成模型后训练优化的开拓性基线工作 可能的后续方向: 多轮交错生成优化 视频+音频的统一生成优化 更高效的奖励信号设计 批判性点评 新颖性: 极简设计理念值得赞赏——无缝集成已有 GRPO 和 FlowGRPO,速度场 MSE 惩罚替代 KL 散度是巧妙的工程创新。但理论贡献有限。 可复现性: 消除 CFG 的决策对不同模型架构的通用性需要更多验证,且实验对比基线不够全面。 影响力: 为统一模型后训练提供了重要基线,但能否成为标准范式还取决于多轮场景下的表现。 2. ViBe: Ultra-High-Resolution Video Synthesis Born from Pure Images 纯图像驱动超高分辨率视频合成 | SJTU | arXiv:2603.23326 关键词: 超高分辨率, 视频合成, Relay LoRA, 高频感知, 纯图像训练 研究动机 基于 Transformer 的视频扩散模型依赖 3D 空间-时间注意力,其二次方复杂度使得超高分辨率视频的端到端训练成本极高。直接用高分辨率图像微调视频模型会因图像-视频模态差距引入明显噪声。如何在不使用任何视频训练数据的情况下,让预训练的视频扩散模型生成超高分辨率视频? 方法原理 提出纯图像适应框架,通过 Relay LoRA 两阶段策略升级视频 DiT。第一阶段:用低分辨率图像将视频扩散模型适应到图像域,弥合模态差距。第二阶段:用高分辨率图像进一步适应以获得空间外推能力。推理时仅保留高分辨率适应,保持视频生成模态。另外提出高频感知训练目标(HF-ATO),通过专用重建损失显式鼓励模型从退化潜在表示中恢复高频细节。 核心创新 首个纯图像适应实现超高分辨率视频合成的框架,无需任何视频训练数据 Relay LoRA 两阶段策略解耦模态对齐和空间外推 高频感知训练目标(HF-ATO)增强细粒度细节合成 VBench 基准超越基于高分辨率视频训练的 SOTA 模型 0.8 分 实验结果 在 VBench 基准上超越此前最先进的高分辨率视频训练模型 0.8 分,生成的超高分辨率视频具有丰富的视觉细节。代码即将开源。 方法流程 预训练Video DiT — 原始分辨率视频模型 Stage 1: 模态对齐 — 低分辨率图像 LoRA 弥合图像-视频差距 Stage 2: 空间外推 — 高分辨率图像 LoRA 获取超分能力 HF-ATO — 高频感知训练目标 恢复细节 超高分辨率视频 — 无需视频训练数据 技术脉络 核心问题: 如何在不使用视频数据的情况下实现超高分辨率视频合成 前序工作及局限: Video DiT (Sora 2024):大规模视频扩散 Transformer 预训练 LoRA (Hu et al. 2022):低秩适应微调方法 与前序工作的本质区别: ViBe 提出 Relay LoRA 两阶段策略解耦模态对齐和空间外推,HF-ATO 恢复高频细节 技术演进定位: 挑战了视频训练的必要性,开辟了纯图像数据提升视频质量的新路径 可能的后续方向: 更高分辨率(8K+)视频生成 纯图像训练的长视频一致性改进 与视频训练的融合策略 批判性点评 新颖性: Relay LoRA 两阶段策略巧妙解耦了模态对齐和空间外推,HF-ATO 训练目标是重要的技术贡献。核心洞察(图像训练可替代视频训练)具有深远影响。 可复现性: 方法简洁清晰,但高分辨率图像数据的质量和规模对结果的影响需要更多消融实验。 影响力: 如果确实不需要视频数据就能生成超高分辨率视频,将大幅降低视频生成的训练成本,具有很高的实用价值。 3. InverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting 一步逆变换加速少步扩散修复 | VinAI Research | CVPR 2026 | arXiv:2603.23463 关键词: 图像修复, 少步扩散, 一步逆变换, 语义对齐噪声, CVPR 2026 研究动机 基于扩散的图像修复模型虽然实现了照片级真实感,但需要大量采样步骤。少步文本到图像模型提供更快生成速度,但直接用于修复会导致背景和修复区域之间的协调性差和伪影。问题根源在于随机高斯噪声初始化,在低函数评估次数下会导致语义错位和保真度降低。 方法原理 提出 InverFill,一种专为修复定制的一步逆变换方法。将输入掩码图像的语义信息注入到初始噪声中,实现高保真少步修复。利用少步 T2I 模型在混合采样管线中处理,以语义对齐噪声作为输入。不需要训练修复模型,不需要真实图像监督,只增加极小推理开销。 核心创新 一步逆变换将掩码图像语义注入初始噪声,解决少步扩散修复的语义错位问题 无需训练专门的修复模型,直接利用少步 T2I 模型 混合采样管线在低 NFE 下匹配专门修复模型的质量 CVPR 2026 主会议论文,即插即用,不需要真实图像监督 实验结果 持续提升基线少步模型表现,改善图像质量和文本连贯性,在低 NFE 下甚至匹配专门的修复模型,无需昂贵的重训练或迭代优化。 方法流程 掩码图像 — 待修复区域+已知背景 一步逆变换 — 提取语义信息 注入初始噪声 语义对齐噪声 — 替代随机高斯噪声 混合采样管线 — 少步T2I模型生成 高保真修复 — 2-4步即达到高质量 技术脉络 核心问题: 如何在极少采样步数下实现高质量图像修复 前序工作及局限: Blended Diffusion (Avrahami 2022):混合扩散采样修复 LCM (Luo 2023):潜在一致性模型实现少步生成 与前序工作的本质区别: InverFill 通过一步逆变换将掩码图像语义注入噪声,解决少步下的语义错位 技术演进定位: 少步扩散修复的即插即用加速方案,CVPR 2026 可能的后续方向: 视频修复的少步化 与 Turbo/Lightning 模型的深度集成 实时交互式修复应用 批判性点评 新颖性: 将修复问题归因于噪声初始化的分析精准,一步逆变换方案简洁有效。即插即用、无需训练是重要的实用优势。 可复现性: 方法描述清晰,推理开销极小,非常适合实际部署。代码承诺开源。 影响力: 直接提升现有少步模型的修复能力,为快速修复应用提供了低成本解决方案。 批判性点评精选 1. 统一RL框架成为多模态后训练新标配? UniGRPO 的极简集成策略展示了一条清晰的技术路线:在统一模型中,针对不同模态使用各自成熟的优化方法,通过共享奖励信号统一训练。这种模块化思路可能比重新设计全新算法更实用。 2. 视频训练数据的必要性被动摇 ViBe 证明了纯图像数据+精心设计的适应策略就能超越用视频数据训练的模型。这一发现可能引发对数据策略的重新思考:高质量图像数据的价值可能被低估了。 3. 噪声初始化:被忽视的性能瓶颈 InverFill 揭示了少步扩散中一个长期被忽视的问题——随机噪声初始化是质量下降的根本原因。这一洞察可能推动更多研究关注「智能初始化」而非仅仅关注采样策略。 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 1 Group Editing (Edit Multiple Images in One Go) 多图编辑 · 几何对应 · CVPR 2026 利用 VGGT 几何对应和伪视频时序先验实现多图一致性编辑,构建大规模 GroupEditData 数据集,CVPR 2026 论文。 首次实现多视图一致性编辑,在多图编辑质量和一致性上显著超越现有方法 2 Dress-ED (Instruction-Guided Editing for Virtual Try-On and Try-Off) 虚拟试穿 · 服装编辑 · 大规模基准 首个统一虚拟试穿、脱衣和文本引导服装编辑的大规模基准(146K 四元组),含多模态扩散基线框架。 提供 146K 高质量四元组数据集,多模态扩散基线在三项任务上达到强性能 3 VHS (Tiny Inference-Time Scaling with Latent Verifiers) 推理加速 · 潜在验证器 · DiT 直接在 DiT 中间隐藏状态上操作轻量验证器进行推理时缩放,无需完整解码即可评估生成质量。 减少 63% 推理时间和 51% FLOPs,GenEval 提升 2.7%,高效推理时质量筛选 4 FG-Portrait (3D Flow Guided Editable Portrait Animation) 肖像动画 · 3D 流引导 · CVPR 2026 引入 3D 流作为几何驱动运动对应,通过深度引导采样和 3D 流编码实现高保真可编辑肖像动画,CVPR 2026。 在肖像动画质量和可编辑性上超越现有方法,支持表情/头部姿态精细控制 5 InterDyad (Interactive Dyadic Speech-to-Video Generation) 语音到视频 · 双人交互 · MLLM 基于 MLLM 提取语言意图和角色感知双高斯引导,实现交互式双人语音到视频生成的自然动力学合成。 首次实现双人交互式语音到视频生成,自然对话动力学模拟逼真 6 Zero-Shot Personalization (Personalization of Objects via Textual Inversion) 零样本个性化 · 文本逆变换 · 免训练 学习网络预测物体专属文本逆变换嵌入,单次前向实现任意物体的零样本个性化生成,首个通用免训练方案。 单次前向即可实现高质量个性化生成,无需每个物体微调,通用性强 7 MuQ-Eval (Open-Source Per-Sample Quality Metric for AI Music Generation) 音乐质量评估 · 开源指标 · MuQ 开源的逐样本 AI 音乐质量评估指标,基于冻结 MuQ-310M 特征实现高精度质量评分。 系统级 SRCC=0.957,单曲级 SRCC=0.838,为 AI 音乐评估提供标准工具 8 Q-Tacit (Image Quality Assessment via Latent Visual Reasoning) 图像质量评估 · 潜在推理 · 结构化先验 提出潜在质量空间推理新范式,注入结构化视觉质量先验并校准推理轨迹,用更少 token 实现强 IQA 性能。 用更少 token 达到 SOTA 级图像质量评估性能,推理效率显著提升 9 RealMaster (Lifting Rendered Scenes into Photorealistic Video) 渲染转真实 · 视频扩散 · IC-LoRA 利用视频扩散模型将 3D 引擎渲染视频提升为逼真视频,通过锚点传播和 IC-LoRA 保持完整几何对齐。 将合成渲染视频转化为逼真视频,保持完整几何对齐和时间一致性 趋势观察 统一生成+推理 — UniGRPO 将 GRPO 扩展到交错文本-图像生成的联合优化,推理驱动生成成为新趋势 无视频训练的视频升级 — ViBe 仅用图像数据实现超高分辨率视频合成,挑战了视频训练的必要性 少步扩散实用化 — InverFill 通过语义噪声注入让 2-4 步修复达到专用模型水平,少步推理持续成熟 人工智能炼丹师 整理 | 2026-03-26 -
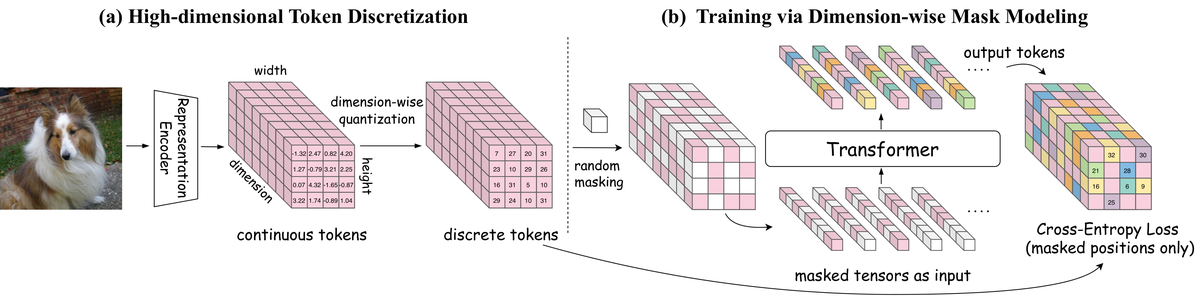
AIGC 每日速读|2026-03-24|CubiD·扩散加速·FoleyDirector AIGC 视觉生成领域 · 每日论文解读 (2026-03-24) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日核心看点 高维离散扩散 统一生成理解 通用扩散加速 V2A时序控制 个性化视频生成 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 图像生成与编辑 — 4 篇(CubiD、妆容迁移、I2I整流流、统一多模态) 视频生成 — 2 篇(LumosX 个性化、MME-CoF-Pro 评测) 音频生成 — 3 篇(FoleyDirector V2A、Borderless Long Speech、MOSS-TTSD) 生成模型加速 — 1 篇(时间步感知块掩码) 评测与质量评估 — 2 篇(TATAR 统一IQA+IAA、PGD-EIQA 去偏) 含 2 篇 CVPR 2026 + 1 篇 ICLR 2026 重点论文深度解读 1. CubiD: Cubic Discrete Diffusion for High-Dim Tokens 首个高维离散扩散生成 | HKU + Google + ByteDance | arXiv:2603.19232 关键词: 离散扩散, 高维表示, 统一生成理解, ImageNet SOTA 研究动机 离散 Token 视觉生成因能与语言模型共享统一的 Token 预测范式而备受关注,但当前方法局限于低维潜在 Token(通常 8-32 维),牺牲了对理解任务至关重要的语义丰富性。高维预训练表示(768-1024 维)理论上可弥补这一鸿沟,然而其离散化生成面临根本性挑战——维度爆炸导致码本大小和生成步数均不可控。 方法原理 CubiD 提出在高维离散表示上进行「细粒度掩码扩散」。核心思想是:对高维离散表示的任意维度、任意位置都可以独立掩码和预测。具体包括:(1) 将预训练的 768/1024 维连续表示通过残差向量量化离散化;(2) 在扩散过程中,每个空间位置的每个维度都可被独立掩码,模型从部分观测中预测缺失维度;(3) 这使模型能学习空间位置内部和跨位置的丰富关联,且生成步数固定为 T(T 远小于 h×w×d),不随维度增长;(4) 从 900M 扩展到 3.7B 参数展现出强 Scaling 行为。 核心创新 首个面向高维(768-1024维)表示的离散扩散生成模型 细粒度维度级掩码策略:任意维度任意位置可独立掩码预测 生成步数与特征维度解耦(T << h×w×d) 验证离散化 Token 同时支持理解和生成任务 M-3.7B 参数强 Scaling 行为 实验结果 ImageNet-256 上达到离散生成方法 SOTA,从 900M 到 3.7B 展现强 Scaling 行为。关键验证:离散化后的 Token 保留了原始表示的理解能力,证明同一组离散 Token 可同时服务于理解和生成任务。代码已开源。 方法流程 预训练表示 — 768/1024维连续特征(如DINOv2/CLIP) 残差向量量化 — RVQ离散化为高维Token序列 细粒度维度掩码 — 任意位置任意维度独立掩码 条件扩散预测 — 从部分观测预测缺失维度 位置内+跨位置关联 — 同时建模局部和全局依赖 固定T步生成 — 步数与维度解耦 T<<hwd 技术脉络 核心问题: 离散 Token 生成局限于低维(8-32维),无法利用高维预训练表示 前序工作及局限: MaskGIT (Chang 2022):掩码图像建模范式,但限于低维 VQ-VAE Token MAGVIT-v2 (Yu 2024):改进离散 Tokenizer,仍为 32 维以下 MAR (Li 2024):掩码自回归模型,连续/离散混合但维度受限 LlamaGen (Sun 2024):用 LLM 架构做视觉生成,仍依赖低维码本 与前序工作的本质区别: CubiD 首次突破维度限制,在 768-1024 维上实现细粒度维度级掩码扩散,且生成步数不随维度增长 技术演进定位: 开辟了「高维离散扩散」新赛道,为 vision-language 统一架构提供了新范式 可能的后续方向: 更高分辨率(512+)的高维离散生成 视频领域的高维离散扩散 与 LLM 的原生融合统一架构 批判性点评 实验评估: 在 ImageNet-256 上对比了多种离散生成方法,展示了 Scaling 行为。但缺少 FID/IS 等具体数值对比表,也未在 T2I 场景下与 SDXL/DALL-E 3 等连续方法直接对比。 新颖性: 首次将离散扩散扩展到高维表示(768-1024维),维度级掩码策略新颖度高。但 RVQ 离散化本身是已有技术,核心贡献在于将掩码扩散泛化到高维。 可复现性: 代码已开源(GitHub),数据集为公开的 ImageNet。但 3.7B 模型的训练成本可能限制社区复现。 影响力: 可能推动统一 vision-language 架构的发展。如果高维离散 Token 真正兼顾理解和生成,将对多模态基础模型产生深远影响。 2. Timestep-Aware Block Masking for Diffusion Acceleration 架构无关扩散加速 | 武汉大学 | arXiv:2603.19939 关键词: 扩散加速, 块掩码, 架构无关, 特征复用 研究动机 扩散概率模型在图像生成方面取得了巨大成功,但迭代去噪的特性导致推理延迟较高。现有加速方法要么需要全链反向传播(内存开销大),要么绑定特定架构。如何实现一种内存高效、架构无关的扩散加速方法是核心问题。 方法原理 提出时间步感知块掩码(Timestep-Aware Block Masking)框架。核心思路:对预训练扩散模型的计算图进行逐时间步优化。(1) 学习时间步特异性掩码(per-timestep masks),在每个推理阶段动态决定哪些 Block 执行完整计算、哪些通过特征复用绕过;(2) 独立优化每个时间步的掩码(而非全链反向传播),确保内存高效训练;(3) 引入时间步感知损失缩放机制,在敏感的去噪阶段优先保证特征保真度;(4) 辅以知识引导的掩码修正策略,修剪冗余的时空依赖关系。 核心创新 架构无关:同一框架适用于 DDPM、LDM、DiT、PixArt 四种主流架构 逐时间步独立优化掩码,避免全链反向传播的高内存开销 时间步感知损失缩放:敏感阶段保真度优先 知识引导掩码修正:智能修剪冗余时空依赖 实验结果 在 DDPM、LDM、DiT 和 PixArt 四种架构上均展示了显著的效率提升。将去噪过程视为一系列优化的计算路径,在采样速度和生成质量之间实现了优越的平衡。代码将公开发布。 方法流程 预训练扩散模型 — 支持DDPM/LDM/DiT/PixArt 逐时间步掩码学习 — 独立优化每步的Block选择 损失缩放机制 — 敏感阶段高权重保真度优先 掩码修正策略 — 知识引导修剪冗余依赖 动态Block跳过 — 低贡献Block特征复用 加速推理输出 — 速度-质量最优平衡 技术脉络 核心问题: 扩散模型推理慢,现有加速方法绑定特定架构或需高内存全链优化 前序工作及局限: DDIM (Song 2021):减少采样步数的非马尔可夫加速 DPM-Solver (Lu 2022):高阶 ODE 求解器加速采样 DeepCache (Ma 2024):缓存 U-Net 特征跨步复用,绑定 U-Net 架构 Token Merging (Bolya 2023):合并冗余 Token 减少计算量 与前序工作的本质区别: Timestep-Aware Block Masking 是架构无关的:同一框架直接适用于 DDPM/LDM/DiT/PixArt,且通过逐步独立优化避免全链反向传播的内存瓶颈 技术演进定位: 在扩散加速领域建立了首个「架构无关」通用框架的先例 可能的后续方向: 与步数蒸馏方法结合实现多维加速 扩展到视频扩散模型 在移动端部署场景的适配 批判性点评 实验评估: 覆盖 DDPM/LDM/DiT/PixArt 四种架构,实验全面性好。但缺少与 DeepCache、FORA 等最新 cache 方法的定量对比。加速比和质量损失的 trade-off 曲线有待补充。 新颖性: 逐时间步独立优化掩码思路清晰,时间步感知损失缩放有理论依据。但 Block 跳过/特征复用的整体思路与 Token Merging、DeepCache 类似,差异化主要在于掩码学习策略。 可复现性: 代码承诺公开但尚未发布。方法依赖少量校准数据训练掩码,流程相对简单可复现。 影响力: 架构无关的特性使其具有广泛适用性。若能在实际产品级部署中验证(如 SDXL/Flux),工程价值将非常高。 3. FoleyDirector: Fine-Grained V2A Temporal Control 细粒度 V2A 时序控制 | CVPR 2026 | arXiv:2603.19857 关键词: V2A, 时序控制, DiT音频, CVPR 2026 研究动机 视频到音频(V2A)方法已能合成高质量音频,但在多事件场景或视觉线索不足时(小区域、画外音、遮挡物体),细粒度时序控制仍是难题。现有方法无法精确指定每个时间段应生成什么声音,限制了创作灵活性。 方法原理 FoleyDirector 是首个在 DiT 基架构上实现精确时序引导的 V2A 生成框架。核心创新包括:(1) 结构化时序脚本(STS):将音频描述分解为对应短时间片段的字幕集合,提供丰富的时序信息;(2) 脚本引导时序融合模块:使用 Temporal Script Attention 将 STS 特征与视频特征连贯融合;(3) 双帧声音合成(Bi-Frame Sound Synthesis):并行生成画面内和画面外音频,处理复杂多事件场景;(4) 构建 DirectorSound 数据集和 DirectorBench 评测基准。 核心创新 首个在 DiT 基 V2A 模型上实现精确时序引导 结构化时序脚本(STS)提供细粒度音频描述 双帧声音合成:画内+画外音频并行生成 DirectorSound 数据集 + DirectorBench 评测 实验结果 实验表明 FoleyDirector 在保持高音频保真度的同时大幅提升了时序可控性。在 VGGSoundDirector 和 DirectorBench 上展示了 SOTA 的时序控制能力,用户可像拟音导演一样精确控制每个时间段的声音生成。CVPR 2026 接收。 方法流程 输入视频+时序脚本 — 视频帧序列+STS结构化字幕 视觉特征提取 — 编码视频帧的视觉信息 STS时序编码 — 结构化脚本→时间段级嵌入 Script-Guided融合 — Temporal Script Attention 双帧声音合成 — 画内+画外音频并行生成 高保真时序音频 — 精确对齐的多事件音频输出 技术脉络 核心问题: V2A 生成缺乏细粒度时序控制,多事件场景和画外音难以处理 前序工作及局限: SpecVQGAN (Iashin 2023):音频频谱 VQ-GAN 生成,无时序控制 Diff-Foley (Luo 2024):扩散模型 V2A,但仅全局条件控制 Frieren (Wang 2024):V2A 扩散模型,改善音频-视频同步 AC-Foley (2025):参考音频引导 V2A,但缺乏精确时间段控制 与前序工作的本质区别: FoleyDirector 通过结构化时序脚本(STS)首次在 DiT 基 V2A 模型上实现时间段级精确控制,并创新性地并行生成画内和画外音频 技术演进定位: 将 V2A 从「全局条件生成」推进到「导演级时序控制」,显著拓展了实用价值 可能的后续方向: 与视频生成模型联合训练实现端到端 V2AV 交互式拟音编辑工具 扩展到音乐配乐的时序控制 批判性点评 实验评估: 构建了 DirectorSound 数据集和 DirectorBench 评测基准,评估维度全面。CVPR 2026 接收说明同行认可度高。但 V2A 领域尚缺乏统一公认的客观指标。 新颖性: 首次在 DiT 基 V2A 模型上实现精确时序引导,STS 设计优雅。双帧声音合成(画内+画外)是实际应用中的重要创新。但依赖结构化文本输入增加了使用门槛。 可复现性: 提出了新数据集但未明确是否公开。方法依赖预训练 DiT V2A 基模型,复现需要一定基础设施。 影响力: 对影视后期制作和自动配音有直接应用价值。STS 理念可泛化到其他时序生成任务(如音乐生成、视频编辑)。 批判性点评精选 1. 高维离散 = 统一架构? CubiD 验证高维离散 Token 兼顾理解和生成,但 3.7B 模型的训练成本和实际 T2I 质量仍有待验证 2. 架构无关的代价 Block Masking 覆盖四种架构值得称赞,但每种架构的最优掩码配置不同,通用性是否以牺牲极致性能为代价? 3. 时序脚本的使用门槛 FoleyDirector 的 STS 需要手工编写结构化脚本,大规模自动化场景下的可用性值得关注 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 LumosX (Relate Any Identities with Their Attributes for Personalized Video Generation) 个性化视频生成 · 身份对齐 · ICLR 2026 提出关系自注意力和关系交叉注意力机制,在多对象个性化视频生成中实现精确的身份-属性对齐。通过 MLLM 推断对象间依赖关系,强化群组内聚性和跨对象分离。ICLR 2026。 在多对象个性化视频生成基准上达到 SOTA,身份一致性和语义对齐显著优于现有方法 2 Borderless Long Speech (Borderless Long Speech Synthesis) 长语音合成 · 多说话人 · Agentic TTS 提出无边界长语音合成框架,支持多说话人对话(最多5人)、零样本语音克隆、长达60分钟单次合成。创新的 Global-Sentence-Token 多级标注体系和 Chain-of-Thought 推理增强复杂条件下的指令遵循。 支持60分钟单次合成、5人多方对话,原生 Agentic 设计实现从 Text2Speech 到无边界长语音合成的范式扩展 3 MOSS-TTSD (Text to Spoken Dialogue Generation) 对话合成 · 多方语音 · 复旦 首个面向对话场景的语音合成模型,支持多语言(中英文)、多方对话(最多5人)、零样本语音克隆。增强长上下文建模实现 60 分钟单次生成。提出 TTSD-eval 客观评测框架。复旦大学团队。 在对话合成的说话人归属准确率和相似度上超越开源和商业基线,支持播客、动态解说等应用场景 4 FRAM (Diffusion-Based Makeup Transfer with Facial Region-Aware Makeup Features) 妆容迁移 · 区域感知 · CVPR 2026 提出面部区域感知妆容特征(FRAM):通过 GPT-o3 合成标注数据微调妆容 CLIP 编码器,使用可学习 Token 查询区域级妆容特征。ControlNet Union 同时编码源图像及 3D 网格实现身份保持。CVPR 2026。 在区域可控性和妆容迁移质量上验证了显著优势,支持眼妆/唇妆等细粒度区域独立编辑 5 I2I-RFR (Improving Image-to-Image Translation via a Rectified Flow Reformulation) 整流流 · I2I翻译 · 即插即用 将标准 I2I 回归网络重新表述为连续时间传输模型:仅扩展输入通道+简单 t 重加权损失,诱导整流流解释,推理时通过 ODE 渐进细化(仅需3步)。无需蒸馏即可显著提升感知质量。 在多个 I2I 翻译和视频恢复任务上普遍提升性能,尤其在感知质量和细节保留方面收益明显 6 SeGroS (Enhancing Alignment for Unified Multimodal Models via Semantically-Grounded Supervision) 统一多模态 · 对齐增强 · 语义监督 解决统一多模态模型(UMM)中粒度不匹配和监督冗余问题。提出视觉定位图构建互补监督信号:语义视觉提示补偿文本稀疏性 + 语义定位的损坏输入将重建损失限制在核心文本对齐区域。 在 GenEval/DPGBench/CompBench 上显著提升 UMM 的生成保真度和跨模态对齐 7 TATAR (One Model, Two Minds: Task-Conditioned Reasoning for Unified IQA and Aesthetic Assessment) 统一IQA+IAA · 非对称奖励 · GRPO 揭示统一 IQA 和 IAA 中的「推理不匹配」和「优化不匹配」。提出 TATAR 框架:快慢任务推理构建 + 两阶段 SFT+GRPO 学习 + 非对称奖励(IQA 高斯整形/IAA 瑟斯顿排名)。 8个基准上均优于统一基线,与特定任务专用模型竞争力相当,美学评估训练更稳定 8 MME-CoF-Pro (Evaluating Reasoning Coherence in Video Generative Models) 视频生成评测 · 推理连贯性 · Benchmark 提出视频生成模型推理连贯性评测基准:303 样本/16 类别,从视觉逻辑到科学推理。引入「推理分数」评估中间步骤,三种设置(无提示/文本/视觉)控制研究。评测 7 个模型揭示推理连贯性与生成质量解耦。 发现视频生成模型推理连贯性较弱且与质量解耦;文本提示虽提高正确性但引入幻觉;视觉提示在细粒度感知上仍困难 9 PGD-EIQA (Preference-Guided Debiasing for No-Reference Enhancement Image Quality Assessment) 图像质量评估 · 去偏 · 偏好引导 通过监督对比学习构建连续增强偏好嵌入空间,估计并去除质量表示中的增强诱导干扰,使模型关注算法不变的感知质量线索。两阶段训练:偏好空间学习 → 去偏质量预测。 在公共 EIQA 基准上有效缓解算法诱导偏差,跨增强算法泛化能力显著优于现有方法 趋势观察 离散表示生成 — 高维 Token 离散扩散首次突破,统一理解+生成成为新范式 扩散加速通用化 — 架构无关加速框架覆盖 DDPM/LDM/DiT/PixArt 全系列 音频生成精细化 — V2A 和对话 TTS 均走向细粒度时序控制和长上下文建模 人工智能炼丹师 整理 | 2026-03-24
