
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

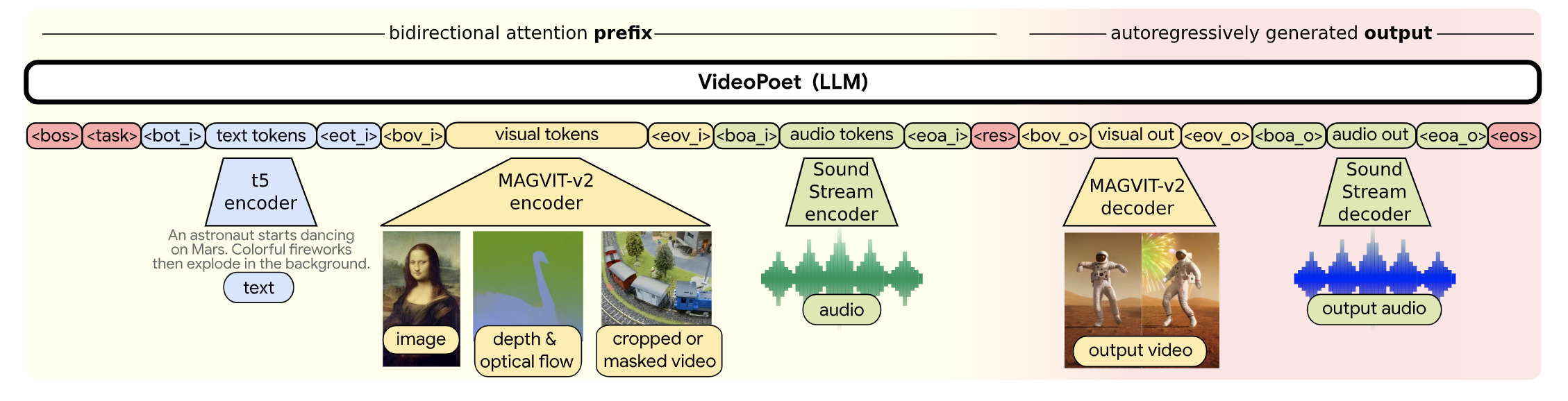
用扩散模型还是LLM做视觉生成?:LLM相比于Diffusion的优势,基设好,模型架构统一,多任务友好。但是当前主流的视觉生成还是以扩散模型为主,主要的原因在于训练一个基础模型的成本很高,以SD开源模型为代表。基于开源SD进行优化实现成本小很多,通过各种adapter在下游任务做适配。扩散模型对于任意多模态生成不利于统一(比如,如何用扩散模型做QA问答?),LLM会更友好。


评论 (0)