
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

本文主要围绕DeepFake相关工作和近期文本/图像生成模型和强化学习结合的Reward函数设计两方面展开调研

【CVPR 2020】【Adobe Research】CNN-generated images are surprisingly easy to spot... for now
Motivation:提升真假鉴别器在不同数据集上的泛化性,实验分析影响模型泛化性的因素
Method & Results:
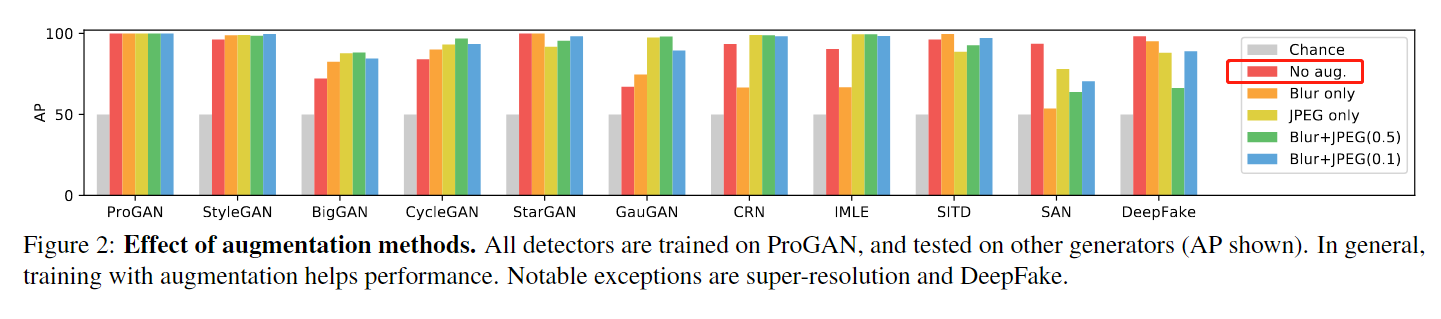

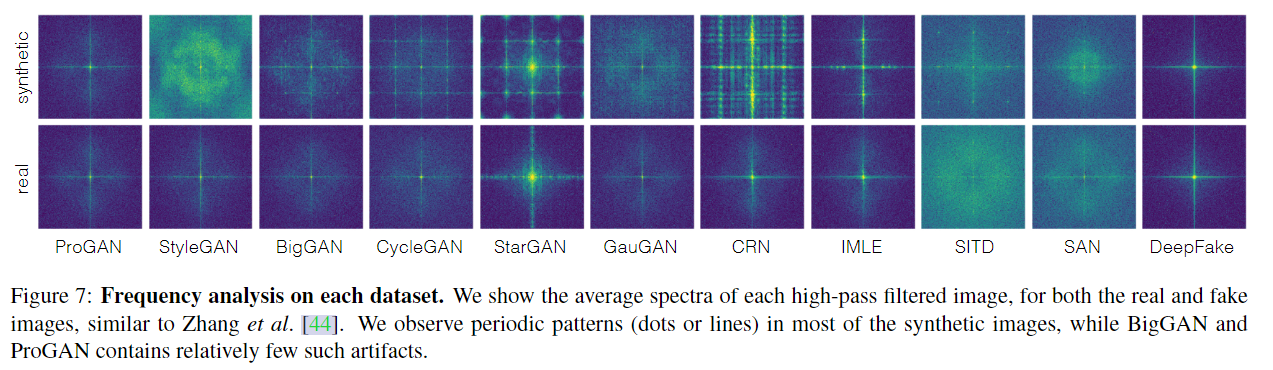
4. 生成图片 vs 真实图片频域差异:大部分生成图片在频域有棋盘效应(low-level CNN artifacts)
5. 在PS结果上的泛化性:模型在Photoshope处理过的数据集上预测结果近乎随机
【CVPR 2021】【Microsoft Cloud AI】Multi-attentional Deepfake Detection