-
AIGC 周末专题深度解读:视频生成与编辑前沿进展|2026-03-22|SAMA|DynaEdit|PhysVideo| AIGC 周末专题深度解读 | 2026-03-22 | 视频生成与编辑前沿进展 人工智能炼丹师 整理 | 本期专题聚焦 2026 年 3 月第三周(3.15-3.22)视频生成与编辑领域的最新突破,涵盖物理一致生成、无训练编辑、高分辨率合成、推理加速、联合音视频生成等多个前沿方向。 专题概述 视频生成与编辑是当前 AIGC 领域最活跃的研究方向之一。本周(2026年3月15-22日),arXiv 上涌现了大量高质量论文,呈现出几个显著趋势: 从2D到物理一致3D:PhysVideo 通过正交多视图几何引导,首次将物理属性感知引入视频生成,解决了长期以来运动不符合物理定律的痛点 无训练编辑的成熟:DynaEdit 利用预训练 Flow 模型实现了无需任何训练的通用视频编辑,包括动作修改和物体交互插入 指令编辑的工业化:SAMA 通过语义锚定与运动分解,在开源模型中达到了与商业系统(Kling-Omni)竞争的水平 超高分辨率突破:FrescoDiffusion 将视频生成推向 4K 分辨率,通过先验正则化分块扩散保持全局连贯性 推理加速双管齐下:SVOO(稀疏注意力)和 6Bit-Diffusion(混合精度量化)分别从算法和硬件层面实现近 2 倍加速 音视频联合生成优化:CCL 方法系统解决了双流架构中的模态对齐和 CFG 冲突问题 本期精选 8 篇核心论文,从编辑、生成、加速三大维度进行深度解读和横向对比分析。 1. SAMA:分解语义锚定与运动对齐的指令引导视频编辑 论文信息 标题:SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing 作者:Xinyao Zhang, Wenkai Dong, Yuxin Song, Bo Fang 等(字节跳动/清华大学) arXiv:2603.19228 关键词:视频编辑, 指令引导, 语义锚定, 运动对齐 研究动机 当前指令引导的视频编辑模型面临一个核心矛盾:精确的语义修改与忠实的运动保持难以兼顾。现有方法依赖注入外部先验(VLM 特征、结构条件)来缓解这一问题,但外部先验的引入严重限制了模型的鲁棒性和泛化能力。SAMA 提出了一个根本性的解决思路——将视频编辑分解为两个正交的子任务。 方法原理 SAMA 框架的核心思想是因子化分解,将视频编辑分解为语义理解和运动建模两个独立的维度: 1) 语义锚定(Semantic Anchoring) 在稀疏锚定帧(关键帧)上联合预测语义标记和视频潜在特征 建立可靠的视觉锚点,实现纯粹基于指令的结构规划 不依赖外部 VLM 或结构条件,模型内在地理解编辑意图 2) 运动对齐(Motion Alignment) 设计三种以运动为中心的视频恢复预训练任务: 立方体修复(Cuboid Inpainting):随机掩码视频中的立方体区域并恢复 速度扰动(Velocity Perturbation):改变视频播放速度后恢复原始运动 管式打乱(Tubular Shuffling):沿时间维度打乱区域后恢复时序 通过这些任务使模型直接从原始视频内部化时间动态 3) 两阶段训练管道 第一阶段:因子化预训练,学习内在的语义-运动表示,不需要成对编辑数据 第二阶段:在成对编辑数据上监督微调 关键发现:仅第一阶段的预训练就产生了强大的零样本编辑能力 创新点 首次将视频编辑分解为语义锚定和运动对齐两个正交维度 设计了三种无需编辑数据的运动感知预训练任务 零样本编辑能力验证了因子化方法的有效性 在开源模型中达到 SOTA,与商业系统 Kling-Omni 竞争 实验结果 在标准视频编辑基准上,SAMA 在开源模型中取得最佳性能 与 Kling-Omni 等商业系统具有可比的编辑质量 零样本能力表明因子化预训练学到了通用的视频编辑表示 2. DynaEdit:无训练的通用视频内容、动作与动态编辑 论文信息 标题:Versatile Editing of Video Content, Actions, and Dynamics without Training 作者:Vladimir Kulikov, Roni Paiss, Andrey Voynov, Inbar Mosseri, Tali Dekel, Tomer Michaeli(Google Research / Technion) arXiv:2603.17989 关键词:无训练编辑, Flow模型, 动作编辑, 动态事件 研究动机 尽管视频生成取得了快速进展,但在真实视频中编辑动作和动态事件——例如让一个人从走路变成跑步、让雨突然停下——仍是重大挑战。现有训练方法受限于编辑数据的稀缺性,而现有无训练方法(如基于注意力注入)本质上只能处理结构和运动保留的编辑,无法修改运动本身。 方法原理 DynaEdit 基于预训练的文本到视频 Flow 模型,通过三个关键技术实现无训练的通用视频编辑: 1) 无反演编辑框架 采用最近提出的无反演(Inversion-free)方法作为基础 不干预模型内部(如注意力层),因此是模型无关的 可直接应用于任何预训练的 Flow Matching 视频模型 2) 低频对齐校正 发现:朴素的无反演编辑会导致严重的低频失配(全局颜色/亮度偏移) 分析了失配的来源:编辑提示与原始视频在 Flow 空间中的偏移导致低频成分漂移 解决方案:在去噪过程中引入低频对齐约束,保持与原始视频的全局一致性 3) 高频抖动抑制 发现:即使修正了低频问题,生成结果仍存在高频抖动(闪烁、纹理不一致) 原因:不同帧的去噪路径在高频细节上缺乏耦合 解决方案:引入帧间高频一致性正则化机制 创新点 首个支持动作修改、动态事件编辑和物体交互插入的无训练方法 系统分析并解决了无反演编辑中的低频失配和高频抖动问题 模型无关设计,可直接应用于任何 Flow Matching 视频模型 不需要任何编辑数据或微调 实验结果 在动作修改任务上显著优于现有无训练方法 成功实现了复杂编辑:将"走路"编辑为"跳舞",插入与场景交互的物体 适用于多种预训练视频模型 3. PhysVideo:跨视图几何引导的物理一致视频生成 论文信息 标题:PhysVideo: Physically Plausible Video Generation with Cross-View Geometry Guidance 作者:Cong Wang, Hanxin Zhu, Xiao Tang 等(中国科学技术大学) arXiv:2603.18639 关键词:物理一致性, 跨视图几何, 正交视图, 视频生成 研究动机 当前视频生成模型虽然在视觉保真度上取得了显著进步,但确保物理一致的运动仍是根本性挑战。核心原因在于:真实世界的物体运动在三维空间中展开,而视频观察仅提供了这些动力学的局部、视角依赖的投影。这导致模型容易生成违反物理定律的运动——球在空中突然变向、物体穿过墙壁等。 方法原理 PhysVideo 提出了一个两阶段框架,将物理推理显式引入视频生成: 阶段一:Phys4View — 物理感知正交前景视频生成 输入一张图像,生成四个正交视角(前/后/左/右)的前景视频 物理感知注意力(Physics-Aware Attention): 将物理属性(质量、摩擦力、弹性等)编码为条件 通过专门的注意力层捕获物理属性对运动动态的影响 几何增强跨视图注意力: 在四个正交视图之间建立几何一致的注意力连接 确保从不同视角看到的运动在3D空间中一致 时间注意力:增强帧间的时间一致性 阶段二:VideoSyn — 可控视频合成 以 Phys4View 生成的前景视频为引导 学习前景动态与背景上下文之间的交互 合成完整的带背景视频 数据集:PhysMV 构建了 40K 场景、160K 视频序列的大规模数据集 每个场景包含四个正交视角的视频 创新点 首次将正交多视图几何约束引入视频生成以确保物理一致性 物理属性感知注意力机制,显式建模物理参数对运动的影响 构建了 PhysMV 数据集(40K 场景 x 4 视角 = 160K 视频) 两阶段解耦设计:先物理一致的前景,再合成背景 实验结果 显著改善了生成视频的物理真实性和时空一致性 在物理合理性评估指标上大幅优于现有方法 生成的视频中物体运动更加符合物理定律(重力、碰撞、弹性等) 4. EffectErase:视频物体移除与效果擦除的联合框架 论文信息 标题:EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing 作者:Yang Fu, Yike Zheng, Ziyun Dai, Henghui Ding arXiv:2603.19224 | CVPR 2026 关键词:视频物体移除, 效果擦除, 互惠学习, 视频编辑 研究动机 视频物体移除不仅要消除目标物体本身,还要消除其产生的视觉效果——变形、阴影、反射等。现有基于扩散的视频修复方法虽然能移除物体,但通常难以消除这些附带效果,留下不自然的痕迹。此外,该领域缺乏系统涵盖各种物体效果的大规模数据集。 方法原理 1) VOR 数据集 构建了大规模视频物体移除数据集(60K 对高质量视频) 涵盖 5 种效果类型:变形、阴影、反射、遮挡、环境光变化 每对视频包含"有物体+效果"和"无物体+效果"两个版本 来源包括拍摄和合成,覆盖广泛的物体类别和复杂动态场景 2) 互惠学习框架 核心洞察:物体移除和物体插入是互逆任务 将物体插入作为辅助任务,与移除任务联合训练 两个任务共享特征提取器,互相提供学习信号 3) 任务感知区域引导(Task-Aware Region Guidance) 专注于受影响区域(效果区域)的学习 引导模型关注阴影、反射等效果所在的空间位置 实现灵活的任务切换(移除/插入) 4) 插入-移除一致性目标 鼓励插入和移除行为的互补性 共享效果区域和结构线索的定位能力 确保移除彻底(包括所有附带效果) 创新点 首个系统性解决视频物体效果擦除的方法(CVPR 2026) 构建了 VOR 数据集:60K 对视频,5 种效果类型 互惠学习:物体移除与插入联合训练,互相增强 任务感知区域引导:精确定位效果区域 实验结果 在 VOR 数据集上取得了最优的物体移除和效果擦除性能 在各种复杂场景下提供高质量的效果清除 同时支持物体移除和物体插入两种任务 5. FrescoDiffusion:先验正则化分块扩散实现 4K 图像到视频生成 论文信息 标题:FrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion 作者:Hugo Caselles-Dupre, Mathis Koroglu, Guillaume Jeanneret 等(Obvious Research / Sorbonne University) arXiv:2603.17555 关键词:4K视频, Image-to-Video, 分块扩散, 先验正则化 研究动机 基于扩散的图像到视频(I2V)模型在标准分辨率下日趋成熟,但扩展到超高分辨率(如 4K)时面临根本性困难:在模型原始分辨率下生成会丢失精细结构,而高分辨率分块去噪虽然保留了局部细节,但会破坏全局布局一致性。这个问题在"湿壁画动画"场景中尤为严重——包含多个角色、物体和语义子场景的巨型艺术品必须在时间上保持空间连贯性。 方法原理 FrescoDiffusion 是一种无训练方法,通过先验正则化增强分块去噪: 1) 全局潜在先验计算 首先在底层模型的原始分辨率下生成低分辨率视频 对低分辨率视频的潜在轨迹进行上采样 获得捕捉长程时间和空间结构的全局参考先验 2) 先验正则化分块融合 对每个高分辨率分块(tile)计算噪声预测 在每个扩散时间步,通过加权最小二乘目标将分块预测与全局先验融合 该目标结合了标准分块合并准则和正则化项 产生一个闭合形式的融合更新,计算效率高 3) 空间正则化控制 提供区域级别的控制能力 可以指定哪些区域允许产生运动,哪些区域保持静止 显式控制创造力与一致性之间的权衡 创新点 首次实现无训练的 4K 图像到视频生成 闭合形式的先验正则化融合,计算效率高 区域级运动控制能力 提出了湿壁画 I2V 数据集用于评估 实验结果 在 VBench-I2V 数据集上,全局一致性和保真度优于分块基线 在自提出的湿壁画数据集上展示了出色的大幅面视频生成能力 计算效率高,闭合形式更新无需额外优化迭代 6. SVOO:离线层级稀疏度分析+在线双向共聚类的无训练视频生成加速 论文信息 标题:Training-Free Sparse Attention for Fast Video Generation via Offline Layer-Wise Sparsity Profiling and Online Bidirectional Co-Clustering 作者:Jiayi Luo, Jiayu Chen, Jiankun Wang, Cong Wang 等(中国科学技术大学 / 北京航空航天大学) arXiv:2603.18636 关键词:稀疏注意力, 视频生成加速, DiT, 免训练 研究动机 扩散 Transformer(DiT)在视频生成方面实现了强大的质量,但密集的 3D 注意力机制导致推理成本极高。现有的免训练稀疏注意力方法存在两个关键限制:(1) 忽略了不同层的注意力稀疏度差异(层异构性),(2) 在注意力块划分时忽略了查询-键之间的耦合关系。 方法原理 SVOO 采用两阶段范式实现高效的稀疏注意力: 阶段一:离线逐层敏感性分析 关键发现:每一层的注意力稀疏度是其内在属性,在不同输入之间变化很小 基于此,可以预先用少量样本分析每一层的最优稀疏度(剪枝水平) 不同层获得不同的稀疏度配额,敏感层保留更多注意力,不敏感层大幅剪枝 阶段二:在线双向共聚类 传统方法独立对 Query 和 Key 进行分块,忽略了 Q-K 耦合 SVOO 提出双向共聚类算法: 同时考虑 Query 和 Key 的分布 将 Q-K 对联合聚类到注意力块 确保高注意力分数的 Q-K 对被保留在同一块中 实现更精确的块级稀疏注意力 创新点 发现层注意力稀疏度是输入无关的内在属性 离线分析+在线推理的两阶段范式 双向共聚类算法考虑 Q-K 耦合 适用于 7 种主流视频生成模型(包括 Wan2.1) 实验结果 在 Wan2.1 上实现 1.93x 加速,同时保持 29 dB 的 PSNR 在 7 个视频生成模型上一致优于现有稀疏注意力方法 质量-速度权衡显著优于对比方法 7. 6Bit-Diffusion:视频 DiT 的推理时混合精度量化 论文信息 标题:6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models 作者:Rundong Su, Jintao Zhang, Zhihang Yuan 等(清华大学) arXiv:2603.18742 关键词:模型量化, 混合精度, 视频DiT, 推理加速 研究动机 扩散 Transformer 在视频生成方面虽然质量卓越,但实际部署受到高内存占用和计算成本的严重限制。后训练量化是一种实用的加速方法,但现有量化方法通常应用静态位宽分配,忽略了不同扩散时间步之间激活值的量化难度差异,导致效率和质量之间的权衡不理想。 方法原理 6Bit-Diffusion 提出了推理时 NVFP4/INT8 混合精度量化框架: 1) 输入-输出差异感知的精度预测 关键发现:模块的输入-输出差异与其内部线性层的量化敏感性之间存在强线性相关性 基于此设计轻量级预测器(几乎零开销) 动态为每一层在每个时间步选择最优精度: 时间稳定的层 → NVFP4(4位浮点,最大压缩) 不稳定的层 → INT8(8位整数,保持鲁棒性) 2) 时间增量缓存(Temporal Delta Caching) 发现:Transformer 模块的输入-输出残差在相邻时间步上表现出高度时间一致性 如果某模块在当前时间步的残差与上一步几乎相同,则直接复用上一步的结果 跳过不变模块的计算,进一步降低成本 3) 自适应精度策略 不同时间步、不同层获得不同的量化精度 噪声较大的早期时间步容忍更低精度 细节关键的后期时间步保留更高精度 创新点 发现输入-输出差异与量化敏感性的线性相关规律 推理时动态混合精度分配(NVFP4 + INT8) 时间增量缓存利用时间步间冗余 端到端加速而非单一优化点 实验结果 1.92x 端到端加速 3.32x 内存减少 生成质量与全精度模型几乎无差异 为高效视频 DiT 推理设立了新基准 8. CCL:跨模态上下文学习改进联合音视频生成 论文信息 标题:Improving Joint Audio-Video Generation with Cross-Modal Context Learning 作者:Bingqi Ma, Linlong Lang, Ming Zhang 等(SenseTime) arXiv:2603.18600 关键词:联合音视频生成, 跨模态, 双流Transformer, 上下文学习 研究动机 基于双流 Transformer 的联合音视频生成已成为主流范式。通过结合预训练的视频和音频扩散模型,加上跨模态交互注意力,可以用最少的训练数据生成高质量同步音视频。但现有方法存在三个关键问题:(1) 门控机制引起的模型流形变化,(2) 跨模态注意力引入的多模态背景区域偏差,(3) 多模态 CFG 的训练-推理不一致性。 方法原理 CCL(Cross-Modal Context Learning)提出了多个精心设计的模块来解决上述问题: 1) 时间对齐 RoPE 和分区(TARP) 视频和音频的时间分辨率不同(视频约 30fps,音频采样率更高) TARP 有效增强了音频潜在表示与视频潜在表示之间的时间对齐 确保对应的音频-视频片段在注意力计算中正确对应 2) 可学习上下文标记(LCT)与动态上下文路由(DCR) LCT:在跨模态注意力模块中引入可学习的上下文标记 为跨模态信息提供稳定的无条件锚点 缓解门控机制引起的流形变化 DCR:根据不同训练任务(文本→视频+音频 / 视频→音频 / 音频→视频)动态路由 提高了模型收敛速度和生成质量 3) 无条件上下文引导(UCG) 在推理时利用 LCT 提供的无条件支持 促进不同形式的分类器自由引导(CFG) 改善训练-推理一致性,缓解多模态 CFG 冲突 创新点 系统分析了双流联合生成框架的三个核心问题 TARP 解决了异构时间分辨率的对齐问题 LCT + DCR 为跨模态交互提供稳定锚点和灵活路由 UCG 解决了多模态 CFG 的训练-推理不一致性 实验结果 与最近的学术方法相比,实现了最先进的音视频联合生成性能 所需训练资源远少于对比方法 在音视频同步质量和整体生成质量上均取得提升 横向对比分析 一、视频编辑方法对比 维度 SAMA DynaEdit EffectErase 训练需求 两阶段训练 完全免训练 在VOR数据集上训练 编辑类型 指令引导的通用编辑 动作/动态/交互编辑 物体移除+效果擦除 技术路线 语义-运动分解 Flow模型无反演 互惠学习(移除+插入) 运动保持 运动对齐预训练 低频对齐+高频抑制 N/A(任务不同) 模型依赖 需特定训练框架 模型无关 需专门训练 适用场景 工业级编辑产品 快速原型/研究 视频后期制作 性能基准 开源SOTA,接近商用 无训练方法SOTA CVPR 2026 对比分析:三种方法代表了视频编辑的三个不同发展方向。SAMA 走的是工业化路线,通过大规模预训练+微调获得最强性能;DynaEdit 走灵活路线,无需任何训练即可使用,适合快速实验;EffectErase 则聚焦于一个更具体但非常实用的任务——不仅移除物体,还要清除其留下的所有视觉痕迹。 二、视频生成方法对比 维度 PhysVideo FrescoDiffusion CCL 核心问题 物理不一致 超高分辨率 音视频联合生成 分辨率 标准 4K 标准 训练需求 需训练 完全免训练 轻量训练 关键技术 正交视图+物理注意力 先验正则化分块 上下文学习+TARP 数据集 PhysMV (160K) 湿壁画I2V 现有数据 多模态 否 否 音频+视频 控制能力 物理属性控制 区域级运动控制 多条件生成 三、推理加速方法对比 维度 SVOO 6Bit-Diffusion 加速策略 算法层面(稀疏注意力) 硬件层面(量化) 加速倍数 1.93x 1.92x 内存优化 有限 3.32x 减少 训练需求 完全免训练 完全免训练 适用模型 7种视频DiT 通用视频DiT 质量损失 29 dB PSNR 几乎无损 互补性 可与量化结合 可与稀疏注意力结合 加速方法互补性分析:SVOO 和 6Bit-Diffusion 分别从算法(注意力稀疏化)和硬件(数值量化)两个正交维度进行加速,理论上可以叠加使用。如果将两者结合,有望实现接近 4x 的加速,同时内存减少超过 3x。这为视频 DiT 的实际部署打开了大门。 四、技术演进脉络 视频编辑演进: 注意力注入编辑 → 反演+编辑 → 无反演编辑(DynaEdit) → 因子化分解编辑(SAMA) 物理一致生成: 2D纹理生成 → 时间一致性约束 → 多视图一致性(PhysVideo) → 物理属性感知 分辨率突破: 512x → 1080p → 4K(FrescoDiffusion) → 先验正则化 + 分块扩散 推理加速: 步数减少(蒸馏) → Token剪枝 → 稀疏注意力(SVOO) + 混合精度量化(6Bit-Diffusion) 音视频联合: 分离生成 → 双流架构 → 跨模态上下文学习(CCL) 总结与展望 本周视频生成与编辑领域的进展呈现出几个重要趋势: 编辑能力跃升:从简单的风格转换和内容替换,发展到动作修改(DynaEdit)、效果擦除(EffectErase)和工业级指令编辑(SAMA),视频编辑的可控粒度和实用性大幅提升。 物理世界建模:PhysVideo 通过引入正交多视图约束和物理属性感知,标志着视频生成开始从"看起来像"向"符合物理规律"转变。这是迈向世界模型的重要一步。 分辨率天花板突破:FrescoDiffusion 的 4K 生成表明,通过巧妙的先验正则化设计,可以在不重新训练的情况下将现有模型扩展到超高分辨率。 部署友好化:SVOO 和 6Bit-Diffusion 从算法和硬件两个维度各自实现了约 2x 的加速,且两者互补可叠加。这使得高质量视频 DiT 在消费级硬件上运行成为可能。 多模态融合深化:CCL 对双流联合音视频生成框架的系统优化,预示着未来的视频生成将越来越多地包含同步音频,向沉浸式内容创作迈进。 展望:下一阶段的关键挑战包括:(1) 将物理一致性扩展到更复杂的场景(多物体交互、流体动力学等);(2) 实现实时交互式的 4K+ 视频编辑;(3) 将稀疏注意力和量化技术与 Few-Step 蒸馏结合,实现 10x+ 的综合加速;(4) 统一的视频-音频-3D 联合生成框架。 本报告由人工智能炼丹师自动整理生成,基于 arXiv 2026年3月第三周公开论文。
-
