搜索到
3
篇与
Segmentation
的结果
-
 Transformer-based Segmentation Unet系列Transformer模型(医学图像分割) 结合全局(self-attention) 和 局部(Unet) 的特点,构建分割网络 如何在小样本数据集上,使得分割work,有效训练大参数量的transformer模型 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation [Code] 1. Metric: 2. Motivation: Swin transformer 的优点: 解决长序列问题;窗口内Attention + 窗口间信息交互; UNet的优点: 局部信息, ShortCut 3. Main Contributions: Based on Swin Transformer block, we build a symmetric Encoder-Decoder architecture with skip connections. In the encoder, self-attention from local to global is realized; in the decoder, the global features are up-sampled to the input resolution for corresponding pixel-level segmentation prediction. A patch expanding layer is developed to achieve up-sampling and feature dimension increase without using convolution or interpolation operation. It is found in the experiment that skip connection is also effective for Transformer, so a pure Transformer-based U-shaped Encoder-Decoder architecture with skip connection is finally constructed, named Swin-Unet. 4. Model Structure: 5. Take Home Message: 上采样方式patch expanding layer Medical Transformer: Gated Axial-Attention for Medical Image Segmentation [Code] 主流语义分割Transformer模型 SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [Code] MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation [Code]
Transformer-based Segmentation Unet系列Transformer模型(医学图像分割) 结合全局(self-attention) 和 局部(Unet) 的特点,构建分割网络 如何在小样本数据集上,使得分割work,有效训练大参数量的transformer模型 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation [Code] 1. Metric: 2. Motivation: Swin transformer 的优点: 解决长序列问题;窗口内Attention + 窗口间信息交互; UNet的优点: 局部信息, ShortCut 3. Main Contributions: Based on Swin Transformer block, we build a symmetric Encoder-Decoder architecture with skip connections. In the encoder, self-attention from local to global is realized; in the decoder, the global features are up-sampled to the input resolution for corresponding pixel-level segmentation prediction. A patch expanding layer is developed to achieve up-sampling and feature dimension increase without using convolution or interpolation operation. It is found in the experiment that skip connection is also effective for Transformer, so a pure Transformer-based U-shaped Encoder-Decoder architecture with skip connection is finally constructed, named Swin-Unet. 4. Model Structure: 5. Take Home Message: 上采样方式patch expanding layer Medical Transformer: Gated Axial-Attention for Medical Image Segmentation [Code] 主流语义分割Transformer模型 SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [Code] MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation [Code] -
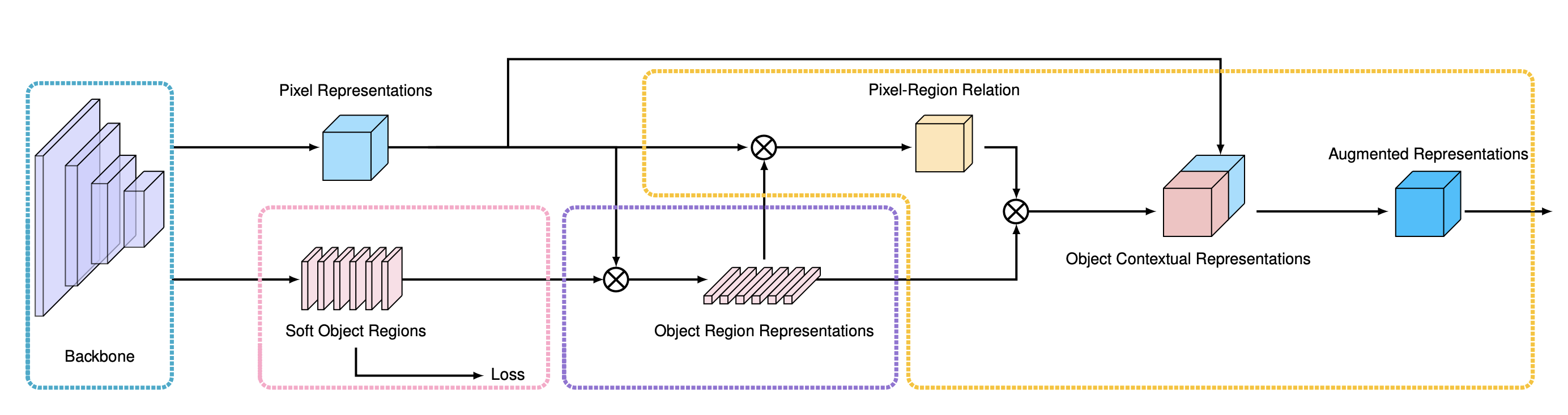