【CVPR 2022】【Youtu Lab, Tencent】End-to-End Reconstruction-Classification Learning for Face Forgery Detection
Motivation:当训练集中Fake类别图像分布不够丰富时(Fake图片的种类通常是多样且日益增长),判别式模型的泛化性能存在问题
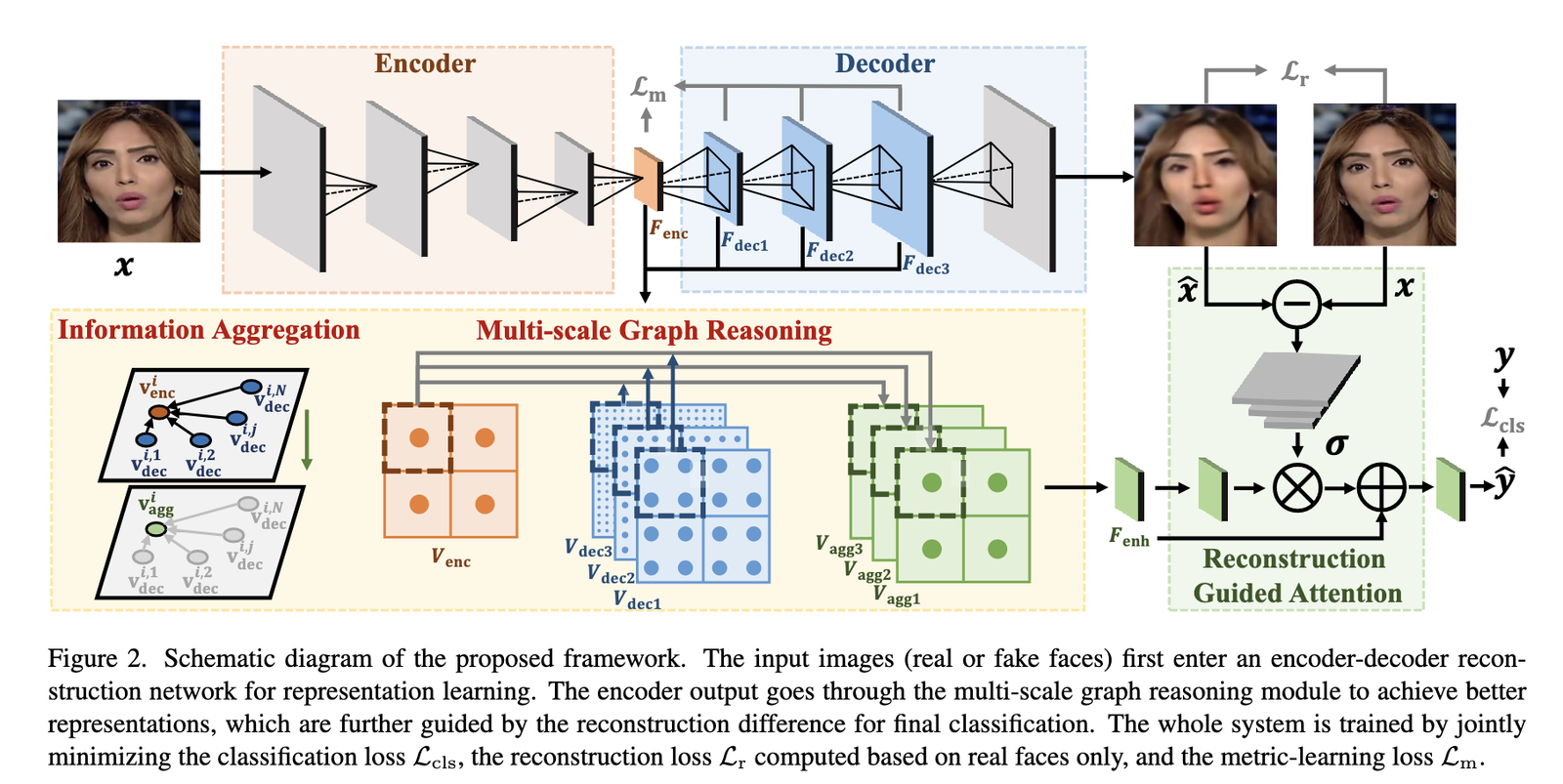
Method & Results:通过生成式模型AutoEncoder进行像素级重建,学习真实图像的数据分布