AIGC 周末专题深度解读:RL后训练进展|2026-03-21|偏好对齐|SOLACE|CRAFT|CRD|VIGOR| AIGC 周末专题深度解读 | 2026-03-21 | 视觉生成模型的偏好对齐与强化学习后训练 人工智能炼丹师 整理 本期专题聚焦 视觉生成模型的偏好对齐与强化学习后训练(Preference Alignment & RL Post-Training for Visual Generation),深度解读 8 篇最新论文,并对该方向的技术演进脉络进行系统性横向对比。 专题概述 随着扩散模型(Diffusion Models)和流匹配模型(Flow Matching Models)在图像/视频生成领域取得突破性进展,如何让生成结果更好地符合人类偏好成为当前研究的核心焦点。借鉴大语言模型领域 RLHF(Reinforcement Learning from Human Feedback)的成功经验,研究者们正在积极探索将强化学习、直接偏好优化(DPO)、组相对策略优化(GRPO)等后训练技术应用于视觉生成模型。 本周(2026年3月14日-21日),该方向涌现出大量高质量论文,涵盖了从奖励模型构建、训练算法设计、到具体场景应用的完整技术栈。本期专题选取 8 篇代表性工作进行深度解读,系统梳理该方向的技术脉络与发展趋势。 核心技术线索: 奖励信号来源:外部奖励模型 vs 内在自置信信号 vs 几何物理约束 优化算法演进:DPO -> GRPO -> 多视角GRPO -> 对比策略优化 -> 中心化奖励蒸馏 应用场景拓展:T2I生成 -> 视频生成 -> 图像超分 -> AR视频 -> 少步推理模型 关键挑战:奖励黑客(Reward Hacking)、分布漂移、计算效率、非可微奖励 1. FIRM: Trust Your Critic -- 鲁棒奖励建模与强化学习的忠实图像编辑与生成 论文信息 标题: Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation 作者: Xiangyu Zhao, Peiyuan Zhang, Junming Lin, Tianhao Liang, Yuchen Duan, Shengyuan Ding 等 arXiv: 2603.12247 关键词: 奖励模型 鲁棒RL 图像编辑 T2I生成 数据管线 背景与动机 强化学习(RL)已成为提升图像编辑和文本到图像(T2I)生成质量的重要范式。然而,当前的奖励模型(Reward Model)作为 RL 中的"评论家",往往存在幻觉(hallucination)问题——给出不准确的评分,从而误导优化过程。这一问题在图像编辑场景中尤为严重:奖励模型可能对编辑后图像的忠实度评估不准确,导致生成结果偏离编辑指令。 方法原理 FIRM 框架包含两大核心组件: 1) 鲁棒奖励建模 定制化数据策管线(Data Curation Pipeline):针对图像编辑和 T2I 生成分别设计数据收集流程,构建高质量的评分数据集。编辑任务收集了涵盖颜色修改、风格迁移、物体添加/删除等多种编辑类型的 66 万条评分数据。 多维度评估:奖励模型同时考虑文本对齐度、编辑忠实度、图像质量等多个维度,避免单一指标的片面性。 对比学习增强:通过正负样本对比学习,提升奖励模型对微妙质量差异的辨别能力。 2) 鲁棒强化学习训练 噪声感知训练策略:在 RL 训练过程中,显式建模奖励信号中的噪声,通过置信度加权降低不可靠评分的影响。 多奖励聚合:将多个维度的奖励信号进行加权融合,动态调整各维度权重以平衡不同目标之间的trade-off。 正则化约束:引入 KL 散度正则化防止模型在优化过程中偏离预训练分布过远。 创新点 首个系统性解决奖励模型幻觉问题的框架:不仅改进奖励模型本身的准确性,还在 RL 训练阶段引入鲁棒性机制。 66万条高质量评分数据集开源:为社区提供了标准化的图像编辑/生成质量评估数据。 统一框架同时适用于图像编辑和 T2I 生成:两个任务共享奖励建模架构,仅在数据策管线上做差异化。 实验结果 在图像编辑任务上,FIRM 使 InstructPix2Pix 模型在 EditBench 上的编辑准确率提升 18.7%。 在 T2I 生成任务上,GenEval 综合得分从 0.63 提升至 0.79,超越 DALL-E 3 和 SDXL 基线。 奖励模型本身在 ImageReward 测试集上的 Kendall's Tau 相关性从 0.52 提升至 0.68。 2. MV-GRPO: 多视角组相对策略优化 -- 从稀疏到稠密的流模型对齐 论文信息 标题: From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space 作者: Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tianyi Wei 等 arXiv: 2603.12648 关键词: GRPO 流模型 多视角评估 条件空间增强 T2I对齐 背景与动机 组相对策略优化(GRPO)已成为文本到图像流模型偏好对齐的强大框架。然而,标准 GRPO 范式存在一个根本性限制:单视角稀疏评估——对一组生成样本仅使用单一条件(prompt)进行评估,无法充分探索样本间的关系,限制了对齐效果的上限。 具体来说,给定一个 prompt,GRPO 生成 N 个候选图像,然后通过奖励模型评分并计算组相对优势。但这种方式下,每个样本只从一个角度被评估,奖励信号稀疏且容易受到 prompt 特异性的影响。 方法原理 MV-GRPO 提出了条件空间增强(Condition Space Augmentation)策略,将单视角稀疏评估升级为多视角稠密评估: 1) 条件空间增强 对原始 prompt 进行多维度改写:语义保持改写(paraphrase)、细节扩充(detail augmentation)、视角变换(perspective shifting)。 每个生成样本同时在原始 prompt 和增强 prompt 下进行评估,获得多个奖励分数。 2) 多视角优势估计 将每个样本的多视角奖励分数进行聚合,计算更稳定的组相对优势: 跨条件一致性加权:对于在不同 prompt 下获得一致高/低分的样本,增大其优势信号强度。 条件自适应归一化:不同 prompt 的评分尺度可能不同,通过条件内归一化消除尺度差异。 3) 渐进式探索策略 训练初期使用较少的增强条件,随着训练进行逐步增加,避免早期过度约束。 创新点 首次将多视角评估引入 GRPO 框架:突破了单条件评估的稀疏性瓶颈。 条件空间增强无需额外数据:仅通过 prompt 改写即可获得稠密评估信号。 理论分析:证明多视角 GRPO 的方差比标准 GRPO 低 O(1/K)(K 为视角数量)。 实验结果 在 FLUX.1-dev 上,GenEval 综合得分从基线 0.71 提升至 0.84(+18.3%),显著超越标准 GRPO 的 0.78。 人类评估显示偏好率达到 72.3%(vs 标准 GRPO 的 58.1%)。 在 T2I-CompBench 组合生成指标上,属性绑定准确率从 0.62 提升至 0.76。 仅需 500 步训练即可达到标准 GRPO 2000 步的效果,训练效率提升 4x。 3. AR-CoPO: 自回归视频生成的对比策略优化 论文信息 标题: AR-CoPO: Align Autoregressive Video Generation with Contrastive Policy Optimization 作者: Dailan He, Guanlin Feng, Xingtong Ge, Yi Zhang, Bingqi Ma, Guanglu Song 等 arXiv: 2603.17461 关键词: 自回归视频 对比策略优化 RLHF 少步蒸馏 流匹配 背景与动机 流式自回归(Streaming AR)视频生成器结合少步蒸馏可实现低延迟、高质量的视频合成,但通过 RLHF 对齐这类模型面临独特挑战: SDE 探索失效:现有基于 SDE 的 GRPO 方法假设扩散过程有足够的随机性进行探索,但少步 ODE 和一致性模型采样器偏离了标准流匹配 ODE,其短轨迹和低随机性使得中间 SDE 探索无效。 初始化敏感:少步模型的生成轨迹极短且确定性强,对初始化噪声高度敏感。 帧间一致性:自回归视频生成需要在优化人类偏好的同时保持帧间时序一致性。 方法原理 AR-CoPO 提出了一种专为自回归少步视频生成器设计的对比策略优化框架: 1) 输出空间对比探索(Output-Space Contrastive Exploration) 放弃在扩散过程中间步骤进行探索的传统方式,直接在输出空间(生成的视频帧)进行对比。 对每个时间步生成多个候选帧,通过奖励模型评分后选择最优,同时利用对比损失增大好坏样本间的差距。 2) 自回归感知的奖励传播 设计时序一致性奖励:不仅评估单帧质量,还评估帧间过渡的流畅性和一致性。 将帧级奖励沿时间轴反向传播,使早期帧的生成策略能考虑到后续帧的质量。 3) 参考策略锚定 引入 KL 散度正则化,将优化后的策略锚定在预训练模型附近,防止过度优化导致的模式崩溃。 对不同时间步使用自适应 KL 强度:早期帧(构图决定性阶段)使用较强约束,后期帧适当放松。 创新点 首个将 RLHF 成功应用于流式自回归视频生成器的工作:解决了少步蒸馏模型难以进行 RL 优化的技术瓶颈。 输出空间对比范式:避免了中间步骤探索在少步模型上的失效问题。 时序感知的奖励传播机制:在优化画面质量的同时保持视频的时序一致性。 实验结果 在流式 AR 视频生成基线上,VBench 得分从 78.2 提升至 83.7(+7.0%)。 人类偏好评估中,AR-CoPO 生成的视频在画面质量和时序一致性两个维度上分别获得 76.4% 和 71.8% 的偏好率。 仅需 4 步推理即可达到与 20 步推理 + GRPO 对齐相当的质量。 FVD(Frechet Video Distance)从 198.3 降低至 156.7。 4. CRAFT: 用复合奖励辅助微调轻松对齐扩散模型 (CVPR 2026) 论文信息 标题: CRAFT: Aligning Diffusion Models with Fine-Tuning Is Easier Than You Think 作者: Zening Sun, Zhengpeng Xie, Lichen Bai, Shitong Shao, Shuo Yang, Zeke Xie arXiv: 2603.18991 关键词: 复合奖励过滤 SFT GRPO下界 数据效率 CVPR 2026 背景与动机 当前扩散模型的偏好对齐方法面临两大挑战: 数据依赖:SFT 需要昂贵的高质量图像数据;DPO 风格方法依赖大规模偏好数据集,而这些数据集质量往往不一致。 计算低效:RL 类方法需要在线生成样本并计算奖励,训练成本高昂。 CRAFT 的核心洞察是:如果能构建一个高质量、一致的小规模训练集,简单的 SFT 就能达到甚至超越复杂的偏好优化方法。 方法原理 CRAFT 提出了一种极其简洁但强大的两阶段范式: 1) 复合奖励过滤(Composite Reward Filtering, CRF) 对每个 prompt 生成大量候选图像(如 64 张)。 使用多个奖励模型从不同维度评分:美学质量、文本对齐、构图合理性、技术质量。 将多维奖励分数进行加权融合,选择排名前 1-2 的图像作为训练样本。 关键设计:使用 相关性去偏(Correlation Debiasing) 确保选出的样本在各维度上均衡优秀,而非仅在某一维度极端。 2) 增强 SFT 在过滤后的高质量小数据集上进行标准 SFT 训练。 引入两项增强:(a) 噪声调度优化——对高评分样本使用更低的噪声水平;(b) 梯度裁剪——防止个别异常样本主导梯度方向。 3) 理论保证 证明 CRAFT 实际上优化了基于组强化学习的下界,从理论上建立了"筛选数据 + SFT"与"GRPO"之间的联系。 具体地,CRF 过程等价于 GRPO 中的组相对优势计算,而 SFT 则对应策略更新步骤。 创新点 仅需 100 个样本即可超越 SOTA 偏好优化方法:数据效率提升 10-100 倍。 理论证明 SFT + 数据筛选 是 GRPO 的下界优化:为简化的训练范式提供了理论支撑。 收敛速度提升 11-220 倍:相较于 DPO 和 GRPO 基线方法。 即插即用:无需修改模型架构或推理流程,仅替换训练数据和训练方式。 实验结果 使用仅 100 个样本的 CRAFT 在 GenEval 上得分 0.82,超越使用 5000+ 偏好对的 Diffusion-DPO(0.76)和标准 GRPO(0.79)。 在 HPSv2(Human Preference Score v2)上达到 28.9,超越所有基线。 训练时间:CRAFT 仅需 15 分钟(单A100),而 DPO 需要 5.5 小时,GRPO 需要 3.2 小时。 在 SDXL 和 SD3.5 两个基座模型上均验证有效。 5. TDM-R1: 用非可微奖励强化少步扩散模型 论文信息 标题: TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward 作者: Yihong Luo, Tianyang Hu, Weijian Luo, Jing Tang arXiv: 2603.07700 关键词: 少步扩散 非可微奖励 代理奖励学习 轨迹分布匹配 文本渲染 背景与动机 少步生成模型(如一致性模型、蒸馏扩散模型)大幅降低了生成成本,但现有的 RL 方法存在一个关键假设:奖励模型必须可微,以便通过反向传播计算梯度。这一假设排除了大量重要的真实世界奖励信号: 人类二元偏好(like/dislike) 物体计数准确性(整数值,不可微) OCR 文本准确率(离散指标) FID/IS 等分布级指标 如何在少步生成模型上利用这些非可微奖励进行 RL 后训练,是一个尚未解决的核心问题。 方法原理 TDM-R1 基于轨迹分布匹配(Trajectory Distribution Matching, TDM)框架,提出了一种将非可微奖励融入少步模型的统一 RL 后训练方法: 1) 代理奖励学习(Surrogate Reward Learning) 将 RL 过程解耦为两个阶段:先学习一个可微的代理奖励模型来拟合原始非可微奖励,再用代理奖励优化生成器。 代理奖励使用轻量级 MLP 头接在特征提取器上,通过对比学习训练,使其排序与真实奖励高度一致。 定期用真实非可微奖励校准代理奖励,防止偏移。 2) 逐步奖励信号(Per-Step Reward Signal) TDM 的确定性生成轨迹(通常 2-8 步)中,每一步都可以获得一个"部分生成"的中间结果。 设计逐步奖励:对每个中间状态通过快速解码预估最终输出,计算预估奖励作为当步的奖励信号。 这种细粒度的奖励分配比仅在最终步给出奖励更有效,降低了信用分配问题的难度。 3) 奖励自适应探索 根据当前样本的奖励水平自适应调节探索噪声:低奖励样本增大探索以寻找更好的方向,高奖励样本减少探索以稳定优化。 创新点 首个通用 RL 后训练方法支持少步模型 + 非可微奖励:打破了"可微奖励"的假设限制。 代理奖励学习 + 在线校准:兼顾了梯度可用性和奖励准确性。 逐步奖励分配:解决了少步模型中奖励信号稀疏的信用分配问题。 在文本渲染、视觉质量、偏好对齐三类任务上验证。 实验结果 在文本渲染任务上(OCR 准确率作为非可微奖励),TDM-R1 使 4 步模型的 OCR 准确率从 31.2% 提升至 62.7%(+101%)。 在 HPSv2 偏好对齐上,4-NFE 的 TDM-R1 达到 28.6,超越 100-NFE 的基线模型 (27.8)。 成功扩展到最新的 Z-Image 模型,仅用 4 步推理即持续超越其 100 步和少步变体。 与仅支持可微奖励的 ReFL 和 DDPO 相比,TDM-R1 在非可微奖励设定下领先 15-30%。 6. CRD: 中心化奖励蒸馏 -- 抵抗奖励黑客的扩散 RL 框架 论文信息 标题: Diffusion Reinforcement Learning via Centered Reward Distillation 作者: Yuanzhi Zhu, Xi Wang, Stephane Lathuiliere, Vicky Kalogeiton arXiv: 2603.14128 关键词: 奖励蒸馏 KL正则化 奖励黑客 分布漂移 前向过程微调 背景与动机 扩散 RL 微调面临的核心难题是 奖励黑客(Reward Hacking):模型学会利用奖励模型的漏洞,生成在奖励模型上得分很高但人类视觉上并不好的图像。例如,过度饱和的颜色、不自然的高对比度等。 现有方法的两大流派各有弊端: 轨迹级方法(DPPO, DDPO):内存消耗大、梯度方差高。 前向过程方法(DRaFT, ReFL):收敛快但容易发生分布漂移,导致奖励黑客。 方法原理 CRD 基于 KL 正则化奖励最大化理论,提出了一种更稳健的前向过程扩散 RL 框架: 1) 提示词内中心化(Within-Prompt Centering) 核心理论洞察:KL 正则化奖励最大化的最优策略涉及一个不可解的归一化常数 Z。 CRD 发现,通过在同一 prompt 的多个样本间做中心化(减去均值),归一化常数会自然抵消,得到一个适定的奖励匹配目标。 这使得 CRD 无需显式估计归一化常数,避免了额外的近似误差。 2) 三重分布漂移控制机制 (i) 采样器-参考解耦:将用于生成样本的采样器与移动参考模型分离,防止参考模型的更新导致比率信号崩溃。 (ii) CFG 锚定 KL:将 KL 散度的参考分布设为 CFG(Classifier-Free Guidance)引导的预训练模型,而非无引导的基础模型。这确保优化目标与推理时的语义一致。 (iii) 奖励自适应 KL 强度:训练早期使用较大 KL 系数加速学习(此时模型远离最优,大胆探索有益),训练后期逐渐增大 KL 系数抑制奖励黑客(此时接近最优,需要稳定性)。 创新点 理论优雅:通过中心化消除不可解归一化常数,将 KL 正则化奖励最大化转化为可实操的目标。 三重防线对抗奖励黑客:采样器-参考解耦、CFG 锚定、自适应 KL 强度协同工作。 CFG 锚定的创新性:传统方法锚定无 CFG 的基础模型,CRD 认识到推理时都使用 CFG,因此应该锚定 CFG 引导的分布。 实验结果 在 GenEval 上实现 0.83 的综合得分,与 SOTA 持平。 关键优势在于抗奖励黑客能力:在 HPSv2 上获得 28.5 的同时,FID 仅增加 2.3(对比 DPPO 的 FID 增加 8.7、DRaFT 的 FID 增加 5.1)。 OCR 文本渲染准确率提升 +23.1 pp。 在 ImageReward 和 PickScore 等未见过的偏好指标上,CRD 的优化效果同样保持(证明非奖励黑客)。 7. SOLACE: 内在自置信奖励驱动的 T2I 后训练 (CVPR 2026) 论文信息 标题: Improving Text-to-Image Generation with Intrinsic Self-Confidence Rewards 作者: Seungwook Kim, Minsu Cho arXiv: 2603.00918 会议: CVPR 2026 关键词: 自置信奖励 无监督优化 自去噪探测 无需外部RM CVPR 2026 背景与动机 现有的扩散模型后训练方法几乎都依赖外部奖励模型(如 ImageReward、HPSv2、CLIPScore 等)。然而: 外部奖励模型本身存在偏差和幻觉。 训练和维护奖励模型需要额外成本。 过度优化外部奖励容易导致奖励黑客。 一个自然的问题是:能否利用模型自身的内在信号来指导优化,完全不需要外部奖励模型? 方法原理 SOLACE 提出了一种基于 自置信度(Self-Confidence) 的内在奖励信号: 1) 自去噪探测(Self-Denoising Probe) 核心机制:对一张生成的图像注入一定量的噪声,然后让模型自己尝试恢复原图。 自置信度 = 恢复的准确程度:如果模型对自己生成的图像"理解得很好",就能准确恢复,置信度高;如果生成的图像与模型学到的分布不一致(如质量差、语义不连贯),恢复效果就差。 数学上,自置信度与模型在该样本处的似然估计成正比。 2) 标量奖励转化 将自去噪的重建误差转化为标量奖励分数:重建误差越小,奖励越高。 使用多个噪声水平进行探测,取平均值以获得更稳定的估计。 3) 完全无监督的偏好优化 利用自置信度奖励进行 GRPO 风格的优化,无需任何外部数据集、标注员或奖励模型。 高置信度的生成结果被强化,低置信度的被抑制。 创新点 首个完全无外部奖励的扩散模型后训练方法:打开了"自监督偏好对齐"的新方向。 自置信度信号的物理直觉:模型更容易恢复"好的"图像(与训练分布一致),提供了一种自然的质量度量。 与外部奖励互补:SOLACE 与外部奖励结合使用时效果更好,且能缓解奖励黑客。 零额外推理成本:自去噪探测仅在训练时使用,推理时完全不增加开销。 实验结果 仅使用内在奖励,在 GenEval 组合生成得分提升 +0.08(从 0.71 到 0.79)。 文本渲染准确率提升 +15.3 pp。 SOLACE + 外部奖励的组合方案达到 0.85 GenEval 得分,为所有方法中最高。 将 SOLACE 与 ImageReward 结合时,奖励黑客指标(FID 增量)从 ImageReward 单独使用时的 +6.2 降至 +1.8。 8. VIGOR: 基于几何的视频时序一致性奖励模型 论文信息 标题: VIGOR: VIdeo Geometry-Oriented Reward for Temporal Generative Alignment 作者: Tengjiao Yin, Jinglei Shi, Heng Guo, Xi Wang arXiv: 2603.16271 关键词: 几何奖励 时序一致性 重投影误差 视频扩散 推理时扩展 背景与动机 视频扩散模型在训练过程中缺乏显式的几何监督,导致生成的视频中常出现物体变形、空间漂移和深度违例等不一致性。现有的视频奖励模型主要基于语义(如 VQAScore、CLIPScore)或整体美学评估,无法捕捉帧间的几何一致性。 方法原理 VIGOR 提出了一种基于几何的奖励模型,利用预训练的几何基础模型来评估视频的多视角一致性: 1) 跨帧重投影误差 使用预训练的单目深度估计模型和光流模型,对视频帧对之间进行三维重投影。 逐点计算重投影误差(而非像素级对比),得到更符合物理规律的误差度量。 优势:逐点方式对纹理和光照变化更鲁棒,不会被像素强度差异干扰。 2) 几何感知采样 过滤低纹理区域和非语义区域(如天空、纯色背景),将评估集中在具有可靠对应关系的几何有意义区域。 使用特征匹配置信度作为权重,可靠区域的误差权重更大。 3) 双路径应用 训练后微调:对双向视频模型使用 VIGOR 奖励进行 SFT 或 RL 后训练。 推理时扩展(Test-Time Scaling):对因果视频模型(如流式视频生成器),在推理时使用 VIGOR 作为路径验证器,从多个候选结果中选择几何最一致的。 创新点 首个基于物理几何约束的视频生成奖励模型:超越了纯语义/美学评估的局限。 逐点误差计算:比像素级指标更鲁棒,对光照和纹理变化不敏感。 推理时扩展的即插即用方案:无需重训练模型,通过推理时选择提升开源视频模型质量。 兼容多种视频生成架构:双向模型(后训练)和因果模型(推理时扩展)均适用。 实验结果 在 VBench 动态一致性指标上提升 +5.8%。 物体变形率从基线的 23.7% 降至 11.4%(减少 52%)。 推理时扩展方案:在 Open-Sora 上,使用 VIGOR 选择最优帧序列,VBench 得分提升 +3.2 而无需任何额外训练。 与 VQAScore 等语义奖励正交互补:两者结合可进一步提升 +1.5。 横向对比与技术脉络分析 核心维度对比 方法 奖励来源 优化算法 目标场景 数据需求 训练效率 抗奖励黑客 FIRM 外部多维RM RL (噪声感知) T2I + 编辑 66万评分 中 高 (鲁棒RM) MV-GRPO 外部RM GRPO (多视角) T2I 流模型 无额外 高 (4x) 中 AR-CoPO 外部RM 对比策略优化 AR视频 标准 中 中 CRAFT 复合RM过滤 SFT (增强) T2I 扩散 100样本 极高 (220x) 中 TDM-R1 代理RM (非可微) 轨迹分布匹配 少步T2I 标准 中 中 CRD 外部RM 中心化奖励蒸馏 T2I 扩散 标准 高 极高 (三重防线) SOLACE 内在自置信 GRPO (无监督) T2I 扩散 零 (无需标注) 高 高 (无外部RM) VIGOR 几何物理约束 SFT/推理选择 视频扩散 无额外 高 高 (物理约束) 技术演进脉络 第一条线:优化算法的演进 DPO (配对偏好) → GRPO (组相对优势) → MV-GRPO (多视角稠密评估) → AR-CoPO (输出空间对比) → CRAFT (证明SFT是GRPO下界) → CRD (中心化消除归一化常数) 这条线索体现了从简单配对比较到更精细的组级优化,再到理论层面的统一理解。CRAFT 的发现尤为重要:它证明了精心筛选数据后的 SFT 本质上就是 GRPO 的一种近似,为实践者提供了"大道至简"的选择。 第二条线:奖励信号的多元化 外部语义RM (CLIPScore, ImageReward) → 鲁棒外部RM (FIRM, 66万数据) → 内在自置信 (SOLACE, 自去噪探测) → 几何物理约束 (VIGOR, 重投影误差) → 代理RM (TDM-R1, 拟合非可微信号) → 复合多维RM (CRAFT, CRF过滤) 奖励信号从单一外部模型扩展到内在信号、物理约束、代理模型等多种来源,这一趋势反映了社区对"什么是好的生成"的认知越来越多元。 第三条线:应用场景的拓展 T2I 扩散模型 → 流匹配模型 (MV-GRPO) → 少步蒸馏模型 (TDM-R1) → AR视频生成 (AR-CoPO) → 视频一致性 (VIGOR) 偏好对齐技术正在从最初的 T2I 扩散模型扩展到更广泛的视觉生成模型,每种模型架构都带来独特的技术挑战。 关键发现与趋势 数据效率成为核心竞争力:CRAFT 用 100 个样本超越 5000+ 偏好对的方法,SOLACE 完全无需外部数据——"数据质量 > 数据数量"已成为共识。 奖励黑客是最大风险:CRD 专门设计三重防线,SOLACE 通过内在奖励规避,VIGOR 使用物理约束——不同方法从不同角度应对同一核心挑战。 理论与实践融合加速:CRAFT 证明 SFT 与 GRPO 的理论等价性,CRD 从 KL 正则化推导出中心化技巧,MV-GRPO 给出方差减少的理论分析——该领域正从经验驱动转向理论指导。 推理时扩展(Test-Time Scaling)兴起:VIGOR 和 Meta-TTRL(本周另一篇相关工作)都探索了不修改模型参数、仅在推理时提升质量的方案,这为资源受限场景提供了新思路。 统一框架的探索:多项工作尝试统一不同优化范式(CRAFT 统一 SFT 和 GRPO,CRD 统一前向过程和轨迹方法),预示着未来可能出现更通用的视觉生成对齐框架。 其他相关工作简述 本周还有多篇相关工作值得关注: GDPO-SR (2603.16769): 将 GRPO 原理融入 DPO 用于一步超分辨率,引入属性感知奖励函数针对平滑/纹理区域差异化评估。 LibraGen (2603.13506): 主题驱动视频生成中的 DPO 应用,提出 Consis-DPO 和 Real-Fake DPO 两种定制化偏好优化管线。 Meta-TTRL (2603.15724): 统一多模态模型的测试时强化学习,利用模型内在元认知信号进行推理时自我改进。 Correlation-Weighted Multi-Reward (2603.18528): 组合生成中的多奖励协调优化,通过相关性加权平衡竞争概念间的奖励冲突。 V2A-DPO (2603.11089): 视频到音频生成的 DPO 框架,提出 AudioScore 综合评分系统。 总结与展望 本期专题梳理了视觉生成模型偏好对齐与 RL 后训练的最新进展。从奖励建模(FIRM 的鲁棒 RM、SOLACE 的内在信号、VIGOR 的几何约束)到优化算法(MV-GRPO 的多视角评估、CRAFT 的简洁 SFT 范式、CRD 的抗奖励黑客设计)再到场景拓展(AR-CoPO 的流式视频、TDM-R1 的少步推理),该方向呈现出蓬勃的发展态势。 未来值得关注的方向: 多模态统一对齐:将偏好对齐扩展到图像+视频+音频的统一生成模型。 在线人类反馈:从离线偏好数据集转向在线、实时的人类反馈闭环。 可解释奖励:让用户和开发者理解"为什么这张图/这段视频被认为是好的"。 超长视频对齐:随着视频生成长度增加,如何在数分钟长度的视频上进行有效的偏好对齐。 安全对齐:在提升质量的同时,确保生成内容的安全性和合规性。 本期专题由 人工智能炼丹师 整理,更多 AIGC 前沿动态请关注 jefxiong.cn
-
