
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

Emu的主要发现: 采用少量的人工挑选标注数据(2k),即可大幅提升生成图像的美学质量。可能存在的问题:在少量数据集下Finetune需要严格控制训练steps,否则可能会出现过拟合问题、主体概念遗忘问题
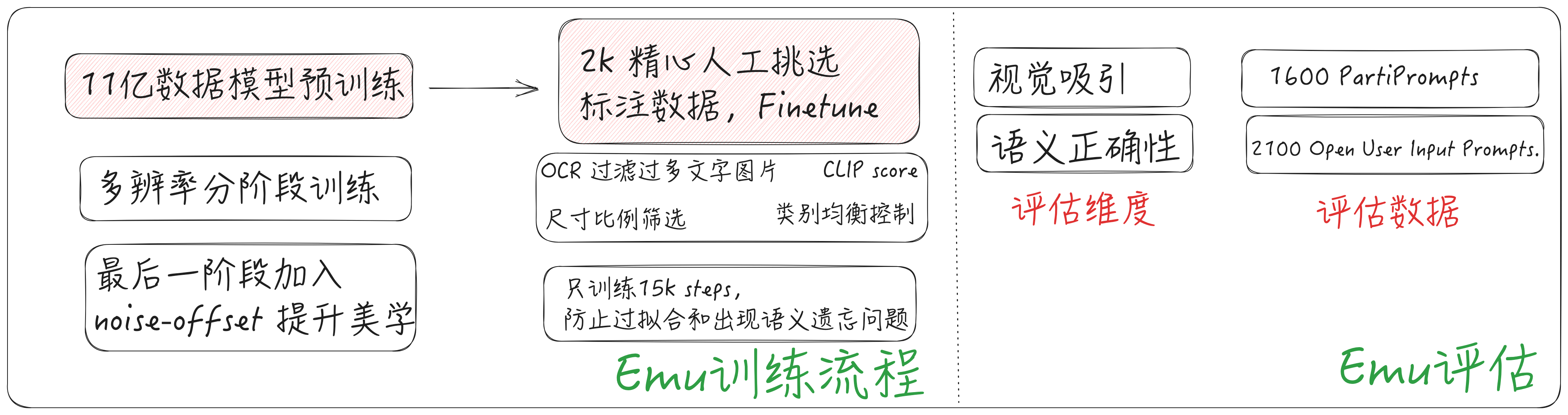

模型结构主要改进点:
文本Encoder集成 CLIP和T5-XXL两种不同类型特征
提升VAE编码的特征通道数,让有损压缩丢失的信息更少
参考之前工作,利用noise-offset & 分尺度多阶段训练方法。前期学习语义生成,后期提升生成细节。
评论 (0)