
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

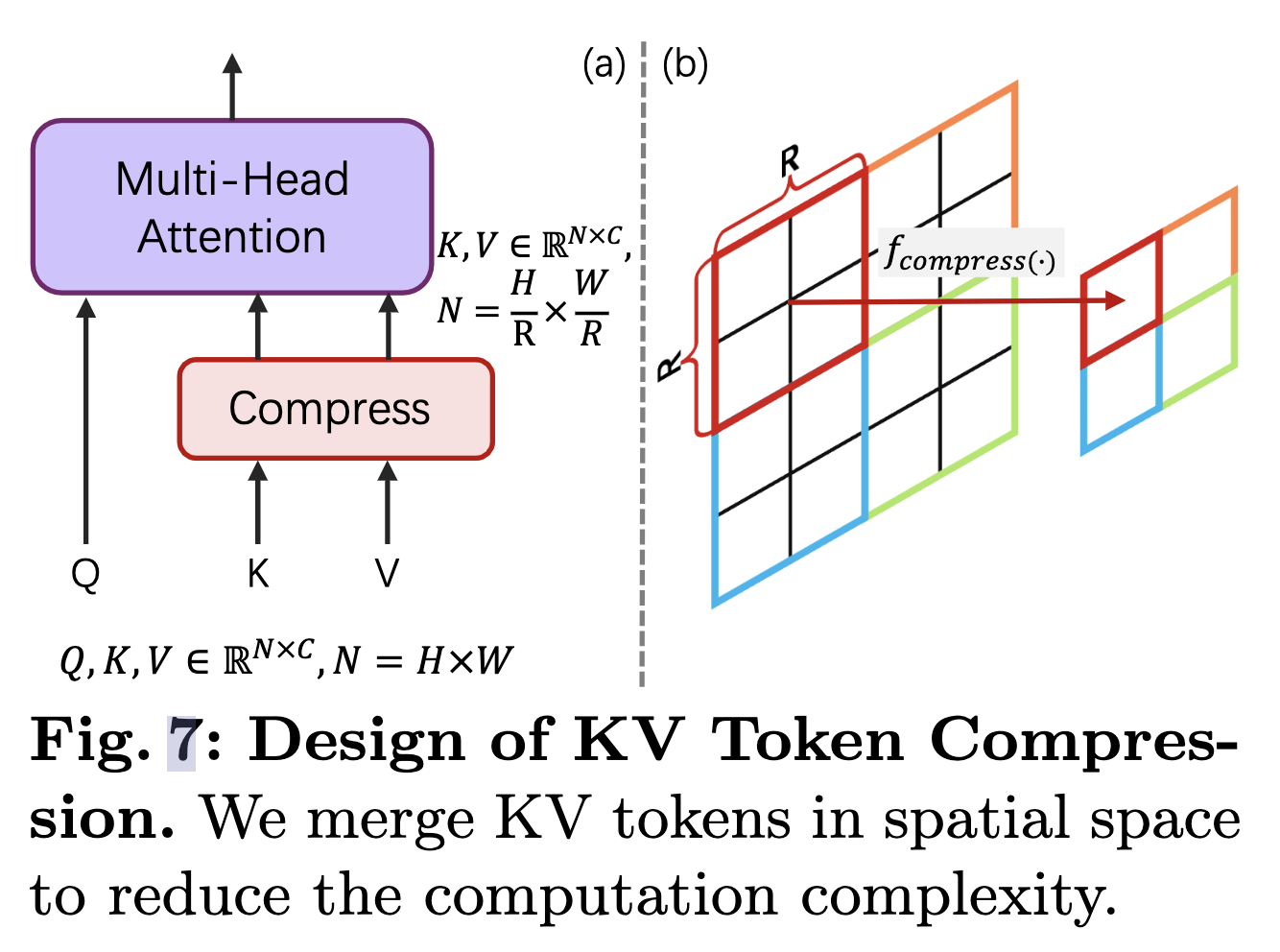
高分辩率图像生成: Transformer架构中序列越长,计算复杂度是O(n^2),越长的分辨率,对于计算推理时间和训练成本来说就越高。如何实现更好更快的生成是一大难点。
高质量的图文对数据:爬虫图文对在图片质量和文本质量上都存在问题,不够美观,图文相关性弱。利用MLLM进行recaption通常会出现幻觉问题,提升MLLM的精度对于图文一致性非常重要。
从弱到强的训练策略:对于低分辨率训练模型、vae模型切换,从已经训练好的base模型,继承之前的训练权重,如何更好的迁移到新模型非常重要,节约训练成本。
高分辩率图像生成
高质量的图文对数据
从弱到强的训练策略:

评论 (0)