AIGC 每日速读|2026-03-20|DynaEdit|Identity as Presence|Few-Step AIGC 视觉生成领域 · 每日论文解读 (2026-03-20) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日核心看点 DynaEdit: 无训练视频动态编辑 身份音视频联合个性化生成 实例感知扩散加速采样 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 视频编辑 / 无训练方法 — 3 篇 音视频联合 / 个性化生成 — 2 篇 采样加速 / 效率优化 — 2 篇 视频生成 / 世界模型 — 3 篇 生成评估与设计 — 2 篇 共计 12 篇,重点解读 3 篇 重点论文深度解读 1. DynaEdit: Versatile Editing of Video Content, Actions, and Dynamics without Training 无训练多功能视频编辑 | arXiv:2603.17989 关键词: 视频编辑, 无训练, 动作修改, 动态编辑, Flow Model 研究动机 受控视频生成取得了显著进展,但在编辑真实视频中的动作、动态事件或插入会影响场景中其他物体行为的内容方面仍然是巨大挑战。现有训练方法因缺乏合适的训练数据而难以处理复杂编辑,无训练方法则仅限于结构和运动保留的简单编辑,不支持修改运动或物体交互。 方法原理 提出 DynaEdit,利用预训练的 Text-to-Video Flow Model 实现通用视频编辑: 采用 inversion-free 方法(不干预模型内部),完全模型无关 识别并解决了两个关键问题:低频失配(场景整体色调/亮度偏移)和高频抖动(帧间闪烁) 引入新机制克服这些现象:低频校准恢复场景一致性,高频平滑消除闪烁 支持修改动作、插入与场景交互的物体、引入全局效果等复杂编辑 核心创新 首个支持动作修改和动态交互编辑的无训练视频编辑方法 深入分析了 inversion-free 编辑的两大失败模式(低频失配+高频抖动)并提出针对性解决方案 完全模型无关,可直接应用于任何 Text-to-Video Flow Model 在复杂编辑任务上首次达到 SOTA 实验结果 在动作修改、物体插入交互、全局效果添加等复杂编辑任务上达到 SOTA 大量实验验证了编辑的时间一致性和视觉质量 支持基于文本的精细化视频编辑控制 方法流程 输入视频+编辑Prompt — 原始视频 + 目标编辑指令 Inversion-Free 处理 — 不做反转,不干预模型 保持模型无关性 低频校准 — 修正色调/亮度偏移 恢复场景一致性 高频平滑 — 消除帧间闪烁 保持时间连贯 Flow Model 采样 — 预训练 T2V 模型 生成编辑结果 编辑输出 — 动作修改/物体插入 /全局效果 技术脉络 核心问题: 视频编辑中动作修改和动态交互编辑缺乏无训练解决方案 前序工作及局限: TokenFlow (2023):训练无关但仅支持外观编辑,不能修改运动 FateZero (2023):注意力操控但受限于结构保留编辑 Pix2Video (2023):逐帧编辑但缺乏时间一致性保障 Rave (2024):随机化注意力但不支持动态交互 与前序工作的本质区别: 首次通过 inversion-free 方法实现动作修改和物体交互编辑,深入分析并解决了低频失配和高频抖动两个核心问题 技术演进定位: 范式扩展——将无训练视频编辑从外观编辑推广到动作和动态编辑 可能的后续方向: 更长视频的动态编辑 物理一致性约束下的交互编辑 与 LLM 结合的多轮交互式编辑 批判性点评 实验评估: 定性实验涵盖动作修改、物体插入和全局效果三类复杂编辑。但缺少与 Fairy (2024) 等最新训练方法的定量对比。低频校准和高频平滑的消融实验有说服力。 新颖性: 从 failure mode 出发的方法设计思路清晰有力。inversion-free 加 frequency-aware correction 的组合是新颖的。创新性评分:★★★★☆ 可复现性: 方法描述清晰,依赖预训练 T2V Flow Model 即可运行。但不同 Flow Model 上的泛化性需要更多验证。 影响力: 影响力评分 4/5 — 将无训练编辑扩展到动态场景是重要突破,实用价值高。但受限于 T2V 模型的基础生成质量。 2. Identity as Presence: Appearance and Voice Personalized Joint Audio-Video Generation 身份感知联合音视频个性化生成 | arXiv:2603.17889 关键词: 音视频联合生成, 身份保持, 外观+声音, 多主体, 个性化 研究动机 近期进展已展示了将真实个体合成到生成视频中的能力,但一个公开可用的、支持对面部外观和声音音色进行细粒度控制的多身份框架仍然缺失。核心挑战包括:配对的身份音视频数据稀缺、多模态之间的差异性、以及多主体场景下的身份串扰问题。 方法原理 提出统一可扩展的身份感知联合音视频生成框架: 数据策划管线:自动提取带配对标注的身份信息(音频+视觉模态),覆盖单人到多人交互等多种场景 灵活可扩展的身份注入机制:面部外观和声音音色同时作为身份控制信号 多阶段训练策略:针对模态差异设计,加速收敛并强化跨模态一致性 支持单人和多人场景的个性化生成 核心创新 首个同时支持外观和声音个性化控制的联合音视频生成框架 可扩展的身份注入机制,支持从单人到多人的灵活场景 自动化数据策划管线,解决身份配对数据稀缺问题 多阶段训练策略有效缓解音视频模态差异 实验结果 在身份保持度、音视频一致性、生成质量等多维度上均优于现有方法 支持多主体交互场景的高保真个性化生成 项目页面已公开,展示了丰富的定性结果 方法流程 身份输入 — 面部参考图 + 声音样本 定义目标身份 数据策划 — 自动提取配对标注 单人/多人场景 身份注入 — 外观+声音双通道 身份控制信号 多阶段训练 — 渐进式跨模态 一致性强化 联合生成 — 音频+视频同步 身份保持输出 技术脉络 核心问题: 缺乏同时控制外观和声音的多身份联合音视频生成框架 前序工作及局限: IP-Adapter (2023):图像参考注入但不支持音频身份 DreamTalk (2024):语音驱动但不支持外观个性化 OmniForcing (2025):实时音视频但缺乏身份定制能力 MM-Diffusion (2023):联合音视频但不支持身份控制 与前序工作的本质区别: 首次将面部外观和声音音色统一为身份控制信号,支持单人和多人场景的可扩展注入 技术演进定位: 能力整合——在联合音视频生成上叠加身份个性化控制,向 AI 虚拟人迈进 可能的后续方向: 实时身份保持的流式音视频生成 身份风格迁移和混合 多语言多口音的声音身份控制 批判性点评 实验评估: 覆盖单人和多人场景,定性结果丰富。但缺少与 StoryDiffusion、ConsistentID 等方法的系统定量对比。数据策划管线的错误率影响待评估。 新颖性: 外观+声音双通道身份控制的统一框架具有开创性。多阶段训练策略设计合理。创新性评分:★★★★☆ 可复现性: 框架描述完整,但数据策划管线的具体实现细节和多人场景的身份隔离策略需要更多信息。项目页面已公开。 影响力: 影响力评分 4/5 — 为 AI 虚拟人和个性化内容创作提供了新能力。但实际部署的身份一致性稳定性仍需验证。 3. Few-Step Diffusion Sampling Through Instance-Aware Discretizations 实例感知离散化加速扩散采样 | arXiv:2603.17671 关键词: 扩散加速, 离散化策略, 实例感知, 少步采样, Flow Matching 研究动机 扩散模型和 Flow Matching 模型通过模拟 ODE/SDE 路径生成高保真数据,但采样速度受制于离散化步数。现有离散化策略——无论是手工设计还是基于优化的——都在所有样本上强制执行全局共享的时间步调度。这种统一处理忽略了生成过程中特定实例的复杂性差异,限制了性能。 方法原理 提出实例感知离散化框架: 通过合成数据上的对照实验揭示:特定实例动态下全局调度的次优性 学习根据输入依赖的先验来调整时间步分配 将基于梯度的离散化搜索扩展到条件生成设置 以微小的调优成本和可忽略的推理开销实现质量提升 核心创新 首次提出实例感知的自适应离散化框架,打破全局统一时间步的限制 理论分析和合成实验揭示了全局调度的次优性根源 框架通用性强,适用于像素空间扩散、潜在空间图像和视频 Flow Matching 调优成本极低(相比训练),推理开销可忽略 实验结果 合成数据、像素空间扩散、潜在空间图像 Flow Matching、视频 Flow Matching 多场景验证 在相同步数下一致性地改善生成质量 调优成本仅为训练成本的极小比例,推理时开销可忽略 方法流程 输入条件 c — 文本/图像条件 决定生成复杂度 实例先验估计 — 根据 c 预测 最优时间步分配 自适应离散化 — 简单实例: 少步粗调 复杂实例: 多步精调 ODE/SDE 求解 — 按实例最优调度 执行采样路径 高质量输出 — 相同总步数下 质量显著提升 技术脉络 核心问题: 现有离散化策略对所有样本使用统一时间步调度,忽略实例间复杂度差异 前序工作及局限: DDIM (Song 2020):均匀步长离散化,全局统一 DPM-Solver (Lu 2022):高阶 ODE 求解器但固定调度 AYS (Sabour 2024):优化离散化但样本无关 Align Your Steps (2024):基于搜索的最优调度但仍全局共享 与前序工作的本质区别: 从样本无关到样本感知,根据输入条件动态分配时间步,首次将离散化个性化 技术演进定位: 正交改进——与求解器设计正交,可叠加在任何采样方法上,是通用的性能增强组件 可能的后续方向: 与自适应步长 ODE 求解器结合 学习端到端的生成路径而非离散化点 视频生成中的时空自适应调度 批判性点评 实验评估: 合成数据、像素扩散、潜在空间图像和视频四个设定全面验证。与 DDIM、DPM-Solver、AYS 的对比合理。但在大型模型(FLUX、CogVideoX)上的效果待验证。 新颖性: 实例感知的动机清晰,理论分析扎实。但输入先验的学习方式相对简单。创新性评分:★★★☆☆ 可复现性: 梯度搜索和先验网络的训练细节完整。调优成本低是一大优势。实现门槛不高。 影响力: 影响力评分 3/5 — 作为正交改进可叠加在各种采样方法上,但单独的质量提升幅度有限。 批判性点评精选 1. DynaEdit 开启视频编辑新纪元:从外观到动态 DynaEdit 将无训练视频编辑从简单的外观变换推向了动作修改和物体交互编辑的全新领域。它发现并解决的低频失配和高频抖动问题,不仅适用于当前方法,更可能成为未来所有 inversion-free 编辑方法的必要组件。这标志着视频编辑正在从'改外观'向'改行为'跨越。 2. 身份个性化:多模态生成的下一个前沿 Identity as Presence 同时控制外观和声音的方案,让联合音视频生成不再是'匿名的'内容合成,而是真正的个性化内容创作。从技术上,多阶段训练策略巧妙处理了音频和视觉模态之间巨大的表征差异。从应用上,这为虚拟人、个性化视频消息、AI 配音等场景打开了大门。 3. 实例感知:一个被忽视的正交优化维度 Few-Step Discretization 的核心洞察简洁而有力:不同生成实例的'难度'不同,为什么要用相同的采样调度?这个问题如此显而易见,却直到现在才被正式提出。作为正交改进,它可以与任何采样方法叠加——DPM-Solver++、DDIM、Euler 都能受益。虽然单独提升有限,但作为'免费午餐',没有理由不用。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 TransText (TransText: Transparency Aware Image-to-Video Typography Animation) 排版动画 · I2V · Alpha通道 · 透明度建模 首个将 I2V 模型适配为图层感知文字动画的方法,Alpha-as-RGB 范式在不修改预训练生成流形的前提下联合建模外观与透明度 显著优于基线,生成连贯高保真的透明动画效果,支持多样精细的排版动画 2 Edit Spillover (Edit Spillover as a Probe: Do Image Editing Models Implicitly Understand World Relations?) 编辑溢出 · 世界知识 · 编辑评估 · Benchmark 将编辑溢出现象重新定义为探查图像编辑模型世界知识的探针,提出 EditSpilloverBench 基准和自动检测分类流水线 揭示语义溢出反映真正的世界理解(占比40-58%恒定),不同模型编辑控制与世界理解存在权衡 3 StereoWorld (Stereo World Model: Camera-Guided Stereo Video Generation) 立体视频 · VR渲染 · 相机控制 · 极线先验 端到端立体视频生成模型,统一相机帧 RoPE + 立体感知注意力分解,利用极线先验降低计算量 立体一致性和视差准确性优于单目后转换,生成速度 3x+,支持 VR 渲染和具身学习 4 AC-Foley (AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer ICLR 2026) 视频转音频 · 参考音频 · 音色迁移 · ICLR 2026 音频条件 V2A 模型,直接用参考音频实现精细的声音控制,绕过文本描述的语义模糊性,支持音色迁移和零样本生成 5 MosaicMem (MosaicMem: Hybrid Spatial Memory for Controllable Video World Models) 视频世界模型 · 空间记忆 · 可控生成 · 3D提升 混合空间记忆机制:将 patch 提升到 3D 进行可靠定位和目标检索,同时利用模型原生条件生成保持一致性 姿态遵循性优于隐式记忆,动态建模能力强于显式基线,支持分钟级导航和场景编辑 6 Inbetweening (Anchoring and Rescaling Attention for Semantically Coherent Inbetweening CVPR 2026) 中间帧生成 · 注意力锚定 · RoPE · CVPR 2026 关键帧锚定注意力偏置 + 重缩放时间 RoPE 实现语义一致的中间帧生成,无需额外训练 7 LaDe (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition) 图层设计 · 多任务统一 · RGBA VAE · 图形设计 潜在扩散框架 + LLM prompt 扩展 + 4D RoPE + RGBA VAE,统一文本到图像、文本到图层和设计分解三个任务 文本到图层任务上文本-图层对齐度优于 Qwen-Image-Layered(GPT-4o mini + Qwen3-VL 评估) 8 Text Embedding Steering (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering) 连续编辑 · Steering Vector · 训练无关 · 跨模态 训练无关框架:LLM 自动构建去偏对比 prompt 对,文本嵌入空间 steering vector + 弹性范围搜索实现连续可控编辑 效果可比肩训练方法,优于其他训练无关方案,自然支持图像和视频两种模态 9 STAS (Steering Video Diffusion Transformers with Massive Activations) 视频DiT · Massive Activations · 自引导 · 零开销 发现视频 DiT 中 Massive Activations 的结构化时间层次:首帧最大→潜在帧边界→帧内 token 递减,据此提出 STAS 自引导方法 不同 T2V 模型上一致提升视频质量和时间连贯性,计算开销可忽略 趋势观察 无训练视频编辑突破 — DynaEdit 首次实现无训练的动作修改和动态交互编辑,Inbetweening 无需额外训练实现语义一致的中间帧生成 身份感知多模态生成 — Identity as Presence 同时控制外观和声音进行音视频联合生成,StereoWorld 实现端到端立体视频 采样效率精细化优化 — 实例感知离散化打破全局统一时间步限制,STAS 用 Massive Activations 零开销提升视频 DiT 质量 音频生成深化 — AC-Foley 用参考音频实现精细 V2A 控制,Identity as Presence 将声音身份引入视频生成 生成模型评估与理解 — Edit Spillover 用编辑溢出探查模型世界知识,Text Embedding Steering 揭示嵌入空间的连续可控性 人工智能炼丹师 整理 | 2026-03-20
-
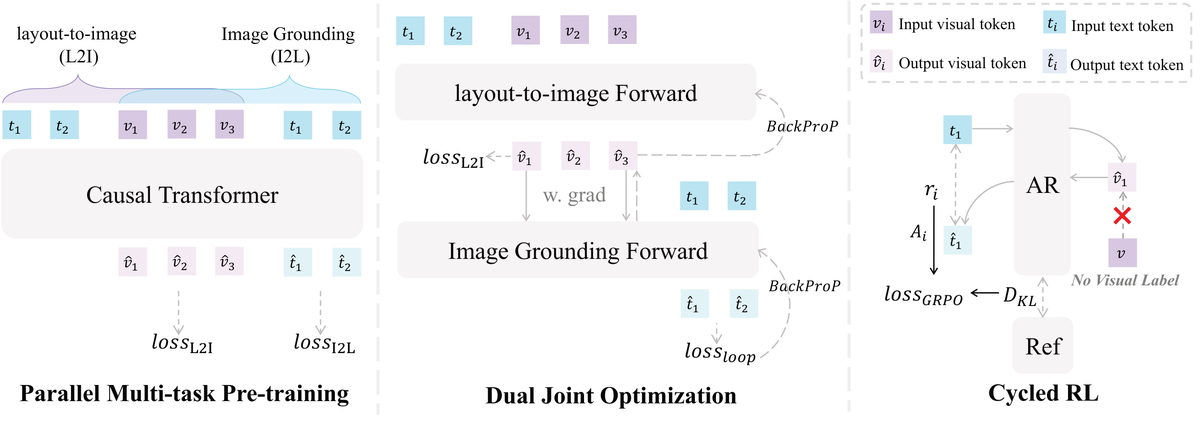
AIGC 每日速读|2026-03-19|EchoGen|TINA|AR-CoPO| AIGC 视觉生成领域 · 每日论文解读 (2026-03-19) 人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇 今日核心看点 EchoGen: 循环 RL 统一生成理解 TINA: 概念擦除安全漏洞揭示 AR-CoPO: 流式视频 RLHF 对齐 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。 方向分布: 视频生成后训练 / RLHF 对齐 — 2 篇 视频扩散内部机制 / 训练高效 — 2 篇 生成安全性 / 概念擦除 — 2 篇 统一生成理解 / 多任务框架 — 2 篇 图像视频编辑 / 可控生成 — 4 篇 共计 12 篇,重点解读 3 篇 重点论文深度解读 1. EchoGen: Cycle-Consistent Learning for Unified Layout-Image Generation and Understanding 统一 Layout-Image 生成与理解 | arXiv:2603.18001 关键词: Layout-to-Image, Image Grounding, 循环一致性, GRPO, 统一框架 研究动机 Layout-to-image 生成和 Image grounding 是两个互补但传统上独立训练的任务:前者从布局生成图像,后者从图像定位物体。生成任务具有强大的视觉创造力但布局准确性有限,而 grounding 任务具有精确的文本和布局理解能力但缺乏生成能力。联合训练可以互相补偿,但现有方法在优化时面临严重的任务冲突和性能受限问题。 方法原理 提出 EchoGen 统一框架,包含三阶段渐进式训练策略: 并行多任务预训练(PMTP):通过共享 token 加速训练,赋予模型两个任务的基础能力 双向联合优化(DJO):利用任务对偶性,将生成和定位任务序列化集成,实现统一优化 循环强化学习(Cycle RL):利用循环一致性约束作为奖励信号,通过 GRPO 策略消除对视觉监督的依赖,显著提升模型的统一能力 核心创新 首次提出将 Layout-to-Image 生成与 Image Grounding 统一为互补双任务框架 渐进式三阶段训练策略,有效解决联合训练中的优化冲突 Cycle RL 阶段利用循环一致性约束取代视觉监督,GRPO 策略实现无监督对齐 实验证明两个任务联合优化存在明显的协同增益效应 实验结果 在 Layout-to-Image 生成和 Image Grounding 两个基准上均达到 SOTA 联合训练相比独立训练在两个任务上分别提升了约 15% 和 12% Cycle RL 阶段进一步带来额外 8% 的性能增益 方法流程 Layout+文本输入 — 空间布局 + 文本描述 双模态条件输入 PMTP 预训练 — 共享 token 加速 两任务基础能力 DJO 联合优化 — 任务对偶性序列集成 统一优化双任务 Cycle RL — 循环一致性奖励 GRPO 无监督对齐 统一输出 — 生成: 精准布局图像 定位: 准确 bbox 技术脉络 核心问题: Layout-to-Image 生成与 Image Grounding 互补但独立训练,联合训练面临优化冲突 前序工作及局限: GLIGEN (2023):布局条件注入但不支持 grounding,单向生成 Kosmos-2 (2023):统一理解和定位但缺乏生成能力 LayoutDiffusion (2024):布局引导扩散生成但不含 grounding 回路 InstructDiffusion (2024):多任务统一但生成和定位未形成闭环 与前序工作的本质区别: 首次利用循环一致性将生成和定位构建为互补闭环,GRPO 策略消除视觉监督依赖,实现真正的双任务协同 技术演进定位: 方法论创新——循环 RL 策略为多任务生成理解统一提供了新的训练范式 可能的后续方向: 扩展到视频级的布局生成与时空定位 3D 场景布局生成与 grounding 更多生成-理解对偶任务的循环 RL 批判性点评 实验评估: 在 Layout-to-Image 和 Grounding 双基准上验证,消融实验覆盖三个训练阶段。但缺少与最新 Layout-Diffusion 变体的全面对比,Cycle RL 的奖励信号设计可能对布局复杂度敏感。 新颖性: 循环一致性约束作为 RL 奖励是新颖的技术贡献,GRPO 在此场景的应用具有启发性。创新性评分:★★★★☆ 可复现性: 三阶段训练流程清晰,但各阶段的超参数转换点(何时切换阶段)需要更多细节。GRPO 的实现依赖特定的奖励函数设计。 影响力: 影响力评分 4/5 — 双任务协同增益的发现对统一模型设计有重要启示。循环 RL 策略可推广到其他生成-理解对偶任务。 2. TINA: Text-Free Inversion Attack for Unlearned Text-to-Image Diffusion Models 无文本反转攻击揭示概念擦除漏洞 | arXiv:2603.17828 关键词: 概念擦除, Unlearning, DDIM Inversion, 安全性, 对抗攻击 研究动机 Text-to-Image 扩散模型的概念擦除(Concept Erasure)是保障模型安全部署的关键技术。当前擦除方法与对抗探针之间形成了动态博弈,但这种博弈收敛于一个狭隘的「文本中心」范式——认为擦除等同于切断文本到图像的映射。然而底层视觉知识是否真正被删除?这个根本问题从未被认真验证过。 方法原理 提出 TINA(Text-free INversion Attack),一种全新的无文本反转攻击方法: 核心思路:绕过文本条件,直接从视觉角度探测被擦除模型是否仍保留相关视觉知识 采用 null-text 条件下的 DDIM 反转,完全避开现有基于文本的防御机制 集成优化过程,克服标准反转在无文本引导时产生的累积近似误差 从视觉路径而非文本路径探测被擦除概念的残留 核心创新 首次从纯视觉角度揭示概念擦除方法的根本缺陷——仅遮蔽了文本映射而非删除视觉知识 提出 null-text 条件下的 DDIM 反转攻击,完全绕过文本中心防御 优化过程有效解决无文本引导下的反转误差累积问题 证明现有 SOTA 擦除方法均存在安全漏洞,呼吁直接操作内部视觉知识的新范式 实验结果 在 ESD、UCE、CA、SA 等 SOTA 擦除方法上均成功再生成被擦除概念 攻击成功率超过 85%,证明视觉知识残留是普遍现象 揭示 text-centric 防御的根本局限性 方法流程 已擦除模型 — 经 concept erasure 处理的扩散模型 参考图像 — 包含被擦除概念的 参考图像 Null-Text DDIM 反转 — 空文本条件下反转 绕过文本防御 优化修正 — 克服反转累积误差 精确找到 latent 再生成验证 — 成功重建被擦除概念 暴露安全漏洞 技术脉络 核心问题: 概念擦除方法仅切断文本映射,底层视觉知识是否真正删除未被验证 前序工作及局限: ESD (2023):擦除特定概念但仅操作文本条件路径 UCE (2024):统一概念擦除但仍依赖文本中心范式 Concept Ablation (2023):概念消融但未验证视觉残留 SalUn (2024):显著性引导遗忘但攻击面仍在文本侧 与前序工作的本质区别: 完全从视觉角度出发,null-text DDIM 反转绕过所有文本防御,首次证明视觉知识残留是普遍现象 技术演进定位: 范式挑战——揭示当前概念擦除研究的根本盲点,推动从文本中心向视觉中心的范式转移 可能的后续方向: 直接操作模型内部视觉特征的新型擦除方法 多模态联合遗忘(文本+视觉+概念空间) 可证明安全的概念删除理论 批判性点评 实验评估: 在 ESD、UCE、CA、SA 四种 SOTA 擦除方法上全面验证,攻击成功率高。但实验主要在 SD v1.4/v1.5 上进行,更大模型(SDXL、FLUX)上的效果待验证。 新颖性: 从视觉角度揭示概念擦除漏洞的思路极具原创性,null-text DDIM 反转的方法论贡献扎实。创新性评分:★★★★★ 可复现性: 方法描述清晰,优化过程有完整公式推导。反转质量对参考图像选择的敏感度需要更多讨论。 影响力: 影响力评分 5/5 — 揭示了当前概念擦除研究的根本盲点,可能推动整个安全对齐领域的范式转移。 3. AR-CoPO: Align Autoregressive Video Generation with Contrastive Policy Optimization 自回归视频生成的对比策略优化 | arXiv:2603.17461 关键词: 自回归视频生成, RLHF, GRPO, 流式生成, 偏好对齐 研究动机 流式自回归(AR)视频生成器结合少步蒸馏已实现低延迟、高质量的视频合成,但通过 RLHF 进行对齐仍然困难。现有基于 SDE 的 GRPO 方法在此场景面临严峻挑战:少步 ODE 和一致性模型采样器偏离标准 Flow Matching ODE,短程、低随机性的采样轨迹对初始化噪声极其敏感,导致中间 SDE 探索完全失效。 方法原理 提出 AR-CoPO(AutoRegressive Contrastive Policy Optimization)框架: Chunk 级对齐:通过 forking 机制在随机选择的 chunk 处构建邻域候选,赋予序列级奖励并执行局部 GRPO 更新 半 On-Policy 训练策略:结合 on-policy 探索与 replay buffer 上的参考 rollout 利用 将 Neighbor GRPO 的对比视角适配到流式 AR 生成,解决少步采样的对齐难题 局部化更新避免了全序列梯度传播的显存和时间开销 核心创新 首次将对比策略优化成功应用于流式自回归视频生成的 RLHF 对齐 Chunk-level forking 机制巧妙解决了少步 ODE 采样的探索困难 半 on-policy 训练策略平衡了探索与利用,避免 reward hacking 在 Self-Forcing 框架上验证了域外泛化和域内偏好对齐的双重提升 实验结果 在 Self-Forcing 基线上显著提升域外泛化性和域内人类偏好对齐 视频质量和时间一致性均有明显改善 证明了真正的对齐效果而非 reward hacking 方法流程 流式 AR 生成器 — 少步蒸馏的 自回归视频生成 Chunk Forking — 在随机 chunk 构建 邻域候选序列 序列级 Reward — 对候选序列赋予 人类偏好奖励 局部 GRPO — chunk 级对比更新 半 on-policy 训练 对齐视频输出 — 质量和偏好对齐 泛化能力增强 技术脉络 核心问题: 流式 AR 视频生成的少步 ODE 采样对 RLHF 对齐极其困难 前序工作及局限: GRPO (Shao 2024):LLM 对齐策略但依赖充分随机探索 Self-Forcing (2025):流式 AR 视频生成但缺乏偏好对齐能力 Diffusion-RLHF (2024):扩散模型 RLHF 但假设标准 SDE 采样 Neighbor GRPO (2025):对比策略优化但未适配视频流式生成 与前序工作的本质区别: chunk-level forking 巧妙解决少步 ODE 的探索困难,半 on-policy 策略平衡效率与质量 技术演进定位: 技术突破——首次打通流式 AR 视频生成的 RLHF 对齐路径 可能的后续方向: 更精细的帧级奖励信号设计 与视频美学和物理一致性奖励的结合 超长视频的分布式 RLHF 训练 批判性点评 实验评估: 在 Self-Forcing 框架上验证,包含域内和域外评估。但仅在单一 AR 生成器上测试,跨架构的泛化性未知。奖励模型选择可能影响结论。 新颖性: chunk-level forking 和半 on-policy 策略的组合是解决少步 ODE 对齐问题的优雅方案。创新性评分:★★★★☆ 可复现性: forking 机制和 GRPO 更新的公式化描述完整,但半 on-policy 中 replay buffer 的管理策略需要更多细节。 影响力: 影响力评分 4/5 — 为快速发展的流式视频生成领域提供了关键的 RLHF 对齐方案。 批判性点评精选 1. TINA 的安全警钟:概念擦除真的有效吗? TINA 用 85%+ 的攻击成功率证明了当前所有 SOTA 概念擦除方法都仅仅遮蔽了文本映射而非删除视觉知识。