【ECCV 2020】【SenseTime】Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues
Motivation: 生成图像的“伪影”在频域更为明显,通过引入频域特征,提升模型鉴别能力;当图像被JPEG压缩后,伪影在像素空间上不显著,但在频域响应中可见

Method & Results:
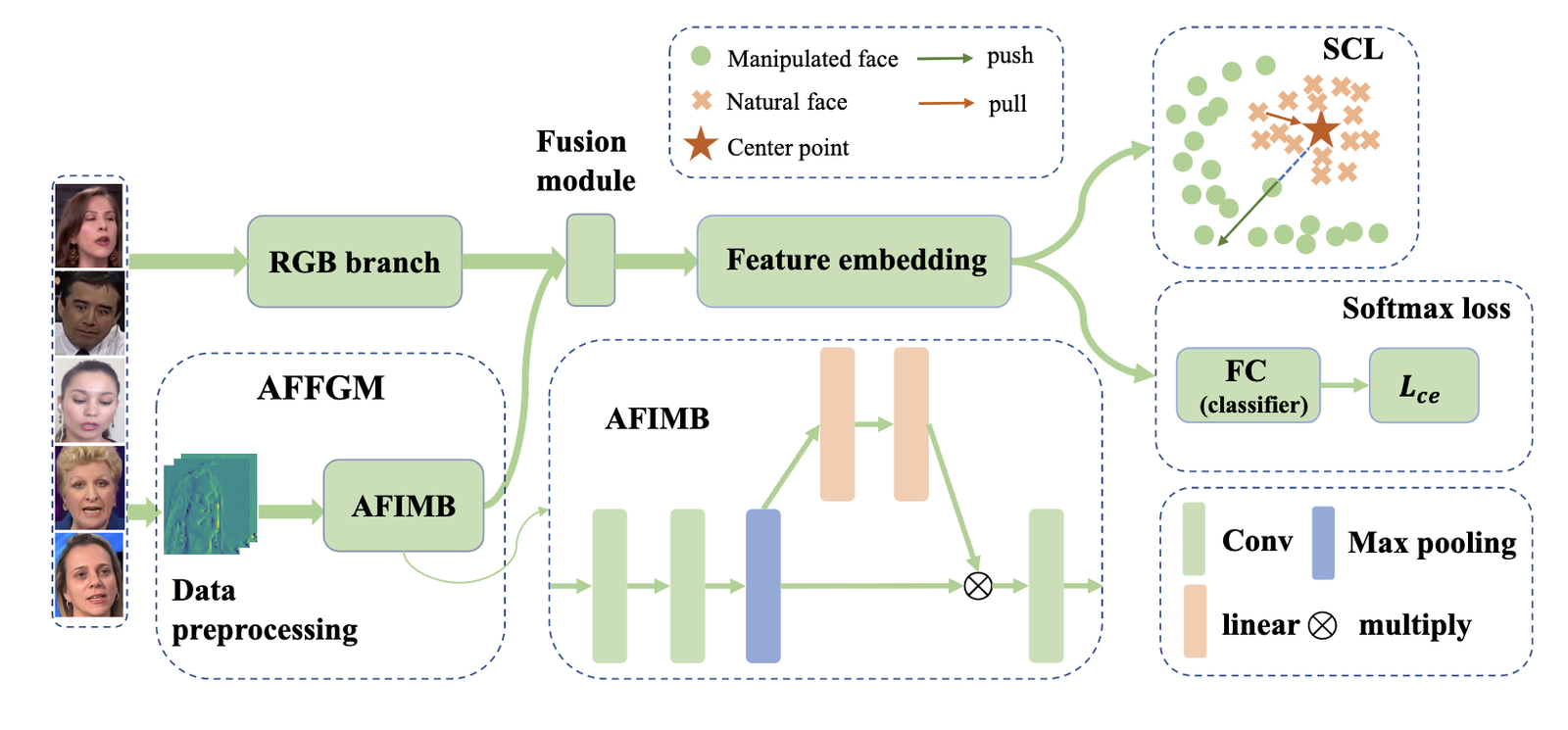