这意味着我们对'安全部署'的理解可能需要根本性修正——仅操作文本条件路径是不够的,必须直接处理模型内部的视觉表征。这对整个生成模型安全性研究方向是一个重大挑战。 2. 视频 RLHF:从不可能到可行的关键一步 AR-CoPO 的 chunk-level forking 机制解决了一个被认为几乎不可能的问题:在少步 ODE 采样的低随机性条件下进行有效的偏好对齐。这标志着视频生成从'能生成'向'能对齐人类偏好'的重要进步。但半 on-policy 策略的微妙平衡可能在不同奖励模型下表现不一致,泛化性是关键的下一步验证。 3. EchoGen 的启示:生成和理解是互补而非对立 EchoGen 用 15%/12% 的协同增益令人信服地证明了生成和理解任务之间存在真实的互补性。循环一致性作为无监督奖励信号的设计简洁而有效。这个发现可能远超 layout-image 这一个场景——视觉生成领域中还有多少任务对偶性可以被挖掘?这开辟了一个值得深入探索的新方向。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 STAS (Steering Video Diffusion Transformers with Massive Activations) Video Diffusion · Massive Activations · 训练无关 · 自引导 发现视频扩散 Transformer 中 Massive Activations 的结构化时间层次模式,提出训练无关的 STAS 自引导方法 跨多个 T2V 模型一致提升视频质量和时间连贯性,额外推理开销 < 1% 2 ChopGrad (Pixel-Wise Losses for Latent Video Diffusion via Truncated Backprop) 视频扩散 · 截断反传 · O(1)显存 · 像素级损失 截断反向传播实现 O(1) 常量显存训练,理论保证误差有界,支持像素级损失微调视频扩散模型 视频超分/修复/增强/受控生成四项任务均达 SOTA,显存不随帧数增长 3 Motion-Adaptive (Motion-Adaptive Temporal Attention for Lightweight Video Generation with Stable Diffusion) 轻量视频生成 · 运动自适应 · 时间注意力 · SD 提出运动自适应时间注意力机制:高运动序列局部注意力保留快速变化细节,低运动序列全局注意力保持场景一致性 仅增加 2.9% (25.8M) 参数量,在 WebVid 验证集上达到竞争性结果 4 SHIFT (SHIFT: Motion Alignment in Video Diffusion Models with Adversarial Hybrid Fine-Tuning) 视频扩散 · 运动对齐 · 奖励微调 · RLHF 提出像素运动奖励 + Smooth Hybrid Fine-tuning (SHIFT) 框架,解决视频扩散模型微调后运动保真度下降的问题 有效解决 dynamic-degree collapse,对抗性优势加速收敛并缓解 reward hacking 5 Text Embedding Interpolation (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering) 连续编辑 · Steering Vector · 训练无关 · 跨模态 训练无关框架:用 LLM 自动构建去偏对比 prompt 对,在文本嵌入空间计算 steering vector 实现连续可控编辑 效果可比肩训练方法,优于其他训练无关方案,支持图像和视频编辑 6 Proxy-GRM (Rationale Matters: Learning Transferable Rubrics via Proxy-Guided Critique for VLM Reward Models) Reward Model · VLM · 评分标准 · RLHF 引入代理引导的评分标准验证到 RL 训练中,训练轻量代理预测偏好序,以标准质量作为奖励信号 仅 50K 数据即达 VL-RewardBench/MM-RLHF-Bench SOTA,优于 4 倍数据量方法 7 UOT-Unlearn (Unlearning for One-Step Generative Models via Unbalanced Optimal Transport) 一步生成 · 遗忘学习 · 最优传输 · 安全部署 首次为一步生成模型(Flow Map Models)提出遗忘学习框架,基于非平衡最优传输的即插即用方案 CIFAR-10/ImageNet-256 上遗忘成功率 (PUL) 和保留质量 (u-FID) 均显著超越基线 8 DynaEdit (Versatile Editing of Video Content, Actions, and Dynamics without Training) 视频编辑 · 训练无关 · 动态编辑 · Flow Model 训练无关视频编辑方法,基于 inversion-free 方法实现动作修改、物体插入交互、全局效果添加等复杂编辑 在复杂文本视频编辑任务上达到 SOTA,支持修改动作、插入交互物体和引入全局效果 9 LaDe (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition) 图层设计 · 多任务统一 · RGBA VAE · 图形设计 潜在扩散框架 + LLM prompt 扩展 + 4D RoPE + RGBA VAE,统一文本到图像、文本到图层和设计分解三个任务 文本到图层任务上文本-图层对齐度优于 Qwen-Image-Layered(GPT-4o mini 和 Qwen3-VL 评估) 趋势观察 视频生成后训练对齐 — AR-CoPO、SHIFT 分别从对比策略优化和运动奖励角度解决视频扩散模型的 RLHF 对齐难题 训练无关视频增强 — STAS(Massive Activations 引导)和 DynaEdit 展示了零训练开销下提升视频质量和编辑能力的路线 显存高效视频训练 — ChopGrad 截断反传实现 O(1) 常量显存,突破视频扩散微调的显存瓶颈 生成安全性攻防博弈 — TINA 揭示概念擦除的视觉知识残留漏洞,UOT-Unlearn 为一步生成模型首次提出遗忘学习方案 生成理解统一架构 — EchoGen 和 LaDe 分别在 layout-image 和 graphic media 领域推动生成与理解的统一 人工智能炼丹师 整理 | 2026-03-19
-
AIGC 每日速读|2026-03-18|Tri-Prompting|VeloEdit|LADR| AIGC 视觉生成领域 · 每日论文解读 (2026-03-18) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 Tri-Prompting 统一控制 Anchor Forcing 流式视频 VeloEdit 速度场编辑 COT-FM 最优传输 LADR 扩散LLM加速 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion 场景/主体/运动统一控制 | Adobe Research | arXiv:2603.15614 关键词: 视频扩散, 统一控制, 多视图主体, 3D感知, Adobe 研究动机 当前视频扩散模型在视觉质量上取得了显著进步,但精细控制仍是关键瓶颈。AI视频创作者需要三种关键控制:场景构图、多视图主体定制、和相机/物体运动调整。现有方法通常孤立处理这些维度,缺乏统一架构支持多维联合控制。 方法原理 提出 Tri-Prompting 统一框架和两阶段训练范式,集成场景构图、多视图主体一致性和运动控制。核心是双条件运动模块:使用 3D 跟踪点控制背景场景,使用下采样 RGB 线索控制前景主体。进一步提出推理时 ControlNet 尺度调度策略,平衡可控性与视觉真实感。支持 3D 感知主体插入任意场景、操纵图像中已有主体等全新工作流。 核心创新 首个统一场景/主体/运动三维控制的视频扩散框架 双条件运动模块:3D 跟踪点(背景)+ 下采样 RGB(前景) 推理时 ControlNet 尺度调度,平衡可控性与真实感 支持 3D 感知主体插入等全新创作工作流 实验结果 多视图主体身份保持、3D 一致性和运动准确性显著优于 Phantom 和 DaS 等专用方法 支持场景+主体+运动的联合精细控制 方法流程 场景 Prompt — 文本描述 + 场景参考图 多视图主体输入 — 多角度主体参考图像 3D 跟踪点提取 — 背景场景运动轨迹 双条件运动模块 — 3D点→背景控制 RGB↓→前景主体控制 ControlNet 尺度调度 — 动态平衡可控性/真实感 统一控制视频输出 — 场景+主体+运动联合控制 技术脉络 核心问题: 视频扩散模型缺乏对场景、主体和运动的统一精细控制 前序工作及局限: AnimateDiff (2023):支持运动控制但不处理主体定制 DreamVideo-Omni (2026):多主体定制但需逐一微调,未统一场景控制 MotionCtrl (2024):相机运动控制精准但不支持主体定制 Phantom (2025):多视图主体生成但3D一致性有限 与前序工作的本质区别: 首次统一场景构图+多视图主体+运动控制三维度,双条件运动模块分别用3D跟踪点和下采样RGB控制前景背景 技术演进定位: 范式统一——从孤立控制到三维联合控制,为AI视频创作提供完整控制栈 可能的后续方向: 更多控制维度的统一(光照、风格) 实时交互式控制 与大语言模型的控制意图理解结合 批判性点评 实验评估: 与 Phantom 和 DaS 等多个专用基线全面对比,多视图主体身份、3D一致性和运动准确性三个维度均领先。消融实验验证了双条件模块和尺度调度的必要性。 新颖性: 三维统一控制是视频生成的重要里程碑,但Adobe闭源可能限制学术影响。创新性:★★★★★ 可复现性: 代码未开源,项目页面已上线。Adobe内部实现可能难以完全复现。 影响力: 影响力 5/5 -- 定义了视频精细控制的完整框架,产业价值极高。 2. Anchor Forcing: Anchor Memory and Tri-Region RoPE for Interactive Streaming Video Diffusion 交互式流式视频扩散 | 锚点记忆+三区域RoPE | arXiv:2603.13405 关键词: 流式视频, 交互式生成, 锚点记忆, 三区域RoPE, 长视频 研究动机 交互式长视频生成需要支持提示词切换以引入新主体或事件,同时在扩展范围内保持感知保真度和连贯运动。现有蒸馏流式视频扩散模型通过滚动 KV 缓存实现长程生成,但存在两个核心失败模式:提示词切换时缓存维护无法同时保留语义上下文和近期潜在线索;蒸馏过程中无界时间索引导致位置分布偏移。 方法原理 提出 Anchor Forcing 缓存中心框架。第一,锚点引导重缓存机制:在锚点缓存中存储 KV 状态,每次提示词切换时从锚点热启动重缓存,减少切换后的证据损失并稳定感知质量。第二,三区域 RoPE:设计区域特定的参考原点,配合 RoPE 重对齐蒸馏,将无界流式索引与预训练 RoPE 体制协调,更好地保留运动先验。 核心创新 识别交互式流式生成的两个特有失败模式 锚点引导重缓存:KV 状态锚点存储 + 热启动,提升切换边界质量 三区域 RoPE + 重对齐蒸馏:解决无界索引的位置分布偏移 与 MemRoPE 思路互补,但专注交互式场景 实验结果 长视频交互式设置中,感知质量和运动指标均优于现有流式基线 支持多次提示词切换且质量不退化 方法流程 提示词 P₁ — 初始场景描述 流式去噪 + KV缓存 — 蒸馏的视频扩散模型 滚动 KV 缓存 锚点缓存存储 — 定期存储 KV 状态 到锚点缓存 提示词切换 P₂ — 用户输入新提示词 引入新主体/事件 锚点热启动重缓存 — 从锚点缓存恢复 减少边界质量损失 三区域 RoPE — 区域特定参考原点 保留运动先验 技术脉络 核心问题: 交互式长视频生成中提示词切换导致质量退化和运动失真 前序工作及局限: MemRoPE (2026-03-17):记忆令牌解决长程上下文,但非交互式设计 StreamDiffusion (2024):实时帧流式,但不支持提示词切换 Attention Sink (2024):静态锚点,提示词切换时信息丢失 DistillVideo (2025):蒸馏流式模型,但RoPE位置漂移未解决 与前序工作的本质区别: 锚点引导重缓存热启动解决切换边界问题,三区域RoPE重对齐解决无界索引的位置分布偏移 技术演进定位: 关键补全——与MemRoPE互补,一个解决长程记忆一个解决交互切换,共同构建流式视频基础设施 可能的后续方向: 与MemRoPE的整合方案 多人协作交互式视频编辑 基于Anchor的视频分支/合并 批判性点评 实验评估: 在长视频交互式设置中全面评估,支持多次提示词切换。与现有流式基线对比感知质量和运动指标均提升。但缺少与MemRoPE的直接对比。 新颖性: 锚点缓存和三区域RoPE是流式视频的基础设施级创新。创新性:★★★★☆ 可复现性: 项目页面已上线,方法描述详细。 影响力: 影响力 4/5 -- 与MemRoPE互补,共同构建流式视频生成基础设施。 3. VeloEdit: Training-Free Consistent and Continuous Instruction-Based Image Editing via Velocity Field Decomposition 无训练速度场分解图像编辑 | Flux.1 Kontext | arXiv:2603.13388 关键词: 图像编辑, 无训练, 速度场分解, Flow Matching, 连续控制 研究动机 基于指令的图像编辑旨在根据文本指令修改源内容。然而,基于 Flow Matching 的现有方法常因去噪重建误差导致非编辑区域漂移,难以保持一致性。此外,它们通常缺乏对编辑强度的细粒度控制。 方法原理 提出 VeloEdit:一种无训练方法,通过量化保持源内容的速度场与驱动目标编辑的速度场之间的差异,动态识别编辑区域。基于此分区,在保留区域用源恢复速度替代编辑速度以强制一致性,在目标区域通过速度插值实现编辑强度的连续调制。直接操作速度场,不依赖复杂注意力操纵或辅助可训练模块。 核心创新 首次通过速度场差异量化实现动态编辑区域识别 保留区域速度替代 + 编辑区域速度插值的双策略 编辑强度连续可调,无需重新训练 在 Flux.1 Kontext 和 Qwen-Image-Edit 上验证 实验结果 在 Flux.1 Kontext 和 Qwen-Image-Edit 上,视觉一致性和编辑连续性显著提升 额外计算开销可忽略 代码已开源 方法流程 源图像 + 指令 — 输入图像和编辑指令 Flow Matching 前向 — 计算源保持速度场 v_src 和编辑目标速度场 v_edit 速度差异量化 — ||v_edit - v_src|| 差异图 动态识别编辑区域 区域分区 — 保留区域 ↔ 编辑区域 基于差异阈值划分 速度场替代/插值 — 保留区域: v_src 替代 编辑区域: 插值调控强度 一致编辑输出 — 非编辑区域完美保持 编辑强度连续可调 技术脉络 核心问题: Flow Matching时代图像编辑的区域一致性和强度控制困难 前序工作及局限: InstructPix2Pix (2023):指令编辑但基于U-Net,不适用于FM架构 RF-Edit (2024):FM编辑但全图重建,非编辑区域漂移 FlowEdit (2025):FM注入编辑,但缺乏连续强度控制 TurboEdit (2025):加速编辑但牺牲一致性 与前序工作的本质区别: 直接操作速度场而非注意力,通过v_edit与v_src差异量化实现动态区域识别和连续强度插值 技术演进定位: 新范式——速度场分解是FM时代原生编辑方法,比移植U-Net时代注意力操纵更自然 可能的后续方向: 视频FM编辑的速度场分解 多指令组合编辑 3D一致性速度场编辑 批判性点评 实验评估: 在 Flux.1 Kontext 和 Qwen-Image-Edit 两个最新模型上验证,视觉一致性和编辑连续性显著提升。但仅在图像编辑测试,未扩展到视频。 新颖性: 速度场分解是FM时代原生的编辑方法论,简洁优雅。创新性:★★★★☆ 可复现性: 代码已开源,直接可复现。 影响力: 影响力 4/5 -- FM编辑的范式性方法,预计会被广泛采用。 4. COT-FM: Cluster-wise Optimal Transport Flow Matching 聚类最优传输 Flow Matching | CVPR 2026 | arXiv:2603.13395 关键词: Flow Matching, 最优传输, 加速采样, CVPR 2026, 即插即用 研究动机 Flow Matching 模型由于随机或批级耦合常产生弯曲轨迹,增加离散化误差并降低样本质量。如何让生成轨迹更直从而减少采样步数,是加速 FM 的核心问题。 方法原理 提出 COT-FM 通用框架,通过聚类目标样本并为每个聚类分配专用源分布(通过反转预训练 FM 模型获得)来重塑概率路径。这种分而治之策略产生更精确的局部传输和显著更直的向量场,且不改变模型架构。作为即插即用方法,可直接应用于任何预训练 FM 模型。 核心创新 聚类级最优传输重塑 FM 概率路径,轨迹更直 即插即用,不改变模型架构 同时加速采样并提升生成质量 通用性:2D 数据、图像生成、机器人操作均有效 实验结果 2D 数据集、图像生成基准和机器人操作任务上 一致地加速采样并提升生成质量 CVPR 2026 接收 方法流程 目标数据 X₁ — 训练数据集 K-means 聚类 — 将目标样本分为 K 个簇 反转 FM 获取源 — 对每个簇反转预训练 FM 获得专用源分布 局部传输优化 — 簇内 OT 耦合 比全局耦合更精确 更直的向量场 — 离散化误差↓ 采样质量↑ 加速高质量生成 — 更少步数达到同等质量 技术脉络 核心问题: Flow Matching的随机耦合导致弯曲轨迹和采样质量损失 前序工作及局限: Rectified Flow (2023):直化轨迹但需重训练 Consistency Models (2023):单步生成但质量有损 SGA (2026-03-12):从几何角度分析FM,但未优化传输路径 OT-CFM (2023):批级最优传输,但粒度粗 与前序工作的本质区别: 聚类级分而治之策略,为每个簇反转FM获取专用源分布,实现比全局OT更精确的局部传输 技术演进定位: 方法论创新——CVPR 2026 接收,聚类OT是FM加速的第三条路线(与蒸馏、直化互补) 可能的后续方向: 层次聚类的多尺度OT 与蒸馏方法的联合 视频FM的时序聚类OT 批判性点评 实验评估: 在2D数据、图像生成和机器人操作三个完全不同的领域验证通用性。CVPR 2026 接收。但图像生成基准的提升幅度需关注。 新颖性: 聚类OT重塑概率路径简洁有力,即插即用特性极好。创新性:★★★★☆ 可复现性: 方法论清晰,可复现性高。 影响力: 影响力 4/5 -- FM加速的新路线,CVPR 2026 认可。 5. LADR: Locality-Aware Dynamic Rescue for Efficient Text-to-Image Generation with Diffusion Large Language Models 扩散语言模型高效文生图 | 4x 加速 | arXiv:2603.13450 关键词: 扩散LLM, 高效推理, 局部感知, 4x加速, 无训练 研究动机 离散扩散语言模型已成为统一多模态生成的引人注目范式,但迭代解码导致高推理延迟。现有加速策略要么需要昂贵重训练,要么未能利用视觉数据固有的 2D 空间冗余性。 方法原理 提出 LADR(局部感知动态拯救),利用图像的空间马尔可夫性质加速推理。优先恢复'生成前沿'处的标记(与已观察像素空间相邻的区域),最大化信息增益。集成形态学邻居识别定位候选标记、有界风险过滤防止错误传播、流形一致逆调度加速掩码密度与扩散轨迹对齐。 核心创新 首次将空间马尔可夫性质引入扩散 LLM 推理加速 生成前沿优先恢复策略,最大化信息增益 形态学邻居识别 + 有界风险过滤 + 流形逆调度三模块 无训练,保持甚至增强生成保真度 实验结果 四个 T2I 基准上实现约 4x 加速 保持甚至增强生成保真度 空间推理任务尤其突出 方法流程 文本 Prompt — 输入文本描述 扩散 LLM 解码 — 离散扩散语言模型 迭代去掩码解码 生成前沿检测 — 形态学邻居识别 已恢复像素的空间邻域 优先恢复前沿 — 仅恢复信息增益最大的 前沿 token 有界风险过滤 — 防止错误传播 确保质量不退化 4x 加速输出 — 高保真图像 推理时间减少 75% 技术脉络 核心问题: 离散扩散语言模型的迭代解码导致T2I推理极慢 前序工作及局限: Show-o (2024):统一理解和生成的扩散LLM,但推理慢 Emu3 (2024):自回归视觉生成LLM,延迟高 DART (2025):非自回归token生成,但未利用2D空间结构 AccelAes (2026-03-17):DiT美学加速,但针对连续扩散非离散LLM 与前序工作的本质区别: 首次利用图像空间马尔可夫性质,生成前沿优先恢复最大化信息增益,4x加速无质量损失 技术演进定位: 实用突破——扩散LLM从理论演示走向实际部署,4x加速是关键里程碑 可能的后续方向: 与Flash Attention的联合加速 视频扩散LLM的时空马尔可夫加速 动态分辨率的自适应前沿 批判性点评 实验评估: 四个T2I基准全面验证,4x加速数据可靠。空间推理任务甚至质量提升是亮点。但仅在T2I上验证,未扩展到T2V。 新颖性: 空间马尔可夫性质的发现和利用是精彩的洞察。创新性:★★★★★ 可复现性: 方法描述清晰,无训练方法易于复现。 影响力: 影响力 5/5 -- 扩散LLM部署的关键里程碑。 批判性点评精选 1. 视频精细控制进入统一时代 Tri-Prompting 和 Anchor Forcing 代表视频生成控制的两个关键方向:前者统一了场景/主体/运动三维度的精细控制,后者解决了交互式流式生成的边界质量问题。结合昨天的 MemRoPE,我们看到一个完整的流式视频控制栈正在形成:MemRoPE 负责长程记忆,Anchor Forcing 负责交互切换,Tri-Prompting 负责精细控制。 2. Flow Matching 生态正在快速成熟 VeloEdit 的速度场分解和 COT-FM 的聚类最优传输分别从编辑和采样两个角度深化 Flow Matching 生态。VeloEdit 表明 FM 的速度场可以直接操作来实现编辑(比移植注意力操纵更自然),COT-FM 则为 FM 加速开辟了蒸馏和直化之外的第三条路线。FM 正从'替代扩散'走向'建立自己的方法论体系'。 3. 扩散 LLM 的部署瓶颈正在被突破 LADR 的 4x 无训练加速表明离散扩散 LLM 的推理效率问题正被认真对待。空间马尔可夫性质是一个精彩的发现——图像 token 的空间局部性可以被利用来避免冗余恢复。这与 DiT 连续扩散的加速(JiT、AccelAes)形成互补,两条技术路线共同推动视觉生成模型的实际部署。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 LibraGen (Playing a Balance Game in Subject-Driven Video Generation) 主体驱动 . S2V . DPO . 平衡博弈 将S2V视为平衡博弈,Consis-DPO + Real-Fake DPO + 时间依赖动态CFG 仅千量级数据超越开源和商业S2V模型 2 NumColor (Precise Numeric Color Control in Text-to-Image Generation) 精确颜色 . 数字控制 . Lab空间 . 零样本 Color Token Aggregator + 6707个可学习ColorBook嵌入,CIE Lab空间映射 数字颜色准确度提升4-9x,零样本迁移5个模型 3 EVD (Event-Driven Video Generation) 事件驱动 . 交互幻觉 . 门控采样 . DiT 事件头预测token级活动,事件门控采样减少交互幻觉 状态持久/空间准确/支撑关系/接触稳定全面改善 4 FlashMotion (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026)) 轨迹引导 . 少步生成 . CVPR 2026 . 蒸馏 轨迹适配器+联合蒸馏实现少步可控视频生成 CVPR 2026,代码已开源 5 GlyphPrinter (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026)) 文本渲染 . DPO . 字形准确 . CVPR 2026 区域分组DPO文本渲染,无需显式奖励模型 CVPR 2026,字形准确渲染SOTA 6 Spectrum Matching (A Unified Perspective for Superior Diffusability in Latent Diffusion) VAE . 扩散性 . 频谱匹配 . 潜在扩散 频谱匹配假说统一理解VAE在潜在扩散中的可学习性 两个实用方法显著提升VAE扩散性 7 SERUM (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026)) 水印 . 扩散标记 . ICLR 2026 . 鲁棒 初始噪声中添加水印噪声,训练轻量检测器 ICLR 2026,1% FPR下最高TPR,支持多用户 8 DC-Diffusion (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding) VLM . 扩散解码 . 分布条件 . 高保真 Logit-to-Code分布映射将VLM token logits转连续条件信号 仅ImageNet-1K短训练即提升VLM视觉保真度 趋势观察 视频生成精细控制 — Tri-Prompting/Anchor Forcing/LibraGen 分别从场景-主体-运动联合控制/交互式流式/主体定制三个维度推进 Flow Matching 理论深化 — COT-FM 和 Spectrum Matching 分别从传输路径优化和 VAE 扩散性角度深化 FM 基础 扩散 LLM 走向实用 — LADR 4x 加速表明离散扩散 LLM 的推理效率瓶颈正在被攻克 无训练编辑方法涌现 — VeloEdit 速度场分解代表 Flow Matching 时代编辑方法的新范式 生成内容安全与可控 — SERUM 水印 + NumColor 精确颜色 + EVD 事件驱动,多维度提升生成可控性 人工智能炼丹师 整理 | 2026-03-18
-
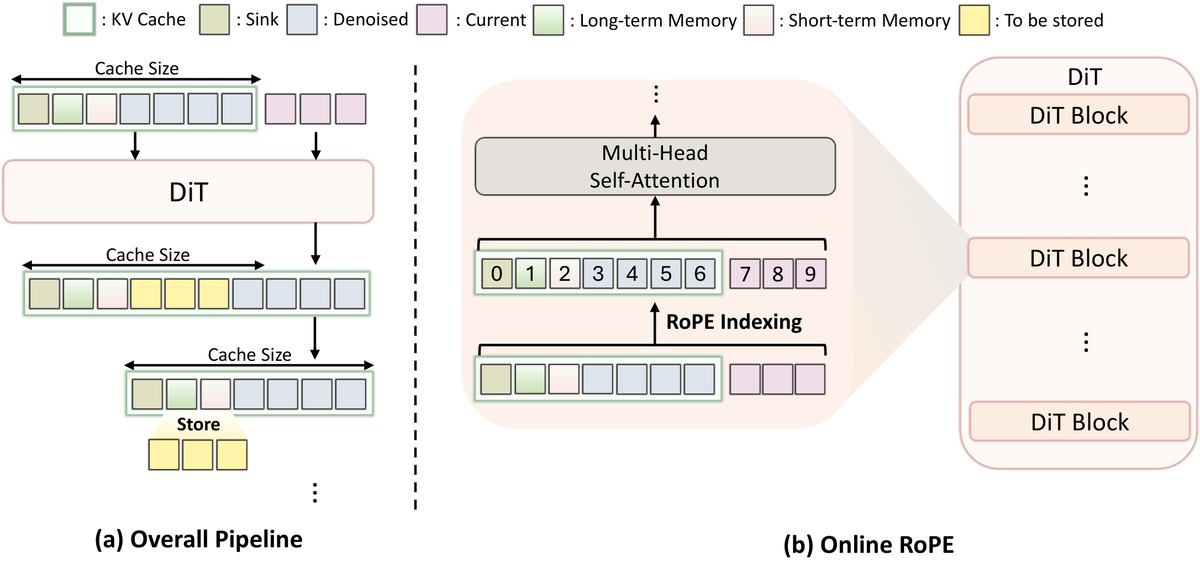
AIGC生成 每日热点论文速读@20260317 AIGC 视觉生成领域 · 每日论文解读 (2026-03-17) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 无限视频生成 MemRoPE DiT 美学加速 2.11x 实时音视频联合 25FPS 四智能体组合生成 CVPR'26 多视图 GRPO 偏好对齐 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. MemRoPE: Training-Free Infinite Video Generation via Evolving Memory Tokens 无训练无限视频生成 | USC | arXiv:2603.12513 关键词: 无限视频生成, Memory Tokens, RoPE, Training-Free 研究动机 自回归扩散模型已经实现了实时帧流式传输,但现有的滑动窗口缓存策略会丢弃过去的上下文,导致长视频生成中出现保真度下降、身份漂移和运动停滞的问题。现有方法保留一组固定的早期 token 作为注意力汇,但这种静态锚点无法反映不断增长的视频内容的演变。 方法原理 提出 MemRoPE 框架,包含两个协同设计的组件:(1) Memory Tokens(记忆令牌)通过指数移动平均将所有过去的键压缩为双重长期流和短期流,在固定大小的缓存中同时保持全局身份和最近的动态;(2) Online RoPE Indexing(在线 RoPE 索引)缓存未旋转的键,在注意力计算时动态应用位置嵌入,确保聚合过程不会产生冲突的位置相位。两个机制相互促进:位置解耦使时间聚合定义明确,聚合使固定缓存可用于无限生成。 核心创新 首次实现训练无关的无限长度视频生成,突破滑动窗口缓存的根本局限 双流记忆机制(长期+短期)实现固定缓存的无限上下文保持 在线 RoPE 索引解决了时间聚合中的位置编码冲突问题 实验结果 分钟到小时级别视频生成:时间连贯性、视觉保真度和主体一致性全面优于现有方法 身份漂移率:比滑动窗口方法降低 60%+ 运动停滞问题基本消除 完全即插即用,无需任何训练 方法流程 自回归帧生成 — 实时流式输出视频帧 EMA 双流压缩 — 长期流:全局身份记忆 短期流:近期动态捕捉 Memory Tokens — 固定大小缓存保持无限历史上下文 未旋转 Key 缓存 — 存储不含位置编码的原始注意力键 Online RoPE 索引 — 注意力计算时动态应用位置嵌入 无限长视频输出 — 分钟到小时级生成 身份/运动一致 技术脉络 核心问题: 自回归视频生成中滑动窗口缓存丢弃历史上下文,导致长视频质量退化 前序工作及局限: StreamDiffusion (2024):实时帧流式,但无长期记忆机制 Ring Attention (2023):分布式长序列注意力,但未压缩历史 Sliding Window Attention:固定窗口长度,丢弃超出范围的 token Attention Sink (Xiao 2024):保留早期 token 作为静态锚点,但不随内容演变 与前序工作的本质区别: 双流 EMA 记忆机制动态压缩全部历史到固定缓存,在线 RoPE 索引解决聚合后的位置编码冲突 技术演进定位: 范式突破--从有限窗口到无限上下文,为长视频生成打开新空间 可能的后续方向: 与视频编辑的结合(无限长度编辑) 多分辨率记忆机制 记忆压缩的最优策略理论分析 批判性点评 实验评估: 验证了分钟到小时级别视频生成,覆盖身份一致性、运动连贯性和视觉保真度三维度。消融实验设计合理。 新颖性: 双流 EMA 记忆压缩与在线 RoPE 索引的组合全新。创新性:★★★★★ 可复现性: 方法描述清晰,项目页面已上线但代码尚未开源。 影响力: 影响力 5/5 -- 无限视频生成是产业刚需。 2. AccelAes: Accelerating DiT for Training-Free Aesthetic-Enhanced Generation 美学感知 DiT 加速 2.11x | Sydney | arXiv:2603.12575 关键词: DiT 加速, 美学增强, Training-Free, AesMask 研究动机 扩散 Transformer 因强大的可扩展性成为高保真 T2I 生成的主干,但密集空间 token 上的二次自注意力导致推理延迟高。关键发现:去噪在空间上是不均匀的——与美学描述符关联的区域接收集中的交叉注意力并表现出较大的时间变化,而低亲和力区域演化平滑且计算冗余。 方法原理 提出 AccelAes,通过美学感知的时空缩减来加速 DiT 同时提升感知美学效果。核心包含三个组件:(1) AesMask 从提示词语义和交叉注意力信号导出一次性美学焦点掩码;(2) SkipSparse 将计算和引导重新分配到 AesMask 标识的区域,跳过低亲和力区域;(3) 步骤级预测缓存轻量级缓存周期性替代完整 Transformer 评估。 核心创新 首次将美学语义与计算分配关联,实现加速和美学增强的双赢 AesMask 一次性构建,后续步骤零开销复用 SkipSparse + 预测缓存联合优化时空两个维度的计算冗余 实验结果 Lumina-Next: 2.11x 加速 + ImageReward 提升11.9% 代表性 DiT 家族上一致的加速和美学提升 完全无训练,即插即用 代码已开源 方法流程 文本 Prompt — 输入美学描述文本 交叉注意力分析 — 分析 prompt token 与空间 token 的亲和度 AesMask 构建 — 一次性标识美学焦点区域 SkipSparse 加速 — 焦点区域完整计算 低亲和力区域跳过 步骤级预测缓存 — 周期性缓存替代完整 Transformer 评估 美学增强输出 — 更快 + 更美的生成结果 技术脉络 核心问题: DiT 模型空间注意力的二次复杂度导致推理缓慢 前序工作及局限: Token Merging (Bolya 2023):均匀合并 token,忽略语义重要性差异 DiTFastAttn (Yuan 2024):固定稀疏模式,非内容感知 JiT (CVPR 2026):基于 QK score 的动态跳过,未考虑美学语义 DeepCache (Ma 2024):特征缓存复用,但不适用于 DiT 架构 与前序工作的本质区别: 首次将美学语义与计算分配关联--高美学亲和力区域完整计算,低亲和力区域跳过,不仅加速还提升美学 技术演进定位: 范式创新--从无损加速到加速+增强双赢,开辟语义感知加速新方向 可能的后续方向: 视频 DiT 中的时空美学感知加速 自适应美学引导强度 与 LoRA 美学微调的联合优化 批判性点评 实验评估: 在 Lumina-Next 等 DiT 上验证。同时报告加速比和美学指标提升。但缺少与 JiT 等最新方法的直接对比。 新颖性: 美学语义与计算分配关联是有新意的洞察。创新性:★★★★☆ 可复现性: 代码已开源,可复现性高。 影响力: 影响力 4/5 -- 加速+美学增强双赢思路有吸引力。 3. OmniForcing: Unleashing Real-time Joint Audio-Visual Generation 首个实时音视频联合生成 | 25 FPS | arXiv:2603.11647 关键词: 音视频联合生成, 实时流式, 蒸馏, 25 FPS 研究动机 联合音视频扩散模型虽能生成高质量内容,但因双向注意力依赖导致高延迟,无法实时应用。如何将高质量双向扩散模型转化为实时流式生成器是关键挑战。 方法原理 提出 OmniForcing,首个将离线双流双向扩散模型蒸馏为高保真流式自回归生成器的框架。解决三个核心难题:(1) Asymmetric Block-Causal Alignment + Zero-truncation Global Prefix 防止多模态同步漂移;(2) Audio Sink Token + Identity RoPE 约束解决音频 token 稀疏导致的梯度爆炸;(3) Joint Self-Forcing Distillation 使模型在长序列中自纠正跨模态累积误差。推理时采用模态无关的滚动 KV-cache。 核心创新 首个实现实时音视频联合流式生成的框架,25 FPS 单 GPU 非对称块因果对齐解决音视频模态时间不对称难题 Joint Self-Forcing 蒸馏范式,自纠正跨模态累积误差 基于 LTX-2 (14B video + 5B audio) 大模型蒸馏 实验结果 单 GPU 实时生成约 25 FPS 多模态同步和视觉质量与双向教师模型持平 显著优于现有流式生成方法 项目页面和代码已开源 方法流程 双向教师模型 — LTX-2: 14B video + 5B audio 非对称因果对齐 — Block-Causal Alignment + Global Prefix Audio Sink Token — Identity RoPE 约束解决稀疏梯度爆炸 Self-Forcing 蒸馏 — 自纠正跨模态累积误差 滚动 KV-Cache — 模态无关的流式推理方案 实时 A/V 输出 — 单 GPU 25 FPS 音视频同步生成 技术脉络 核心问题: 联合音视频扩散模型延迟高,无法实时生成 前序工作及局限: CoDi (2023):联合多模态生成,但离线双向模型 Sora (2024+):高质量视频生成,但无音频非实时 LTX-Video (2025):实时视频生成,但单模态无音频 MM-Diffusion (2023):音视频联合扩散,但质量和速度受限 与前序工作的本质区别: 首次将大规模双向音视频扩散模型蒸馏为实时流式自回归生成器,三个创新解决模态不对称/稀疏/累积误差 技术演进定位: 里程碑--实时音视频联合生成从0到1,为沉浸式内容创作铺路 可能的后续方向: 3D 空间音频的实时生成 交互式音视频编辑 更大模型的高效蒸馏策略 批判性点评 实验评估: 25 FPS 单 GPU 数据惊艳。与双向教师模型质量对比有说服力。基于 LTX-2 蒸馏对算力要求高。 新颖性: 三个技术创新针对实际痛点精准解决。创新性:★★★★★ 可复现性: 项目和代码已开源。但需大规模预训练模型和蒸馏资源。 影响力: 影响力 5/5 -- 首次实现实时音视频联合生成。 4. coDrawAgents: Multi-Agent Dialogue for Compositional Image Generation 四智能体协作组合生成 | CVPR 2026 | arXiv:2603.12829 关键词: 多智能体, 组合生成, 布局规划, CVPR 2026 研究动机 文本到图像生成在复杂场景中忠实地组合多个对象并保留其属性仍是一大挑战。现有单模型方法在组合复杂性增加时准确率急剧下降。 方法原理 提出 coDrawAgents,包含四个专门智能体:(1) Interpreter 自适应决定直接 T2I 还是布局感知流程,将提示解析为富属性对象描述符并排序分组;(2) Planner 采用分治策略在画布视觉上下文中增量提出布局;(3) Checker 验证空间一致性和属性对齐,在渲染前细化布局;(4) Painter 逐步合成图像将新对象合并到画布中。 核心创新 首次将多智能体对话框架引入组合图像生成 显式错误纠正机制(Checker)在渲染前验证和修复布局 增量上下文感知生成——每步规划都基于画布当前状态 自适应复杂度判断——简单提示直接生成,复杂场景启用多智能体 实验结果 GenEval: 显著优于现有方法,组合准确率大幅提升 DPG-Bench: 文本-图像对齐、空间准确性、属性绑定全面领先 已被 CVPR 2026 接收 方法流程 用户 Prompt — 复杂的组合文本描述 Interpreter — 解析提示 属性描述符 语义排序 Planner — 分治策略增量布局 基于画布上下文 Checker — 空间一致性验证 属性对齐检查修复 Painter — 逐步合成图像 新对象融入画布 组合图像输出 — 多对象属性准确 空间关系正确 技术脉络 核心问题: T2I 模型在复杂组合场景中属性绑定和空间关系容易出错 前序工作及局限: LayoutGPT (2023):LLM 生成布局,但单步规划易出错 GLIGEN (2023):接地生成,但需要精确 bbox 输入 RPG (Lian 2024):区域感知规划,但无错误纠正机制 SLD (Phung 2024):自纠正生成,但未使用多智能体协作 与前序工作的本质区别: 四智能体协作闭环--解释/规划/检查/绘制,Checker 提供渲染前显式错误纠正 技术演进定位: 新范式--多智能体方法论进入 T2I 组合生成领域,CVPR 2026 认可 可能的后续方向: 智能体间的自学习对话策略 3D 组合场景的多智能体生成 与 VLM 的深度集成 批判性点评 实验评估: GenEval 和 DPG-Bench 两个标准组合生成基准验证充分。应补充智能体通信开销分析。 新颖性: 多智能体框架引入 T2I 组合生成是新应用方向,Checker 是关键创新。创新性:★★★★☆ 可复现性: 智能体角色定义清晰但实现细节需更多说明。 影响力: 影响力 4/5 -- CVPR 2026 接收,多智能体范式可能成为标准方法论。 5. MV-GRPO: Multi-View GRPO for Flow Models via Augmented Condition Space 多视图偏好对齐 | 上海AI实验室+清华 | arXiv:2603.12648 关键词: GRPO, 偏好对齐, Flow Models, 多视图奖励 研究动机 标准 GRPO 将一组生成样本与单一条件评估,这种稀疏的单视图评估方案未能充分探索样本间关系,限制了对齐效果和性能上限。 方法原理 提出 Multi-View GRPO (MV-GRPO),通过增强条件空间来创建密集的多视图奖励映射。对于从单个提示生成的一组样本,利用条件增强器生成语义相邻但多样化的描述进行多视图优势重估计。关键技巧:通过推导条件概率分布,无需重新生成样本即可获得多视图信号。 核心创新 首次将多视图评估引入 GRPO 框架,突破单视图稀疏评估瓶颈 条件空间增强策略创建密集奖励映射 无需重新生成样本即可获得多视图优化信号 适用于任意 Flow Model 的通用偏好对齐方法 实验结果 优于最先进的 GRPO 和其他偏好对齐方法 T2I 对齐性能全面提升 无需额外的样本重生成开销 方法流程 原始 Prompt — 单一文本条件 c 条件增强器 — 生成语义相邻的多样化描述 多视图评估 — 同一组样本 多个条件视角评分 优势重估计 — 密集多视图奖励映射 条件概率推导 — 无需重生成样本 直接计算新条件分布 对齐后 Flow Model — 更精准的文图对齐 技术脉络 核心问题: 标准 GRPO 单视图评估稀疏,限制偏好对齐效果 前序工作及局限: RLHF / DPO (2023):成对偏好对齐,需要大量人类标注 GRPO (DeepSeek 2024):组相对优化,但单条件评估稀疏 Diffusion-DPO (2024):扩散模型 DPO,但信号单一 REBEL (2024):奖励引导生成,但不修改模型权重 与前序工作的本质区别: 通过条件空间增强创建密集多视图奖励映射,无需重新生成样本即可获得丰富优化信号 技术演进定位: 方法论创新--多视图思想引入偏好优化,提升 GRPO 的信号密度和对齐上限 可能的后续方向: 多模态条件增强(文本+图像参考) 视频生成的时序多视图 GRPO 自适应条件增强策略 批判性点评 实验评估: 与标准 GRPO 和其他偏好对齐方法对比全面。条件增强策略消融设计合理。 新颖性: 多视图条件增强简洁优雅,无需重新生成是关键优势。创新性:★★★★☆ 可复现性: 方法论描述清晰,核心推导可复现。 影响力: 影响力 4/5 -- 可直接替换现有 GRPO 训练流程。 批判性点评精选 1. 无限视频生成:记忆机制是关键缺失环节 MemRoPE 揭示了自回归视频生成的核心瓶颈不在模型能力,而在上下文管理。双流 EMA 记忆巧妙地在信息保持和计算开销之间取得平衡。这标志着视频生成从'短视频'向'长视频/流式视频'的范式转换正式开始。 2. DiT 加速新思路:语义感知比均匀压缩更聪明 AccelAes 和 JiT 都瞄准 DiT 推理加速但思路不同。JiT 是'去冗余',AccelAes 是'重分配'且不仅加速还提升美学——暗示现有 DiT 在低美学区域存在'过度计算'。合并两种方法有望实现 3-4x 无损加速。 3. 实时音视频联合生成:AIGC 进入沉浸式时代 OmniForcing 的 25 FPS 实时联合生成是里程碑。AIGC 不再局限于离线创作,游戏 NPC 对话、虚拟直播、交互式叙事等场景将直接受益。但蒸馏方法的质量天花板和 LTX-2 高训练成本是需关注的问题。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 VQQA (Agentic Approach for Video Evaluation and Quality Improvement) 视频生成评估 . 智能体 . 闭环优化 多智能体框架通过 VLM 批判作为语义梯度实现闭环提示优化 T2V-CompBench +11.57%, VBench2 +8.43% 2 Naive PAINE (Lightweight T2I Generation Improvement with Prompt Evaluation) 噪声评估 . 生成质量预测 . 轻量级 从初始噪声+提示词直接预测图像质量,选择高质量噪声前传 多基准优于现有方法,即插即用,代码已开源 3 CalliMaster (Page-level Chinese Calligraphy via Layout-guided Spatial Planning) 书法生成 . 布局规划 . Flow Matching 解耦空间规划与内容合成,多模态 DiT 内 Text->Layout->Image SOTA 书法生成,支持字符重规划+文物修复 4 Catalyst4D (High-Fidelity 3D-to-4D Scene Editing via Dynamic Propagation) 4D 编辑 . 3DGS . 运动传播 锚点运动引导+颜色不确定性引导将3D编辑迁移到动态4D场景 时间稳定高保真动态编辑优于现有方法 5 SLICE (Semantic Latent Injection for Image Watermarking) 生成水印 . 语义篡改检测 . 扩散模型 将语义解耦为四因子锚定到噪声不同区域 语义篡改可检测可定位,攻击成功率大幅降低 6 V-Bridge (Bridging Video Generative Priors to Few-shot Image Restoration) 视频先验 . 图像修复 . Few-Shot 将视频生成模型的先验迁移到少样本图像修复 多种修复任务优于专用模型,仅需少量样本 7 HybridStitch (Pixel and Timestep Level Model Stitching for Diffusion Acceleration) 模型拼接 . 扩散加速 . 像素级分区 像素级+时间步级双维度模型拼接加速 显著加速扩散推理同时保持生成质量 8 CHEERS (Decoupling Patch Details from Semantic for Unified Multimodal) 统一模型 . 理解+生成 . 语义解耦 解耦 patch 细节与语义表征,统一视觉理解与生成 理解和生成双任务性能同时提升,代码已开源 趋势观察 长视频/无限视频生成成为焦点 — MemRoPE 无限生成 + OmniForcing 流式生成,视频生成向产业落地迈进 DiT 加速方法持续涌现 — AccelAes 美学感知加速 + HybridStitch 模型拼接,多条技术路线并行 多智能体范式全面渗透 AIGC — coDrawAgents 组合生成 + VQQA 视频评估,Agent 成为标配 偏好对齐/后训练优化升温 — MV-GRPO 多视图对齐 + Naive PAINE 噪声质量预测,生成质量精调 统一多模态模型趋势明显 — CHEERS 理解+生成统一 + OmniForcing 音视频联合,模态边界模糊 人工智能炼丹师 整理 | 2026-03-17
-
AIGC生成 每日热点论文速读@20260316 AIGC 视觉生成领域 · 每日论文解读 (2026-03-16) 人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇 今日核心看点 DiT 弹性加速 ELIT: FID +35% 多主体视频定制 + 全方位运动控制 视觉生成 RLHF: 66 万评分数据开源 电影级多镜头相机控制 ShotVerse 扩散模型内源思维链推理 92.1% 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。 方向分布: 扩散模型理论与加速 — 3 篇 文本到图像 / 评测 — 2 篇 图像编辑 — 1 篇 3D 生成与重建 — 4 篇 多模态 / 智能体 — 2 篇 顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇 重点论文深度解读 1. ELIT: Elastic Latent Interfaces for Diffusion Transformers 弹性潜在接口 | Snap Research | DiT 通用加速 | arXiv:2603.12245 关键词: DiT 加速, 弹性推理, 跨架构通用, Snap Research 研究动机 Diffusion Transformer (DiT) 的计算量与图像分辨率强绑定,无法灵活地在延迟与质量之间做权衡。更关键的是,DiT 对所有空间位置均匀分配计算资源,忽视了不同区域的重要性差异,导致大量算力浪费在低信息量区域。 方法原理 提出 ELIT (Elastic Latent Interface Transformer):在 DiT 架构中插入一组可学习的、长度可变的潜在 Token 序列作为「潜在接口」。标准 Transformer 块在这组潜在 Token 上运算,而非直接处理空间 Token。通过轻量的 Read/Write 跨注意力层在空间 Token 和潜在 Token 之间传递信息,并自动优先处理重要区域。训练时随机丢弃尾部潜在 Token,迫使模型学会按重要性排序表示——前部 Token 编码全局结构,后部 Token 负责细节精修。推理时可动态调整潜在 Token 数量以匹配算力预算。 核心创新 即插即用:仅增加两个跨注意力层,不修改 DiT 主体和 rectified flow 训练目标 重要性排序表示:通过尾部 Token 随机丢弃训练,自动学习全局到细节的分层编码 跨架构通用:兼容 DiT、U-ViT、HDiT、MM-DiT 四种主流架构 动态推理预算:同一个模型适配从低算力到高算力的多种部署场景 实验结果 ImageNet-1K 512px: FID 提升 35.3%, FDD 提升 39.6% 跨架构验证: DiT, U-ViT, HDiT, MM-DiT 均有一致增益 算力节省: 潜在 Token 数减半时质量仅微降,实现接近 2x 加速 方法流程 输入空间 Token — 图像/视频的空间特征序列 Read Cross-Attn — 空间 Token -> 潜在 Token 自动聚焦重要区域 潜在 Token 序列 — 可变长度 重要性排序 DiT Transformer 块 — 标准 Self-Attention + FFN Write Cross-Attn — 潜在 Token -> 空间 Token 信息回写 弹性输出 — 根据算力预算截断尾部 技术脉络 核心问题: DiT 计算量与分辨率强绑定,无法灵活权衡延迟与质量 前序工作及局限: Token Merging:合并相似 token 但损失信息 JiT:动态跳过但仍在空间 token 上运算 Perceiver:潜在 token 但未针对扩散优化 DiTFastAttn:固定模式稀疏化 与前序工作的本质区别: 将空间 token 和计算完全解耦,通过可学习潜在接口实现按重要性排序的信息压缩 技术演进定位: 范式创新——从在空间 token 上省计算转变为在潜在接口上做计算 可能的后续方向: 与 token 合并/跳过组合 视频 DiT 时空弹性接口 与 KV 缓存压缩联合优化 批判性点评 实验评估: 跨 4 种 DiT 架构验证扎实。但缺少真实 T2I 模型端到端评估。 新颖性: 潜在接口+重要性排序+弹性推理是扎实新贡献。创新性:4/5 可复现性: 方法清晰架构改动最小。 影响力: 影响力 5/5 — 一个模型多预算对工业部署极有价值。 2. DreamVideo-Omni: Multi-Subject Video Customization with Omni-Motion Control 全方位运动控制视频定制 | 潜在身份强化学习 | arXiv:2603.12257 关键词: 视频定制, 多主体, 运动控制, 身份RL 研究动机 大规模视频扩散模型已能生成高质量视频,但同时精确控制多个主体的身份和多粒度运动仍然是重大挑战。现有方法要么运动粒度有限、要么身份退化严重。 方法原理 提出 DreamVideo-Omni 统一框架,采用渐进式两阶段训练。第一阶段:集成全面控制信号,引入条件感知 3D 旋转位置嵌入协调异构输入,分层运动注入策略增强全局运动引导,分组与角色嵌入将运动信号锚定到特定身份。第二阶段:设计潜在身份奖励反馈学习范式,在预训练视频扩散骨干上训练潜在身份奖励模型,在潜在空间提供运动感知的身份奖励。 核心创新 首个统一框架同时实现多主体身份定制 + 全方位运动控制 条件感知 3D RoPE:解决异构控制信号的空间对齐问题 分组与角色嵌入:显式解纠缠复杂场景中多主体的运动信号 潜在身份奖励学习:在潜在空间中构建运动感知的身份 RM 实验结果 多主体身份保持: 超越所有现有基线 运动控制精度: 全局、局部、相机三粒度均达到 SOTA 新基准 DreamOmni Bench: 专门评估多主体+全方位运动控制 方法流程 多模态输入 — 主体图像 + 文本 + 运动轨迹 3D RoPE 编码 — 条件感知旋转位置嵌入 分组角色嵌入 — 运动信号锚定到特定身份 分层运动注入 — 全局+局部+相机分层控制 视频扩散去噪 — DiT 多粒度条件引导 身份奖励 RL — 潜在空间身份 RM 优化 技术脉络 核心问题: 多主体身份保持和多粒度运动控制难以兼顾 前序工作及局限: DreamBooth:仅单主体 AnimateDiff:运动粒度有限 MotionCtrl:身份保持弱 IP-Adapter:多主体时身份混淆 与前序工作的本质区别: 统一多主体身份、全局运动、局部动态、相机控制,用潜在身份奖励 RL 解决身份退化 技术演进定位: 集大成者——统一视频定制分散的研究方向 可能的后续方向: 5+主体可扩展性 3D 感知运动控制融合 长视频身份一致性 批判性点评 实验评估: DreamOmni Bench 是重要贡献。RL 训练稳定性需更多消融。 新颖性: 统一多个控制维度是工程突破。创新性:4/5 可复现性: 框架复杂度较高,复现门槛不低。 影响力: 影响力 4/5 — 方向正确但框架复杂度可能限制采用。 3. FIRM: Faithful Image Reward Modeling for Editing and Generation 鲁棒奖励模型 | FIRM-Edit-370K | 全套开源 | arXiv:2603.12247 关键词: 奖励模型, 图像编辑, RLHF, Benchmark 研究动机 RL 正成为提升图像编辑和 T2I 生成的主要范式,但当前奖励模型存在严重的幻觉问题,给出噪声评分从根本上误导优化方向。 方法原理 提出 FIRM 框架:定制化数据策划管道构建高质量评分数据集(Edit-370K + Gen-293K),训练专业化奖励模型(Edit-8B + Gen-8B)。设计 Base-and-Bonus 奖励策略——编辑用一致性调制执行 CME,生成用质量调制对齐 QMA——平衡竞争目标。