论文方法整体还是一个二分类的框架,为了能够充分利用频域信息,作者采用了FAD提取空间域特征,LFS提取频域特征,最后再进行两类特征融合。
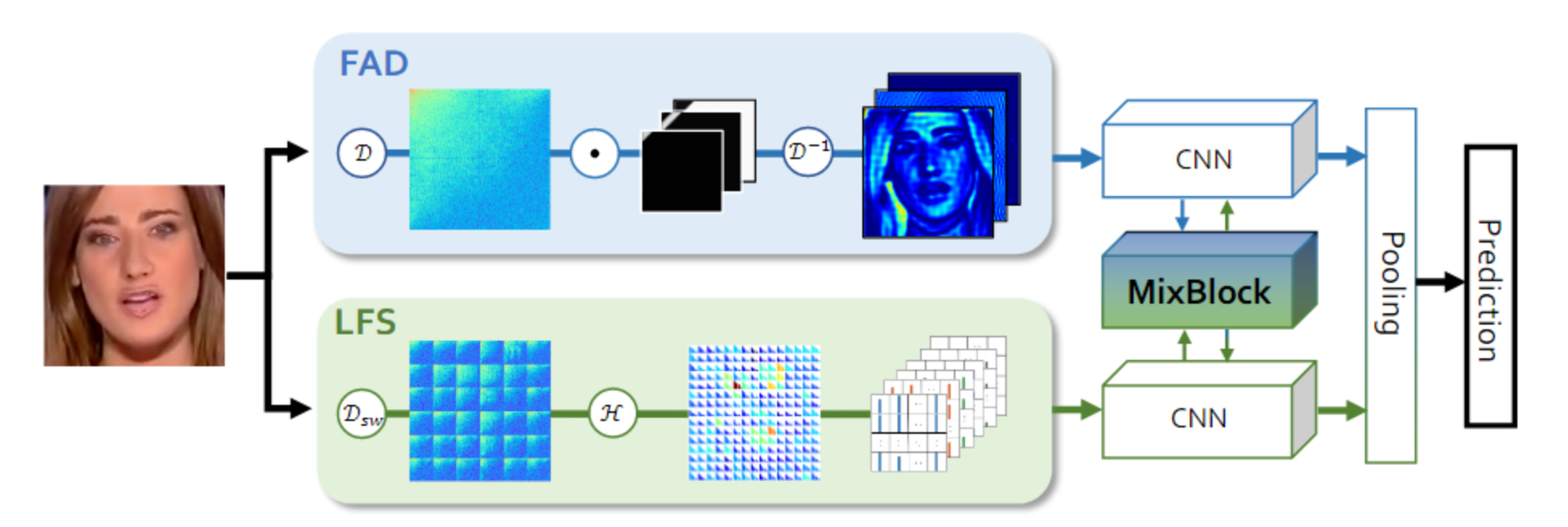
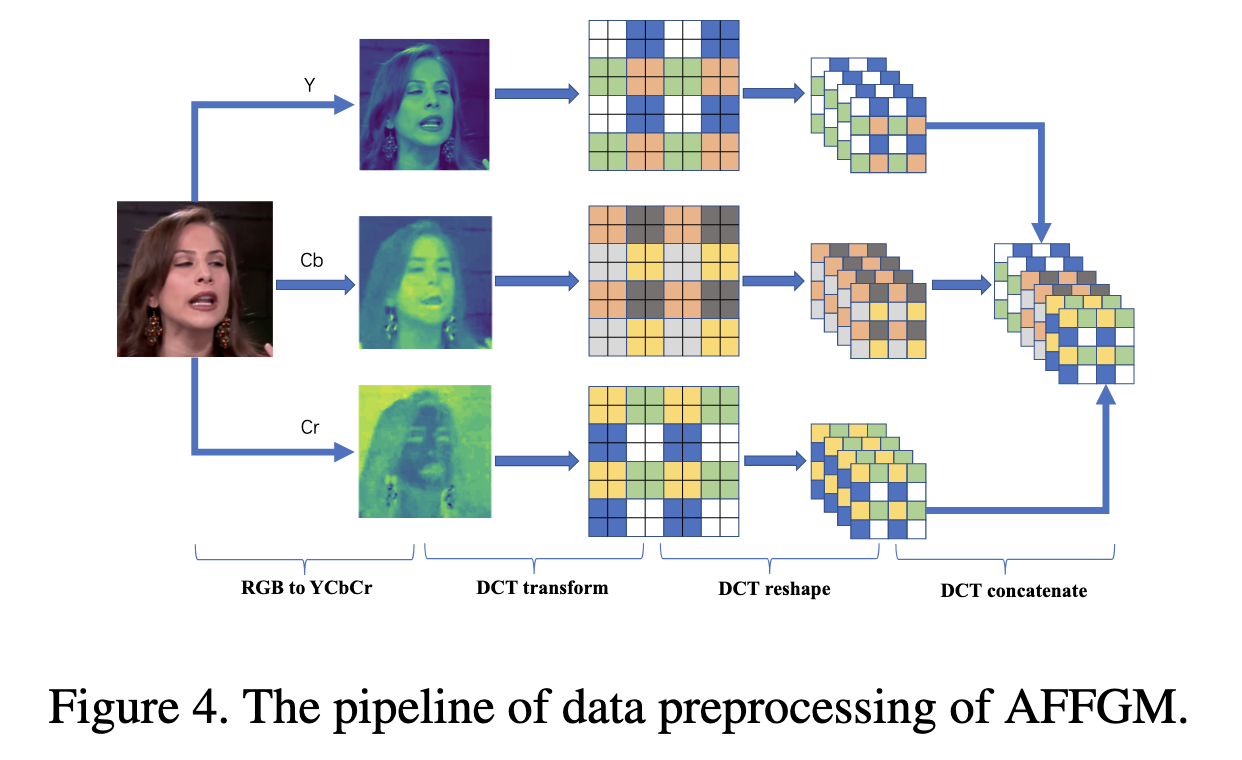
Frequency-aware 空间域特征(FAD):利用DCT将输入图像转换到频域,在频域进行高通、低通、和带通滤波,每个频带的滤波结果转换回空间域之后,就实现了图像分解,图像分解之后再进行CNN特征提取。
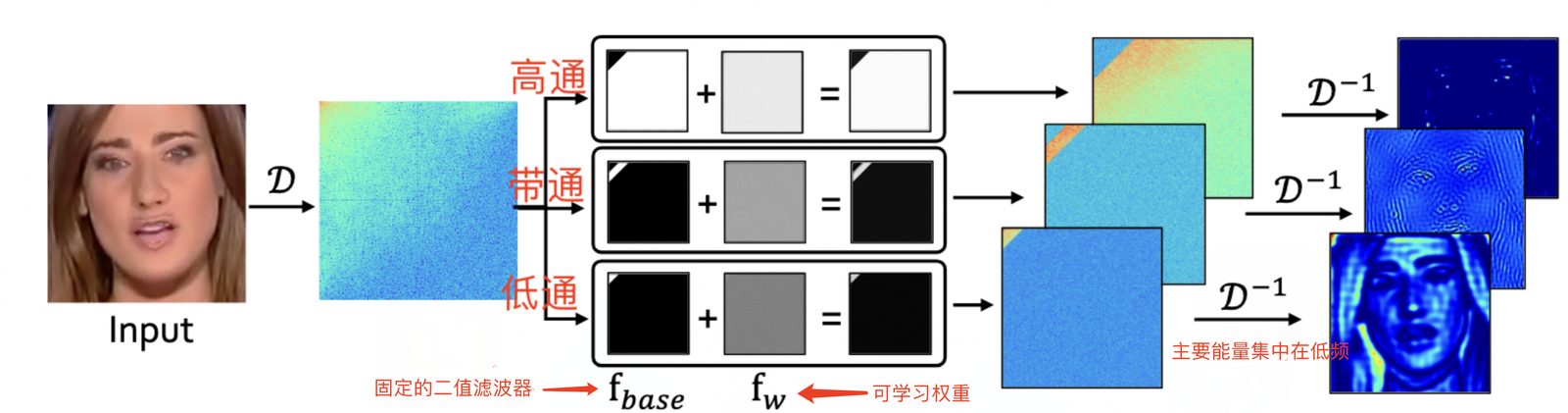