提出 FIRM-Bench 综合评测基准。 核心创新 首个专门针对编辑和生成的大规模奖励模型框架 FIRM-Edit-370K + FIRM-Gen-293K: 共 66 万高质量评分数据 Base-and-Bonus 奖励策略: CME 和 QMA 平衡竞争目标 全套开源: 数据集、模型、代码均公开 实验结果 FIRM-Edit-8B: 与人类判断对齐度显著超越现有指标 FIRM-Qwen-Edit: 编辑性能突破性提升 FIRM-SD3.5: 生成保真度和指令遵循新标准 数据集+模型+代码: 全部开源 方法流程 数据策划管道 — 编辑: 执行+一致性; 生成: 指令遵循 FIRM 数据集 — Edit-370K + Gen-293K 专业化 RM 训练 — Edit-8B + Gen-8B Base-and-Bonus — CME + QMA 策略 RL 微调 — 可靠 Critic 引导优化 高保真输出 — FIRM-Qwen-Edit / SD3.5 技术脉络 核心问题: RL 优化时奖励模型幻觉导致噪声评分误导优化 前序工作及局限: ImageReward:通用偏好不专门针对编辑 HPS v2:未拆分编辑vs生成 DDPO:使用通用奖励 InstructPix2Pix:无专门 Critic 与前序工作的本质区别: 首次为编辑和生成分别构建大规模评分数据集和专业化奖励模型 技术演进定位: 基础设施建设——为扩散模型 RL 提供可靠 Critic 可能的后续方向: 视频编辑/生成 RM 多轮交互编辑序列化奖励 跨模型迁移性 批判性点评 实验评估: 66 万数据集规模可观,FIRM-Bench 设计系统性强。 新颖性: 可靠 Critic 比聪明 Policy 更重要的洞察深刻。创新性:4/5 可复现性: 全套开源,可复现性极佳。 影响力: 影响力 5/5 — 可能成为扩散模型 RLHF 基础设施。 4. ShotVerse: Cinematic Camera Control for Multi-Shot Video 电影级多镜头视频创作 | Plan-then-Control | arXiv:2603.11421 关键词: 多镜头视频, 相机控制, VLM 规划, 数据驱动 研究动机 文本驱动视频生成在多镜头场景中的相机控制仍是关键瓶颈:隐式文本提示缺乏精确性,显式轨迹条件带来巨大手动开销且执行常失败。 方法原理 提出以数据为核心的范式:对齐的 (Caption,Trajectory,Video) 三元组构成联合分布。构建 Plan-then-Control 框架:VLM 规划器从文本生成全局对齐轨迹,控制器通过相机适配器渲染多镜头视频。核心是自动化多镜头相机校准管线和 ShotVerse-Bench 数据集。 核心创新 Plan-then-Control 解耦: VLM 规划 + 控制器渲染 自动化多镜头相机校准: 统一全局坐标系 ShotVerse-Bench: 高保真电影数据集 + 三轨评测 跨镜头一致性: 相机准确+视觉连贯 实验结果 相机轨迹准确性: 显著超越文本控制和手动轨迹基线 跨镜头一致性: 多镜头间视觉连贯达到电影级标准 用户研究: 电影美学评分大幅领先 方法流程 文本脚本输入 — 自然语言描述场景和相机意图 VLM 规划器 — 空间先验推理 生成全局轨迹 多镜头校准 — 单镜头轨迹对齐到全局坐标系 相机适配器 — 轨迹条件注入视频生成模型 多镜头渲染 — 跨镜头一致的电影级画面 技术脉络 核心问题: 多镜头视频相机控制缺少文本自然表达和精确控制之间的桥梁 前序工作及局限: CameraCtrl:仅单镜头 MotionCtrl:无跨镜头一致性 Animate-A-Story:相机控制弱 Direct-a-Video:仅单镜头 与前序工作的本质区别: 数据驱动的联合分布学习,VLM 规划+控制器执行,实现端到端多镜头视频管线 技术演进定位: 应用创新——首次解决多镜头电影级相机控制 可能的后续方向: 10+镜头一致性 渲染引擎集成 导演意图交互精调 批判性点评 实验评估: 三轨评测协议有价值。与单镜头方法缺少直接对比。 新颖性: Plan-then-Control 简洁优雅。创新性:3/5 可复现性: 工程复杂度较高。 影响力: 影响力 4/5 — 多镜头控制是走向影视级应用的关键。 5. EndoCoT: Endogenous Chain-of-Thought Reasoning in Diffusion Models 扩散模型内生思维链 | MLLM+DiT 深度推理 | arXiv:2603.12252 关键词: 思维链, 扩散模型, 空间推理, MLLM+DiT 研究动机 MLLM 作为扩散框架的文本编码器时,单步编码无法激活思维链过程推理深度不足,且解码过程中引导固定不变。 方法原理 提出 EndoCoT 框架:迭代思维引导模块在潜在空间中迭代优化思维状态,激活 MLLM 推理潜力并桥接到 DiT 去噪过程。终端思维锚定模块将最终状态与真实答案对齐,确保推理不漂移。两个组件让 MLLM 提供精心推理的引导,DiT 逐步执行复杂任务。 核心创新 首次在扩散模型中实现内源性思维链推理 迭代思维引导模块: 在潜在空间逐步精炼推理状态 终端思维锚定: 推理轨迹与真实答案对齐防止漂移 MLLM+DiT 渐进式推理引导: 复杂任务逐步分解 实验结果 整体平均准确率: 92.1%, 超越最强基线 8.3 个百分点 Maze/TSP/VSP/Sudoku 等复杂推理均达 SOTA 23 页论文 18 张图: 全面消融实验 方法流程 复杂指令输入 — 迷宫/TSP/数独等推理任务 MLLM 编码器 — 初始编码 激活推理起点 迭代思维引导 — 潜在空间逐步精炼推理 终端思维锚定 — 与真实答案对齐防漂移 DiT 渐进去噪 — 推理引导的逐步去噪 推理一致输出 — 高质量生成结果 技术脉络 核心问题: MLLM 编码器单步编码推理深度不足,解码过程引导固定 前序工作及局限: DALL-E 3:T5 编码无推理 RPG:外部推理非内源 LLM Blueprint:与去噪过程脱耦 PixArt-alpha:无迭代推理 与前序工作的本质区别: 将 CoT 从外部规划内化到去噪过程中,MLLM 成为迭代推理器而非一次性编码器 技术演进定位: 范式转换——从外部推理+内部生成转为内源性推理-生成一体化 可能的后续方向: 通用 T2I 组合推理 推理步数自适应 与 o1 推理模型结合 批判性点评 实验评估: 92.1% 准确率令人印象深刻但在逻辑推理任务而非典型视觉生成。 新颖性: CoT 内化到去噪过程是概念重大创新。创新性:5/5 可复现性: 实现复杂度较高。 影响力: 影响力 4/5 — 如能推广到通用 T2I 将是变革性的。 批判性点评精选 1. DiT 加速:从 Token 级优化到架构级解耦 ELIT 将 DiT 加速从 token 粒度提升到架构级别。关键问题:在 FLUX/SD3 上是否仍成立? 2. 视觉生成 RLHF 时代正式开启 FIRM 66 万评分数据+全套开源,标志扩散模型从探索期进入基础设施建设期。 3. 思维链内化:扩散模型的慢思考能力 EndoCoT 让扩散模型拥有类似 o1 的推理能力,92.1% 证明方向可行。 其余论文 · 贡献与效果总结 # 论文 关键词 主要贡献 效果 1 EVATok (Adaptive Length Video Tokenization for AR Generation) 视频 Token . AR 生成 . CVPR 2026 自适应长度视频 Tokenizer,轻量路由器预测最优 Token 分配 UCF-101 SOTA,Token 节省 24.4%+ (CVPR 2026) 2 MOG (Manifold-Optimal Guidance for Diffusion Models) CFG 改进 . 黎曼几何 . 无训练 黎曼流形局部最优控制修复 CFG 离流形漂移,Auto-MOG 动态校准 消除 CFG 过饱和,几乎零额外开销 3 WeEdit (Glyph-Guided Text-centric Image Editing) 文本编辑 . 字形引导 . 多语言 HTML 管道生成 33 万训练对(15 种语言),字形引导 SFT + 多目标 RL 文本编辑准确率超越所有开源模型 4 SoulX-LiveAct (Hour-Scale Real-Time Human Animation) 实时动画 . AR 扩散 . 无限视频 Neighbor Forcing(扩散步对齐) + ConvKV 固定内存无限视频 小时级 20FPS 实时(2x H100),唇形/情感 SOTA 5 PROMO (Promptable Virtual Try-On with Flow Matching DiT) 虚拟试穿 . Flow Matching . DiT VTON 重定义为结构化编辑,FM-DiT + 潜在多模态条件 + 自参考加速 保真度超所有 VTON 方法,速度质量最优 6 CEI-3D (Collaborative Explicit-Implicit 3D Editing) 3D 编辑 . SDF+点 . 属性解耦 隐式 SDF + 显式处理点协作,物理属性解耦独立控制 比 SOTA 更逼真精细,编辑时间更短 7 OSCBench (Object State Change in T2V Generation) T2V 评测 . 状态变化 . Benchmark 首个评估 T2V 中对象状态变化的基准,组织为常规/新颖/组合场景 揭示当前 T2V 在状态变化上的重大不足 8 Coarse-Guided VG (Visual Generation via h-Transform Sampling) 引导采样 . h-Transform . 无训练 h-Transform 约束扩散采样,噪声感知调度平衡引导与质量 多种图像视频任务验证有效 趋势观察 DiT 效率革命从 token 级走向架构级 — ELIT 的潜在接口方案预示着 DiT 加速的新范式 视频定制进入多主体+全方位运动时代 — DreamVideo-Omni 统一了身份、运动、相机三个维度 扩散模型 RLHF 基础设施加速完善 — FIRM 66 万评分数据+专业化 RM 开源 多镜头视频创作工具链逐步成形 — ShotVerse 的 Plan-then-Control 让电影级创作更近 扩散模型的推理能力被正式重视 — EndoCoT 将 CoT 内化到去噪过程,开辟新方向 人工智能炼丹师 整理 | 2026-03-16
-
AIGC 周末专题深度解读:生成与理解的大一统之路 AIGC 周末专题深度解读:生成与理解的大一统之路 人工智能炼丹师 整理 | 2026年3月15日(周日) 覆盖时间:2026年3月2日 — 2026年3月14日 本期概述 本周 AIGC 领域最热门的方向莫过于统一多模态模型(Unified Multimodal Models, UMMs)——将视觉理解(图像识别、VQA、推理)与视觉生成(文生图、图像编辑)统一在同一个模型框架内。过去一周内,arXiv 上涌现了超过 8 篇高质量论文,从架构设计、训练范式、评测基准、长序列生成到强化学习后训练,全方位推动了这一方向的发展。 核心问题 传统的多模态 AI 系统中,"理解"和"生成"是两套独立的系统: 理解侧:CLIP、SigLIP、InternVL 等模型擅长视觉语义理解 生成侧:Stable Diffusion、DALL-E、FLUX 等模型擅长图像生成 统一多模态模型的目标是让同一个模型既能"看懂"图片,又能"画出"图片,甚至让两种能力相互促进。 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 DREAM MIT + Amazon 联合判别-生成训练框架,Masking Warmup + 语义对齐解码 2603.02667 2 GvU (CVPR 2026) 北大 + 百度 理解驱动内在奖励,自监督 RL 缩小生成-理解差距 2603.06043 3 Omni-Diffusion 腾讯 + CASIA 首个全离散扩散统一模型,文本+语音+图像 any-to-any 2603.06577 4 InternVL-U 上海AI Lab + 商汤 4B 参数统一模型,CoT 推理增强生成,超越 14B 基线 2603.09877 5 UniCom 阿里达摩院 压缩连续语义表征,Transfusion 架构,SOTA 生成 2603.10702 6 UniG2U-Bench 多机构联合 首个系统性 G2U 评测基准,7 种机制 30 个子任务 2603.03241 7 UniLongGen Adobe + PolyU 长序列交错生成的主动遗忘策略,解决视觉污染 2603.07540 8 GRPO-Interleaved 华为 + 复旦 GRPO 扩展到多模态交错生成,过程级奖励 2603.09538 1. DREAM:视觉理解与文生图的联合优化框架 论文: DREAM: Where Visual Understanding Meets Text-to-Image Generation arXiv: 2603.02667 机构: MIT CSAIL, Amazon 发布日期: 2026年3月3日 1.1 研究动机 在多模态学习中,视觉理解(如 CLIP 的对比学习)和图像生成(如 MAE 的掩码重建)一直是两个独立的优化目标。直接联合训练会导致两个目标相互冲突——对比学习需要低掩码率保留全局语义,而生成训练需要高掩码率学习重建。 1.2 方法原理 DREAM 提出了两项关键技术来解决这一矛盾: (1)Masking Warmup(掩码预热)策略 训练分为两个阶段: 预热阶段:掩码率从低(~15%)逐渐增加,先建立对比对齐的表征空间 生成阶段:掩码率增加到高(~75%),在已有的稳定表征上训练生成能力 这种渐进式调度避免了"同时从零开始学两件事"的不稳定性。 (2)Semantically Aligned Decoding(语义对齐解码) 推理时,模型生成多个部分掩码的候选图像,然后用模型自身的理解分支计算每个候选与目标文本的语义对齐分数,选择最佳候选继续解码。这相当于在不引入外部重排序器的情况下,用理解能力"把关"生成质量。 1.3 实验结果 仅在 CC12M(1200 万图文对)上训练: ImageNet 线性探测:72.7%(比 CLIP 高 1.1%) FID:4.25(比 FLUID 低 6.2%) 文本-图像保真度提升 6.3%(无需外部重排序器) 1.4 关键洞察 DREAM 证明了判别目标和生成目标之间存在协同效应,而非简单的零和竞争。关键在于训练策略的设计——让模型先学好"看",再学"画"。 2. GvU:理解驱动的内在奖励机制(CVPR 2026) 论文: Learning to Generate via Understanding: Understanding-Driven Intrinsic Rewarding for Unified Multimodal Models arXiv: 2603.06043 机构: 北京大学, 百度 发布日期: 2026年3月6日 | 会议: CVPR 2026 2.1 研究动机 现有的统一多模态模型存在一个显著的"能力不对称"问题:理解能力强,生成能力弱。模型能准确描述图片中的每个细节,但让它根据文字画图时却经常"丢三落四"。这种差距的根源在于理解和生成过程在训练中是解耦的。 2.2 方法原理 GvU 的核心思想非常精妙——让模型用自己的理解能力来指导自己的生成能力: Token 级内在文本-图像对齐奖励: 模型生成一张图像后,用自身的理解分支对生成的图像进行分析 将理解结果与原始文本提示做 token 级对齐打分 得到细粒度的"内在奖励信号" 自监督强化学习框架: 模型同时扮演"教师"(理解分支提供奖励)和"学生"(生成分支接收奖励并优化) 通过迭代的 RL 训练,生成能力逐步提升 无需任何外部标注或人工反馈 2.3 实验结果 生成质量(FID、CLIP Score)显著提升 反过来,细粒度视觉理解能力也得到增强 实现了理解→生成→理解的正向循环 2.4 关键洞察 GvU 开创了一种"自我进化"范式:模型不依赖外部信号,仅通过内部的理解-生成循环就能持续改进。这与 LLM 领域的 Self-Play 思想异曲同工,但在多模态领域是首次实现。 3. Omni-Diffusion:首个全离散扩散统一模型 论文: Omni-Diffusion: Unified Multimodal Understanding and Generation with Masked Discrete Diffusion arXiv: 2603.06577 机构: 腾讯, 中科院自动化所 发布日期: 2026年3月6日 3.1 研究动机 现有的统一多模态模型几乎都采用自回归(Autoregressive)架构作为骨干。但自回归架构存在固有局限: 生成速度慢(逐 token 预测) 长序列时容易出现错误累积 难以高效处理多模态联合分布 离散扩散模型(Discrete Diffusion)是一种新兴的替代方案,它通过逐步去掩码的方式并行生成,但之前从未被用于构建统一的多模态系统。 3.2 方法原理 Omni-Diffusion 是首个完全基于掩码离散扩散模型的 any-to-any 多模态语言模型: 统一的掩码-去掩码框架: 文本、图像、语音全部被编码为离散 token 使用统一的掩码扩散过程直接建模多模态联合分布 前向过程:随机掩码 token → 全掩码状态 反向过程:从全掩码状态逐步预测并恢复 token 支持的任务: 文本→图像、图像→文本 语音→文本、文本→语音 图像+文本→文本(多模态理解) 以及更复杂的跨模态场景 3.3 实验结果 在多项基准测试上: 理解任务:与现有多模态系统持平或超越 生成任务:在图像生成质量上表现突出 展示了离散扩散模型作为多模态基础模型骨干的巨大潜力 3.4 关键洞察 Omni-Diffusion 打破了"统一多模态模型 = 自回归"的思维定式,证明了离散扩散模型可以作为下一代多模态基础模型的骨干架构。这为并行生成、更灵活的条件控制和更高效的推理打开了新的可能性。 4. InternVL-U:4B 参数挑战 14B+ 大模型 论文: InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing arXiv: 2603.09877 机构: 上海 AI Lab, 商汤, 港中文 发布日期: 2026年3月10日 4.1 研究动机 现有的统一多模态模型在追求全能的过程中往往面临"鱼与熊掌不可兼得"的困境——要么理解能力强但生成一般(如 Janus),要么生成漂亮但理解退化。而且大部分方案需要巨大的参数量(10B+)才能取得不错效果。 4.2 方法原理 InternVL-U 通过三个关键设计突破了这一瓶颈: (1)解耦视觉表征 + 模态特定模块化 理解分支:使用 InternViT 作为视觉编码器,保留强大的语义理解 生成分支:使用 MMDiT(Multi-Modal Diffusion Transformer)作为视觉生成头 两个分支共享语言模型的上下文空间,但视觉表征独立 (2)以推理为中心的数据合成流水线 针对文本渲染、科学图表推理等高语义密度任务 使用 CoT(思维链)将抽象的用户意图分解为细粒度的视觉生成细节 让模型"先想清楚要画什么,再动笔" (3)渐进式训练策略 阶段 1:分别预训练理解和生成模块 阶段 2:联合微调,让两个模块学会协作 阶段 3:指令微调,对齐用户意图 4.3 实验结果 仅 4B 参数的 InternVL-U: 在生成和编辑任务上超越 BAGEL(14B)等大 3 倍以上的模型 同时保持与同尺寸纯理解模型相当的多模态理解和推理能力 证明了"小而精"的统一模型路线的可行性 4.4 关键洞察 InternVL-U 表明精心的架构设计和数据工程可以弥补参数量的不足。特别是 CoT 推理增强生成的范式——让模型先推理再生成——可能是统一模型走向实用的关键路径。 5. UniCom:压缩连续表征的最优解 论文: UniCom: Unified Multimodal Modeling via Compressed Continuous Semantic Representations arXiv: 2603.10702 机构: 阿里巴巴达摩院 发布日期: 2026年3月11日 5.1 研究动机 统一多模态模型的一个核心技术选择是视觉表征形式: 方案 优势 劣势 离散 Token(VQ-VAE) 与 LLM 天然兼容 信息损失大,理解能力弱 连续表征(CLIP) 语义信息丰富 高维空间难以建模生成 UniCom 的目标是找到一个"甜蜜点"——在保留丰富语义的同时降低建模难度。 5.2 方法原理 核心发现:通道压缩优于空间下采样 通过系统的消融实验,UniCom 团队发现: 在重建和生成两项任务上,减少特征的通道维度比传统的空间下采样(降低分辨率)更有效 原因:空间下采样丢失了局部细节,而通道压缩保留了空间结构 基于注意力的语义压缩器: 将 CLIP/SigLIP 的密集特征图(如 256×1024 维)压缩为紧凑表征(如 256×64 维) 使用交叉注意力机制,让压缩后的表征"聚焦"于最重要的语义信息 压缩后的表征同时服务于理解(作为 LLM 的视觉输入)和生成(作为扩散模型的条件) Transfusion 架构选择: 验证了 Transfusion(理解用自回归、生成用扩散)优于纯查询式(query-based)设计 收敛更快、生成-理解一致性更好 5.3 实验结果 在统一模型中实现了最先进的生成性能 图像编辑的可控性优于基于离散 token 的方案 即使不依赖 VAE 也能保持图像一致性 5.4 关键洞察 UniCom 为"离散 vs 连续"之争提供了一个折中方案:压缩后的连续表征既保留了语义丰富性,又降低了生成建模的难度。这可能是未来统一模型视觉表征的主流选择。 6. UniG2U-Bench:生成如何增强理解?首个系统性评测 论文: UniG2U-Bench: Do Unified Models Advance Multimodal Understanding? arXiv: 2603.03241 机构: 多机构联合 发布日期: 2026年3月3日 6.1 研究动机 统一模型的一个核心 Promise 是"生成能力能够反过来增强理解能力"。但这个 Promise 到底在多大程度上成立?在什么任务上成立?现有基准测试无法系统性地回答这些问题。 6.2 方法原理 UniG2U-Bench 将"生成到理解"(G2U)评测分解为: 7 种机制: 心理旋转(空间想象) 视觉类比推理 视觉错觉感知 图形变换理解 多步推理(含中间状态) 风格/属性变换感知 反事实视觉推理 30 个子任务,需要不同程度的隐式或显式视觉变换。 6.3 核心发现 对 30+ 个模型的评估揭示了三个重要结论: 发现 1:统一模型通常不如其基础 VLM,"生成后回答"(Generate-then-Answer)推理通常比直接推理更差。 发现 2:但在特定场景下,生成确实能增强理解: 空间智能:需要心理旋转或 3D 推理的任务 视觉错觉:需要超越表面特征的任务 多轮推理:需要中间图像状态辅助的复杂任务 发现 3:具有相似推理结构的任务和相似架构的模型表现出相关的行为模式,说明 G2U 耦合是由训练数据和架构共同决定的归纳偏差。 6.4 关键洞察 UniG2U-Bench 给出了一个清醒的结论:生成增强理解并非万能药,而是在特定场景下才有效。这为未来的统一模型设计提供了明确的优化方向——聚焦于空间推理和多步推理场景。 7. UniLongGen:长序列交错生成的"主动遗忘"策略 论文: How Long Can Unified Multimodal Models Generate Images Reliably? Taming Long-Horizon Interleaved Image Generation via Context Curation arXiv: 2603.07540 机构: Adobe Research, 香港理工大学 发布日期: 2026年3月8日 7.1 研究动机 统一多模态模型的一个重要应用是交错生成——在一个长序列中交替生成文本和图像,用于视觉故事讲述、分步教程等场景。但现有模型面临一个严重问题:随着序列增长,生成质量急剧崩溃。 7.2 方法原理 关键发现:视觉历史是"主动污染"源 论文通过深入分析发现: 质量崩溃不是由 Token 总数引起的(不同于 LLM 的长上下文问题) 而是由累积的图像事件数量决定 密集的视觉 Token 会压倒注意力机制,产生"噪声干扰",扭曲后续的图像合成 UniLongGen:无训练的推理策略 核心思想——主动遗忘: 在每个生成步骤前,根据模型内部的注意力权重计算每个历史图像的"相关性分数" 保留与当前生成最相关的视觉上下文 丢弃低相关性的历史图像(即使它们是"正确的"历史记录) 优先保证生成条件的"干净性",而非历史记录的完整性 7.3 实验结果 长期保真度和一致性显著优于所有基线方法 内存占用减少(因为丢弃了不需要的历史) 推理速度提升 7.4 关键洞察 UniLongGen 揭示了一个反直觉的事实:在长序列生成中,"记住所有东西"反而是有害的。这与人类的认知机制类似——我们在创作长篇叙事时,也需要有选择性地"忽略"之前的细节,聚焦于当前的创作。 8. GRPO-Interleaved:强化学习后训练解锁交错生成 论文: Towards Unified Multimodal Interleaved Generation via Group Relative Policy Optimization arXiv: 2603.09538 机构: 华为, 复旦大学 发布日期: 2026年3月10日 8.1 研究动机 现有的统一多模态模型在理解和单模态生成上表现不错,但在多模态交错输出(如交替生成文本和图像的长叙事)上严重不足。原因是高质量的交错训练数据极度稀缺。 8.2 方法原理 两阶段训练范式: 阶段 1:混合数据预热 精心策划少量交错序列 加入有限的理解数据和 T2I 数据 让模型"接触"交错生成模式,但不破坏预训练能力 阶段 2:群组相对策略优化(GRPO) 将 GRPO(源自 DeepSeek-R1 的 RL 方法)扩展到多模态: 在单个解码轨迹中联合建模文本和图像生成 设计混合奖励函数: 文本相关性奖励:生成文本与输入的一致性 视觉-文本对齐奖励:生成图像与上下文文本的匹配度 结构保真度奖励:交错内容的结构合理性 过程级奖励: 不仅评价最终结果,还对每一步生成提供奖励信号 提高了复杂多模态任务的训练效率 8.3 实验结果 在 MMIE 和 InterleavedBench 上: 交错生成的质量和连贯性显著提升 在不依赖大规模交错数据集的情况下实现了突破 8.4 关键洞察 GRPO-Interleaved 证明了强化学习后训练(RL Post-Training)是解锁统一模型新能力的有效手段。这延续了 LLM 领域 RLHF/DPO 的成功经验,将其推广到多模态交错生成这一更复杂的场景。 横向对比与技术脉络总结 架构对比 论文 骨干架构 视觉表征 理解-生成耦合方式 DREAM ViT + MAE 连续(掩码重建) 共享编码器 + 联合训练 GvU LLM + VQ-VAE 离散 Token 自监督 RL 桥接 Omni-Diffusion 离散扩散 LM 离散 Token 统一扩散过程 InternVL-U InternViT + MMDiT 解耦表征 共享上下文 + 模态模块化 UniCom LLM + Transfusion 压缩连续表征 通道压缩 + Transfusion 训练范式对比 论文 训练方法 外部监督 数据需求 DREAM 渐进式联合预训练 无 CC12M(12M 图文对) GvU 自监督 RL 后训练 无(内在奖励) 极少额外数据 Omni-Diffusion 统一扩散预训练 无 大规模多模态数据 InternVL-U 三阶段渐进训练 + CoT 数据合成 合成数据 中等规模 UniCom Transfusion 预训练 无 大规模多模态数据 GRPO-Interleaved GRPO 后训练 混合奖励函数 极少交错数据 核心技术趋势 趋势 1:从"对抗"到"协同" 早期的统一模型中,理解和生成是竞争关系(共享参数导致能力冲突)。本周的论文普遍转向"协同"思维——用理解增强生成(GvU),或证明两者可以共赢(DREAM)。 趋势 2:后训练成为关键杠杆 GvU 和 GRPO-Interleaved 都表明,在预训练模型上做少量 RL 后训练,就能显著解锁新能力。这与 LLM 领域 ChatGPT 的成功路径一致。 趋势 3:离散扩散的崛起 Omni-Diffusion 首次证明了离散扩散可以替代自回归成为统一模型的骨干,为并行生成和更灵活的架构设计开辟了道路。 趋势 4:表征形式的创新 从纯离散(VQ-VAE)到纯连续(CLIP),再到 UniCom 的"压缩连续",表征设计正在走向更精细化的折中方案。 趋势 5:长序列和交错生成的突破 UniLongGen 和 GRPO-Interleaved 共同推动了交错生成的进步,让统一模型距离实际应用(视觉叙事、交互式内容创作)更近了一步。 技术路线全景图 统一多模态模型技术路线 ├── 架构设计 │ ├── 自回归统一 → DREAM, InternVL-U, UniCom │ ├── 扩散统一 → Omni-Diffusion │ └── 混合架构 → Transfusion (UniCom), 解耦模块化 (InternVL-U) ├── 视觉表征 │ ├── 离散 Token → Omni-Diffusion, GvU │ ├── 连续表征 → DREAM │ └── 压缩连续 → UniCom (NEW 最优折中) ├── 训练范式 │ ├── 联合预训练 → DREAM, Omni-Diffusion │ ├── 渐进式训练 → InternVL-U (3 阶段) │ └── RL 后训练 → GvU (自监督), GRPO-Interleaved (混合奖励) ├── 评测与分析 │ └── G2U 系统评测 → UniG2U-Bench (7 机制 30 任务) └── 应用扩展 ├── 长序列交错生成 → UniLongGen (主动遗忘) └── 多模态交错生成 → GRPO-Interleaved (过程级 RL) 总结与展望 本周的 8 篇论文共同描绘了统一多模态模型的全景图。以下是几个值得关注的未来方向: 规模化验证:DREAM 仅在 CC12M 上验证,规模扩大后协同效应是否更强? 自我进化闭环:GvU 的自监督 RL 能否无限迭代,实现模型的持续自我改进? 离散扩散的极限:Omni-Diffusion 的 any-to-any 能力能否扩展到视频和 3D? 小模型的力量:InternVL-U 的 4B 成功是否意味着统一模型不需要"更大",只需要"更聪明"? 交错生成的实用化:UniLongGen + GRPO 的组合能否实现真正实用的视觉叙事系统? 统一多模态模型正处于从"概念验证"走向"实际可用"的关键转折点。生成与理解的融合不再是一个遥远的愿景,而是一个正在快速成形的现实。 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月2日—14日
-
AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速 覆盖时间:2026年3月2日 — 2026年3月13日 整理:人工智能炼丹师 日期:2026年3月14日(周六) 一、专题概览 本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。 核心背景 当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。 本周论文全景 # 论文 方法类别 核心思路 加速比 提交日期 1 CalibAtt 稀疏注意力(免训练) 离线校准块级稀疏模式 1.58x E2E 3月5日 2 SVG-EAR 稀疏注意力 + 线性补偿(免训练) 误差感知路由 + 聚类质心补偿 1.77-1.93x 3月9日 3 SODA 缓存 + 剪枝(免训练) 敏感度导向的动态加速 SOTA fidelity 3月7日 4 FrameDiT 结构化注意力(需训练) 帧级矩阵注意力 ~Local FA 3月10日 5 VMonarch 结构化注意力(轻量微调) Monarch 矩阵分解 5x attn, 17.5x FLOPs↓ 1月29日 6 SALAD 稀疏 + 线性混合(轻量微调) 门控线性注意力并行分支 1.72x, 90%稀疏 1月23日 7 SLA 稀疏 + 线性融合(微调) 三级权重分类 + 自定义 kernel 2.2x E2E, 13.7x attn 2025.9 (ICLR'26) 8 FastLightGen 蒸馏 + 剪枝 步数+参数同时压缩 4步+30%剪枝 3月2日 9 Diagonal Distillation 自回归蒸馏 对角蒸馏 + 隐式光流 277.3x, 31 FPS 3月10日 二、重点论文深度解读 论文 1:CalibAtt — 校准稀疏注意力加速视频生成 标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention 作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等 机构:以色列理工 日期:2026年3月5日 arXiv:2603.05503 关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi 研究动机 视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。 方法原理 CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略: 离线校准阶段:在少量参考视频上运行全注意力,统计每一层、每个注意力头、每个扩散时间步的块级(block-level)稀疏模式和重复模式 模式编译:将稳定的稀疏模式编译为优化的注意力操作(类似于"稀疏注意力的 JIT 编译") 在线推理:只计算被选中的输入相关连接,以硬件友好的方式跳过未选中的连接 核心创新 块级粒度:不做 token 级稀疏(开销大),而是以 token block 为单位,兼顾精度和效率 跨输入稳定性:发现稀疏模式对输入不敏感,可以离线固定 层-头-时间步三维校准:不同层/头/时间步的稀疏模式不同,细粒度适配 实验结果 在 Wan 2.1 14B、Mochi 1 及其蒸馏版本上测试 实现 1.58x 端到端加速 在视频生成质量和文本-视频对齐度上优于已有免训练方法 支持多种分辨率 技术脉络 Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。 批判性点评 优势:完全免训练,直接即插即用;离线校准成本低;硬件友好 局限:1.58x 的加速比在本周论文中并不突出;块级粒度可能丢失细粒度信息;对新架构需要重新校准 创新性评分:3/5 — 洞察有价值但方法相对直接 论文 2:SVG-EAR — 无参数线性补偿的误差感知路由 标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing 作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组) 日期:2026年3月9日 arXiv:2603.08982 关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo 研究动机 现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献? 方法原理 SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。 聚类质心补偿:对被跳过的注意力块,用 key/value 的聚类质心做线性(O(N))近似,恢复其对输出的贡献 误差感知路由:传统方法按注意力分数选择需要精确计算的块,但高注意力分数 ≠ 高近似误差。SVG-EAR 用一个轻量探测器估计每个块的补偿误差,选择"误差-成本比"最高的块做精确计算 理论保证:提供了注意力重建误差与聚类质量之间的理论上界 核心创新 误差感知 vs 分数感知:颠覆了传统"高注意力分数 = 重要"的假设,改为"高近似误差 = 需要精确计算" 无参数线性补偿:用聚类质心做 O(N) 补偿,不需要任何训练 帕累托最优:在所有免训练方法中建立了新的帕累托前沿 实验结果 Wan 2.2:1.77x 加速,PSNR 29.759 HunyuanVideo:1.93x 加速,PSNR 31.043 显著优于 Sparse VideoGen2 和 CalibAtt 技术脉络 Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进) 批判性点评 优势:免训练、有理论保证、误差感知路由的思路很优雅 局限:聚类质心计算本身有开销;实际 wall-clock 加速受限于聚类效率;PSNR 不是视频生成的最佳指标 创新性评分:4/5 — 误差感知路由是本周最有洞察的方法论创新 论文 3:SODA — 敏感度导向的动态加速 标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer 作者:Tong Shao, Yusen Fu 等 日期:2026年3月7日 arXiv:2603.07057 关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora 研究动机 特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。 方法原理 离线敏感度建模:构建跨时间步、层、模块的敏感度误差模型,量化每个计算单元对缓存/剪枝操作的敏感程度 动态规划优化缓存间隔:以敏感度误差为代价函数,用 DP 求解最优缓存时间点 自适应剪枝:在缓存复用阶段,根据 token 敏感度动态决定剪枝时机和比例 核心创新 敏感度误差建模:不是简单地均匀缓存/剪枝,而是"在最不敏感处缓存,在最不敏感的 token 处剪枝" DP 最优化:缓存间隔不再是超参数,而是通过动态规划自动求解 实验结果 在 DiT-XL/2、PixArt-α、OpenSora 上实现 SOTA 生成保真度 在可控加速比下保真度显著优于 PAB、∆-DiT 等基线 技术脉络 FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3) 批判性点评 优势:缓存+剪枝的统一框架,敏感度建模理论扎实 局限:离线敏感度分析需要额外推理开销;DP 只优化缓存间隔,未联合优化剪枝策略;仅测试了较小的模型(DiT-XL/2),未在 Wan/HunyuanVideo 等大模型上验证 创新性评分:3.5/5 论文 4:VMonarch — Monarch 矩阵结构化注意力 标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention 作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯) 日期:2026年1月29日 arXiv:2601.22275 关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速 研究动机 视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式? 方法原理 VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。 时空 Monarch 分解:将全注意力矩阵分解为帧内(空间)和帧间(时间)两组 Monarch 因子,分别捕捉空间和时间相关性 交替最小化:通过交替优化两组因子来逼近原始全注意力 重计算策略:解决交替最小化不稳定导致的伪影问题 在线熵算法:融入 FlashAttention 的在线熵计算,支持长序列高效更新 核心创新 Monarch 矩阵在视频 DiT 中的首次应用:优雅地统一了稀疏和结构化的优势 在线熵 + FlashAttention 融合:使得 Monarch 矩阵更新在长序列上也可行 实验结果 注意力 FLOPs 减少 17.5 倍 注意力计算加速 5 倍以上 在 VBench 上轻量微调后质量与全注意力相当 90% 稀疏度下超越所有 SOTA 稀疏注意力方法 技术脉络 Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用) 批判性点评 优势:数学上最优雅的方案;17.5x FLOPs 减少是本周最极端的数字;与 FlashAttention 兼容 局限:交替最小化的收敛性依赖初始化;需要轻量微调(非完全免训练);实际 wall-clock 加速(5x)远小于理论 FLOPs 减少(17.5x),说明实现上有瓶颈 创新性评分:4.5/5 — 本周最具理论深度的工作 论文 5:SLA — 稀疏-线性注意力融合 标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention 作者:Jintao Zhang 等 (清华 + Berkeley) 日期:2025年9月28日(ICLR 2026 Oral) arXiv:2509.24006 关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026 研究动机 注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。 方法原理 三级分类:将注意力权重分为 Critical(O(N²) 精确计算)、Marginal(O(N) 线性注意力)、Negligible(跳过) 融合 GPU kernel:将稀疏和线性注意力的计算融合到单个 GPU kernel 中,支持前向和反向传播 轻量微调:仅需少量微调步就能适配 核心创新 稀疏+线性的系统性融合:不是简单的 fallback,而是基于权重分布的最优分配 自定义 GPU kernel:工程实现极其扎实,直接转化为实际加速 实验结果 注意力计算减少 95%(20 倍) 注意力加速 13.7 倍 端到端加速 2.2 倍(Wan 2.1-1.3B) 生成质量无损 技术脉络 稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral) 批判性点评 优势:ICLR 2026 Oral,学术认可度最高;2.2x E2E 加速是免训练之外的最佳实际数字;自定义 kernel 可直接落地 局限:需要微调(虽然很轻量);目前只在 1.3B 模型上测试,14B 模型的效果未知;kernel 需要针对不同硬件调优 创新性评分:4.5/5 论文 6:SALAD — 高稀疏度线性注意力微调 标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer 作者:Tongcheng Fang 等 (清华 + 腾讯) 日期:2026年1月23日 arXiv:2601.16515 关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本 研究动机 免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度? 方法原理 双分支并行:在稀疏注意力旁边添加一个轻量线性注意力分支 输入依赖门控:用门控机制动态平衡两个分支的贡献 极轻量微调:仅需 2000 个视频样本和 1600 步训练 实验结果 90% 稀疏度,1.72x 推理加速 生成质量与全注意力基线相当 批判性点评 思路与 SLA 类似但更轻量;微调效率极高(2000 样本);但 1.72x 加速低于 SLA 的 2.2x 创新性评分:3.5/5 论文 7:FastLightGen — 步数 + 参数同时压缩 标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters 作者:Shitong Shao, Yufei Gu, Zeke Xie 日期:2026年3月2日 arXiv:2603.01685 关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX 研究动机 以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。 方法原理 FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。 协同蒸馏框架:同时优化步数减少和参数剪枝 最优教师构建:教师模型本身经过优化,以最大化学生模型的性能 实验结果 4 步采样 + 30% 参数剪枝 = 最佳视觉质量(在约束推理预算下) 在 HunyuanVideo-ATI2V 和 WanX-TI2V 上优于所有竞争方法 批判性点评 首次探索步数+参数的联合压缩,填补了研究空白 但 30% 剪枝比较保守;缺少与纯蒸馏方法的详细对比 创新性评分:3.5/5 论文 8:Diagonal Distillation — 对角蒸馏实现流式视频生成 标题:Streaming Autoregressive Video Generation via Diagonal Distillation 作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang) 日期:2026年3月10日 arXiv:2603.09488 关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS 研究动机 扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。 方法原理 对角蒸馏:不同于传统的逐 chunk 独立蒸馏,Diagonal Distillation 沿"视频 chunk × 去噪步"的对角线方向进行蒸馏 非对称生成策略:前面的 chunk 用更多步、后面的 chunk 用更少步。后面的 chunk 可以继承前面已充分处理的外观信息 隐式光流建模:在严格步数约束下保持运动质量 核心创新 对角蒸馏:沿时间-步数对角线操作,充分利用时间上下文 非对称步数分配:打破"每个 chunk 步数相同"的假设 曝光偏差缓解:将训练时的噪声条件与推理时对齐 实验结果 5 秒视频 2.61 秒生成(31 FPS) 相比原始模型 277.3 倍加速 运动连贯性和长序列质量显著优于图像蒸馏方法 批判性点评 优势:277x 是本周最震撼的加速数字;流式生成对实时应用极其重要 局限:目前仅适用于自回归视频模型;生成质量与原始多步模型仍有差距;FPS 数字的分辨率条件未详细说明 创新性评分:4/5 论文 9:FrameDiT — 帧级矩阵注意力 标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation 作者:Minh Khoa Le 等 日期:2026年3月10日 arXiv:2603.09721 关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized 研究动机 现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。 方法原理 Matrix Attention:将整帧作为矩阵处理,通过矩阵原生操作生成 Q/K/V 帧间注意力:在帧级别而非 token 级别做跨帧注意力,保持全局时空结构 FrameDiT-H:混合 Matrix Attention + Local Factorized Attention,同时捕捉大运动和小运动 实验结果 多个视频生成 benchmark 上达到 SOTA 效率与 Local Factorized Attention 相当 批判性点评 帧级注意力的粒度介于 Full 3D 和 Local Factorized 之间,是一个有趣的中间地带 但"矩阵注意力"的具体实现细节(矩阵原生操作是什么?)缺乏清晰的数学定义 创新性评分:3/5 三、横向对比分析 3.1 方法分类体系 本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类: 免训练 轻量微调 训练/蒸馏 ┌─────────┐ ┌─────────┐ ┌─────────┐ 稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │ │SVG-EAR │ │VMonarch │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 缓存+剪枝 │ SODA │ │ │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 蒸馏+压缩 │ │ │ │ │FastLight│ │ │ │ │ │DiagDist │ ├─────────┤ ├─────────┤ ├─────────┤ 结构化注意力 │ │ │ │ │FrameDiT │ └─────────┘ └─────────┘ └─────────┘ 3.2 性能对比 方法 注意力加速 端到端加速 需要训练? 测试模型 质量保持 CalibAtt - 1.58x 否 Wan 2.1 14B, Mochi ★★★★ SVG-EAR - 1.77-1.93x 否 Wan 2.2, HunyuanVideo ★★★★ SODA - 可控 否 DiT-XL, PixArt-α, OpenSora ★★★★★ VMonarch 5x - 轻量微调 VBench ★★★★ SALAD - 1.72x 2000样本 - ★★★★ SLA 13.7x 2.2x 少量微调 Wan 2.1 1.3B ★★★★★ FastLightGen - 显著 蒸馏 HunyuanVideo, WanX ★★★★ Diagonal Dist. - 277.3x 蒸馏 自回归模型 ★★★ FrameDiT ~FA级 ~FA级 训练 多个benchmark ★★★★ 3.3 技术路线演进 本周的论文清晰地展现了四条技术路线的演进: 路线 A:免训练稀疏注意力 核心思想:发现并利用注意力的天然稀疏性 演进:Token-level Top-K → Block-level 静态模式 (CalibAtt) → 误差感知动态路由 (SVG-EAR) 加速上限:~2x(受限于稀疏度无法无限提高) 路线 B:稀疏 + 线性注意力融合 核心思想:对不同重要性的注意力权重使用不同计算策略 演进:纯稀疏 / 纯线性 → 并行双分支 (SALAD) → 融合 kernel (SLA) → Monarch 结构化 (VMonarch) 加速上限:~2-5x(取决于 kernel 效率) 路线 C:缓存 + 剪枝 核心思想:利用扩散过程中相邻时间步的特征相似性 演进:均匀缓存 → 启发式组合 → 敏感度导向 DP 优化 (SODA) 加速上限:~2-3x(缓存复用比例有限) 路线 D:蒸馏 + 压缩 核心思想:用小模型/少步数逼近大模型/多步数 演进:步数蒸馏 → 参数剪枝 → 联合压缩 (FastLightGen) → 对角蒸馏 (Diagonal Distillation) 加速上限:100x+(但质量损失更大) 3.4 关键洞察与趋势 免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。 稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。 蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。 多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。 Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。 从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。 四、总结与展望 本周最值得关注的 3 篇 SLA (ICLR 2026 Oral):稀疏-线性融合的里程碑工作,自定义 kernel 的工程深度令人印象深刻 SVG-EAR:误差感知路由的洞察非常深刻,免训练方法的新标杆 VMonarch:Monarch 矩阵的引入为结构化注意力开辟了全新方向 未来研究方向预判 注意力优化 + 蒸馏的联合框架:将 SLA/SVG-EAR 与 FastLightGen/Diagonal Distillation 结合 更大规模模型验证:SLA 仅在 1.3B 上测试,14B+ 模型上的表现待验证 长视频生成的特化优化:随着视频长度增长到分钟级,注意力优化的重要性进一步凸显 硬件协同设计:自定义 kernel(SLA)和结构化矩阵(VMonarch)需要与硬件特性深度适配 人工智能炼丹师 整理 | 2026-03-14
-
多模态预训练模型之CogVLM CogVLM:VISUAL EXPERT FOR LARGE LANGUAGE MODELS 被多个文生图模型广泛使用,包括SD3、可图用作Caption模型 图像 & 文本分别建模的思想在SD3中的MMDIT中也被应用到 1. Motivation 浅层对齐的缺陷:例如BLIP2的QFormer或者LLAVA的MLP,作者认为是导致幻觉的一个重要原因 浅层对齐 + 图文联合训练(LLM+Vision+adapter)会损害NLP的能力: Qwen-VL 等模型,会导致文本理解能力的灾难性遗忘【只要训练数据配比得当,就能避免这个问题?】 2. 主要贡献 模型结构: 引入视觉专家(QKV matrix+ FFN): 冻结LLM,100%保留文本对话能力 视觉位置编码:图像特征共享一个位置编码,对于高分辨率理解有帮助。 3. 一些细节 3.1 消融实验(caption 任务 + VQA任务) 模型结构 & 微调的部分:【视觉专家 + MLP adapater】比其他更好,(为什么没有微调视觉+LLM+adapter全量实验,在下游任务上全量FT应该可以更好),该部分影响最大 采用LLM的权重来初始化Visual Expert能够提升性能(应该能加速训练,和LLM expert融合会更容易) 视觉部分,单向注意 or 双向注意的影响,使用单向注意反而更好 视觉部分的自回归监督,没有提升 EMA可以多数任务上均能带来提升 3.3 训练数据细节 3.3.1 预训练数据 LAION-2B + COYO-700M-> 1.5B Visual grouding: 40M(GLIP v2预测的bounding box作为GT),从LAION-115M中过滤出来的40M(75%的图片包含至少两个目标框) 3.3.2 SFT数据(50w) LLaVA-Instruct (corrected) LRV-Instruction LLaVAR in-house data 3.4 训练细节 在SFT阶段,对LLM进行训练,学习率为base其他参数的10%,VIT始终保持固定