Local Frequency Statistics (LFS频域特征):利用滑动窗口DCT,对空间局部快进行频域分布统计特征
LFS 与FAD虽然都利用了频域信息,但是LFS是显式地以频域幅值作为特征,而FAD则通过DCT反变换回空间域再进行CNN特征提取。局部窗口统计特征 & 空间像素特征具有平移不变形,所以能适用CNN。(不直接在整图的频域上使用CNN)

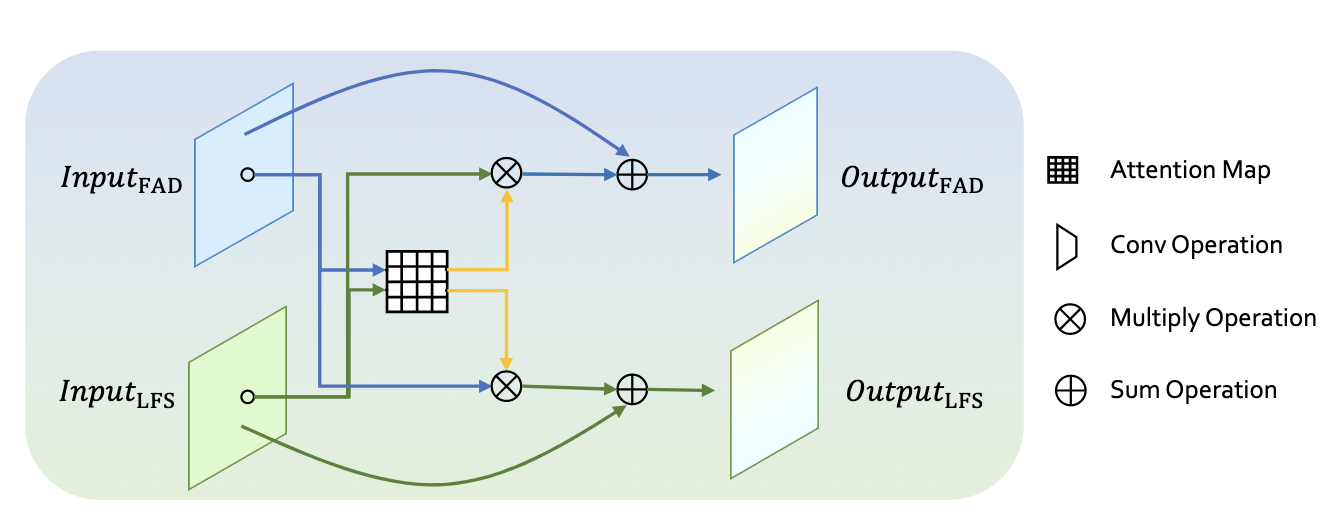
two-stream融合模块:Cross Attnetion 进行两类特征融合
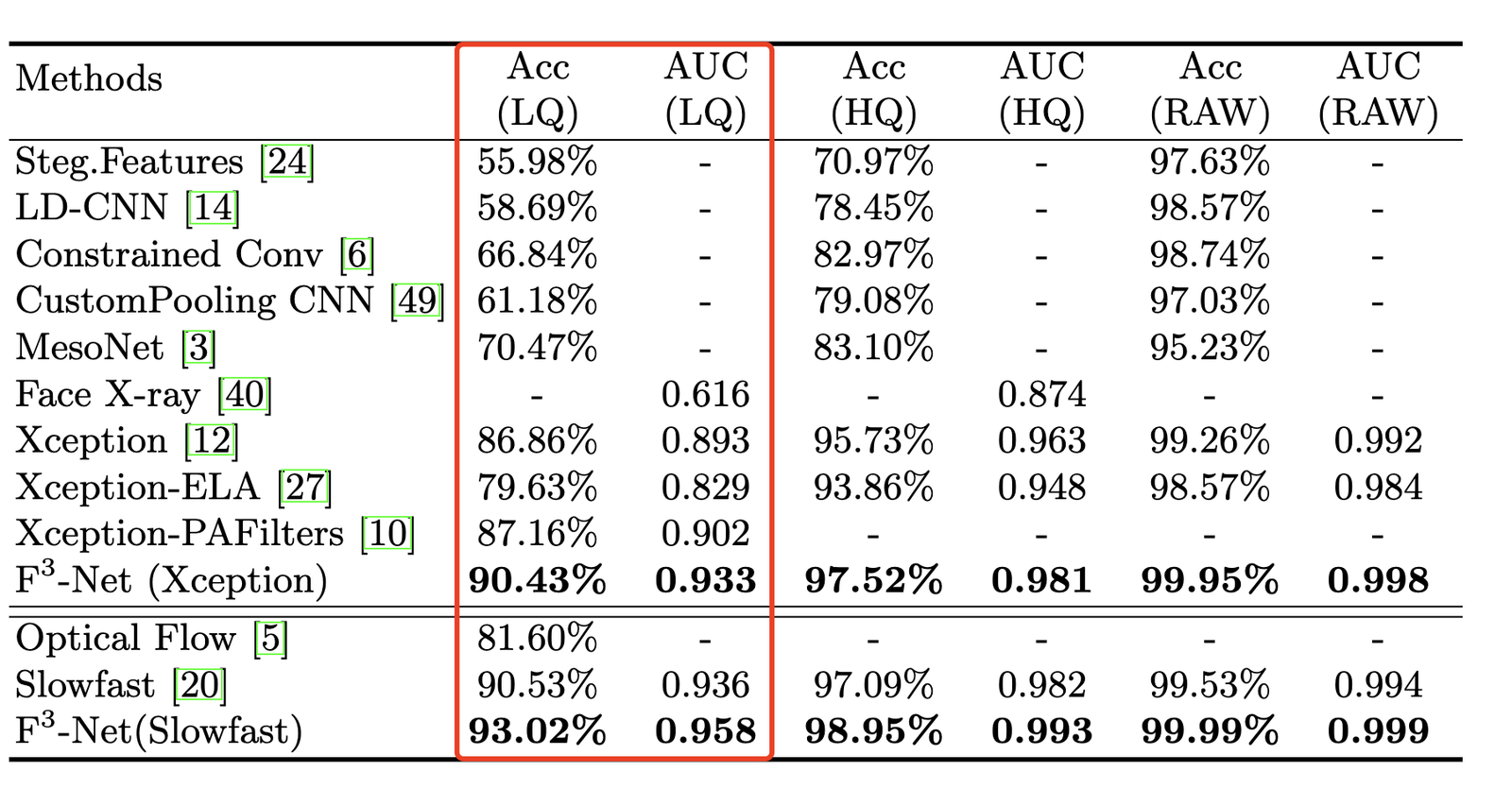
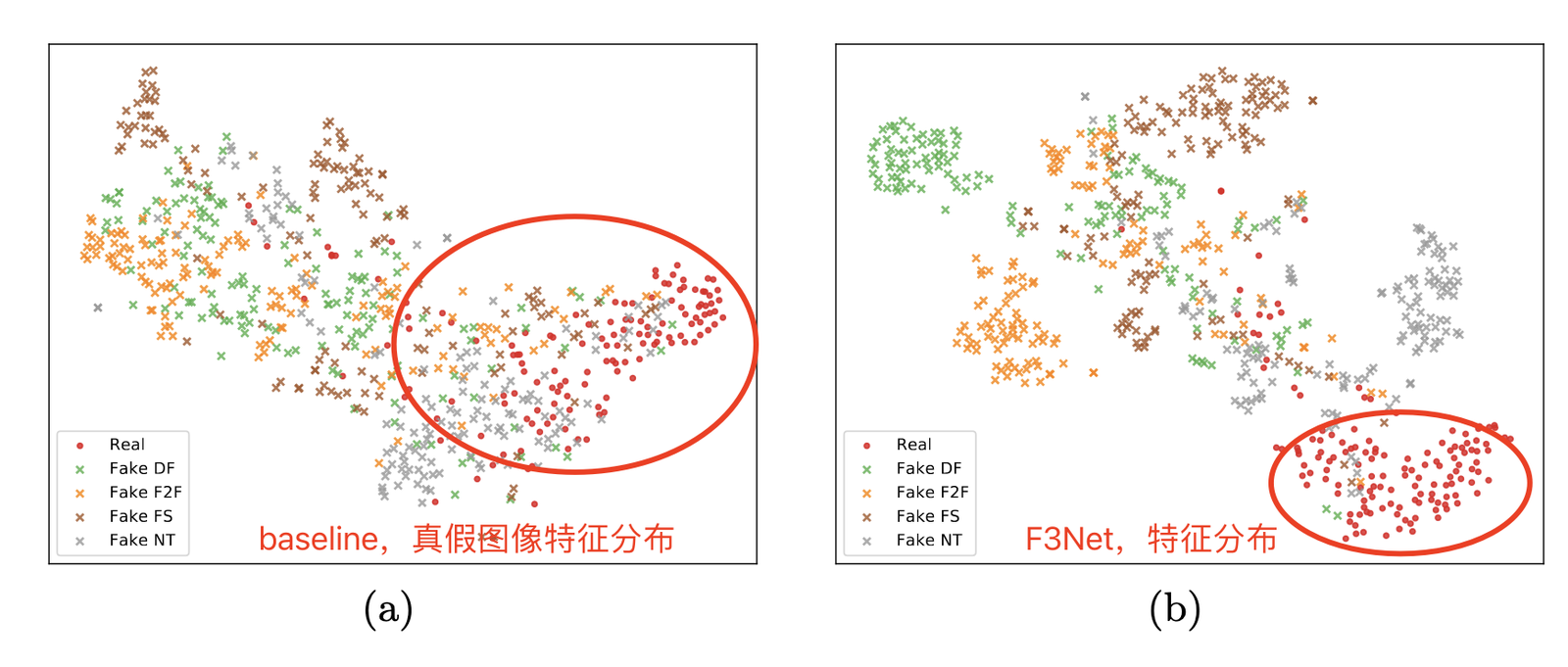
模型优点 & 实验验证:在低画质图像上(压缩),模型的性能优越
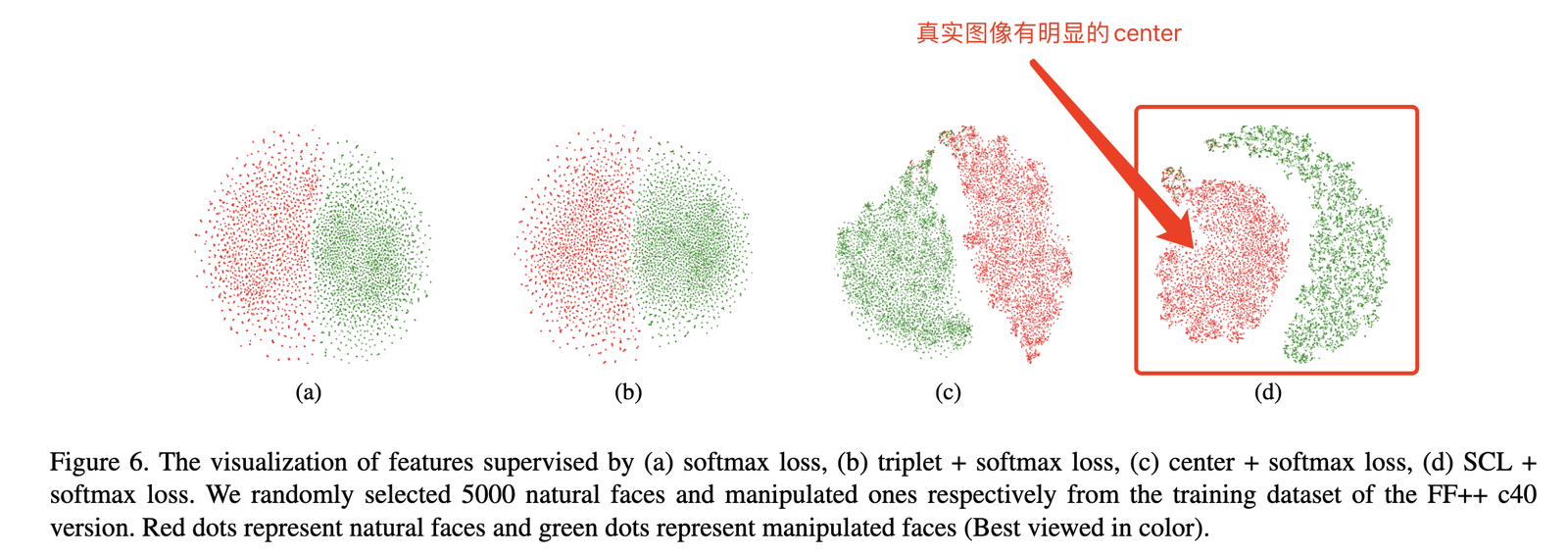
【CVPR 2021】【Kuaishou】Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection
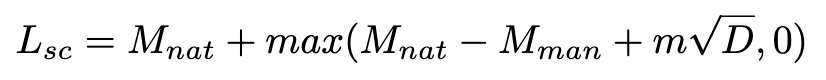
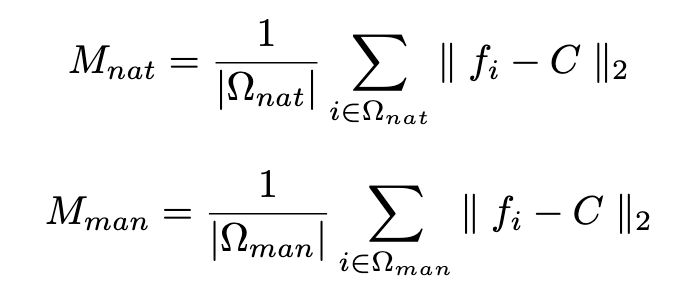

【InstructGPT】【OpenAI】Training language models to follow instructions with human feedback

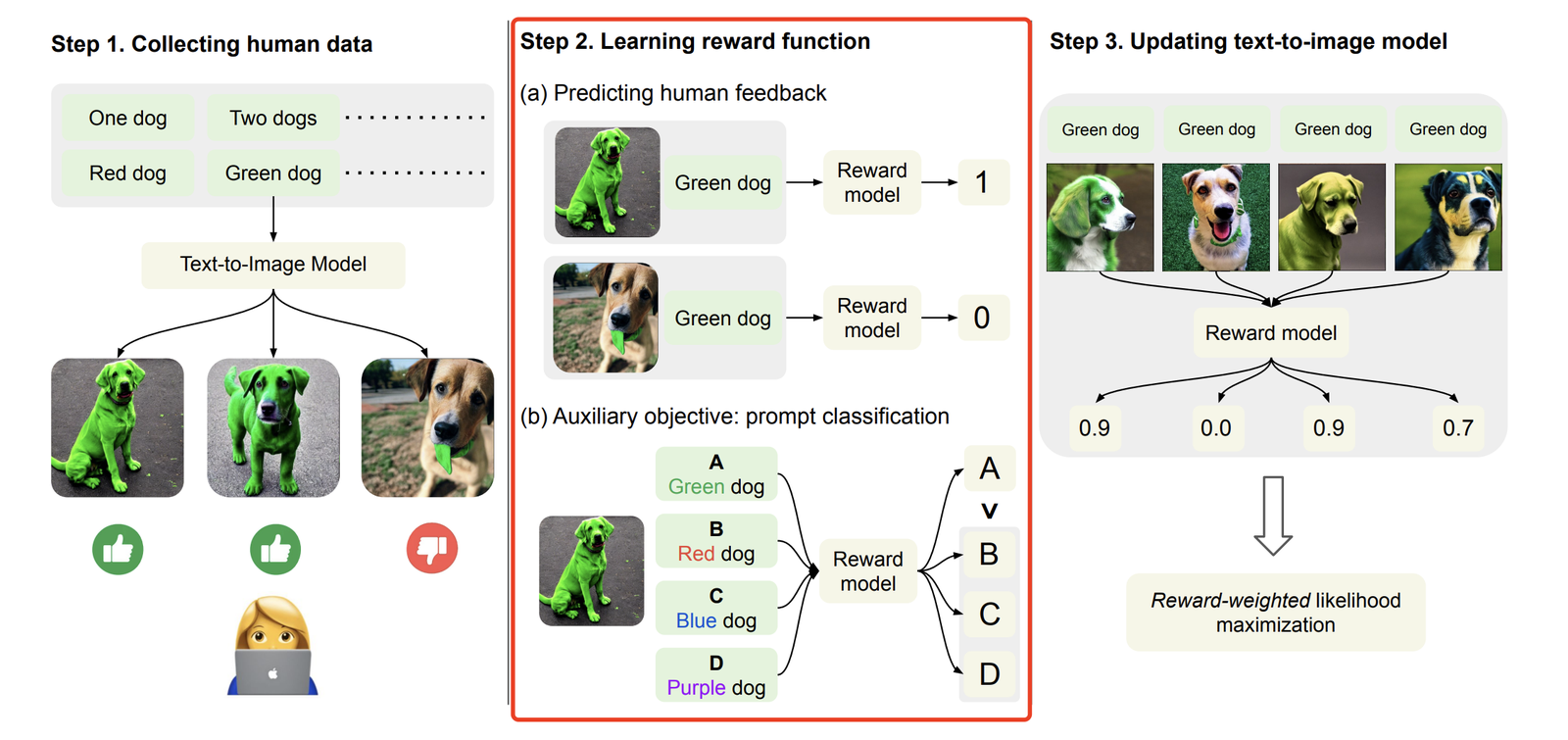
【Google】 Aligning Text-to-Image Models using Human Feedback
评论 (0)