Awesome Segmentation 本文对截止到2020年各大顶会的分割论文,包括语义分割,实例分割, 全景分割,视频分割等领域发展进行小结,不定期更新。 Awesome Semantic Segmentation CVPR 2020 StripPooling Strip Pooling: Rethinking Spatial Pooling for Scene Parsing [Paper] [Code] ECCV 2020 Error-Correcting Supervision Semi-Supervised Segmentation based on Error-Correcting Supervision [Paper] Segmentation Failures Detection Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation [Paper] OCRNet Object-Contextual Representations for Semantic Segmentation[Paper] [Code] coarse2fine、attention IFVD Intra-class Feature Variation Distillation for Semantic Segmentation [Paper] [Code] 模型蒸馏 CaC-Netx Learning to Predict Context-adaptive Convolution for Semantic Segmentation[Paper] [[Code]()] 通过预测卷积kernel进行空间attention TGM Tensor Low-Rank Reconstruction for Semantic Segmentation [Paper] [Code] non-local方法的改进 Segfix SegFix: Model-Agnostic Boundary Refinement for Segmentation [Paper] Motivation: 边缘处的点的类别与“内部”的点的类比相似,通过网络学习shift DecoupleSegNets Improving Semantic Segmentation via Decoupled Body and Edge Supervision [Paper] [Code] 将主体和边缘特征分离,多任务学习 EfficientFCN EfficientFCN: Holistically-guided Decoding for Semantic Segmentation [Paper] Motivation: 如何高效率地扩充特征的感受野 算法原理:通过采用减小stride+dilated conv的方式的方式,由于特征分辨率增加导致计算量暴增。文章主要提出一种利用stride=32生成“Codebook”,可以理解为不同patten的特征集合,利用stride=8的特征生成集合的组合系数,实现“上采样” GCSeg Class-wise Dynamic Graph Convolution for Semantic Segmentation [Paper] 图卷积做全局特征提取 CVPR 2019 Fast Interactive Object Annotation with Curve-GCN. [Paper] [Code(pytorch)] 利用Graph Convolutional Network (GCN) 预测多边形的各个端点实现分割标注 Large-scale interactive object segmentation with human annotators. [Paper] 交互式分割 Knowledge Adaptation for Efficient Semantic Segmentation. [Paper] 通过知识蒸馏实现大降采样(分辨率降16倍)的高效率分割 通过autoencoder对Teacher网络的特征进行压缩去噪,用L2损失比较T的编码特征与S的编码特征 两两像素之间的相似性的差异(pair-wise distillation) Structured Knowledge Distillation for Semantic Segmentation. [Paper] 通过知识蒸馏实现高效分割,引入多个约束项 单个像素的损失(Teacher与Student之间逐像素损失,Student与GT之间逐像素损失) Teacher与Student网络中两两像素之间的相似性的差异(pair-wise distillation) 利用判别网络实现约束Embedding的相似性(holistic distillation) FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference. [Paper] 图片类别标注(Weakly); 图片类别标注+部分逐像素标注(Semi-supervised) Dual Attention Network for Scene Segmentation. [Paper] [Code(pytorch)] 加入空间上(二阶关系,借鉴Non-Local)和通道上的注意力 [DUpsampling]: Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation. [Paper] 基于Encoder-Decoder的算法通常为了避免Encoder的最后一层卷积层空间分辨率过小,Encoder网络的total_stride会尽可能小(多数为8),导致占内存,消耗大量计算资源 该论文提出的DUpsampling,利用分割标注在空间上的冗余性(对标注概率label_prob的压缩,对低分辨率网络输出pred_prob,重建高分辨率标注概率label_prob)提出了一种Data-Dependent的上采样方法,比转置卷积上采样方法参数量少,比双线性插值方法更好。 得益于DUpsampling,可以将特征分辨率将到足够低,并对底层特征进行Downsample,然后与低分辨率高层特征融合,减少计算量 In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images. [Paper] [Code(Pytorch)] 出发点: 实现实时语义分割 轻量化backbone: compact encoders(ResNet18 or MobileNet V2) 轻量化decoder with lateral skip-connections(UNet类似结构) 增大网络的感受野:SPP(PSPNet) 或 结合lateral skip-connections的图像金字塔结构,有利于识别大目标 ECCV 2018 [ICNet]: ICNet for Real-Time Semantic Segmentation on High-Resolution Images. [Paper] [Code(Tensorflow)] PSPNet(~1FPS)的加速版本,能够达到实时,30FPS; Image Cascade Network(ICNet) 为什么不直接在最后一个分辨率下,实现1/16和1/32的降采样,然后多尺度特征图融合(UNet结构),再加上多个尺度上的监督,也就是DeepLabV3+的简化模型版本? [ExFuse]: Enhancing Feature Fusion for Semantic Segmentation(Face++).[Paper] semantic supervision(SS): 在backbone的预训练的过程,在网络的中间层加入多个分类损失,使得中间层带有更多的语义信息 layer rearrangement(LR): 调整backbone中不同block的通道数的分布,使得深层和浅层具有相近的通道数,即丰富底层特征,有利于后续步骤中深层和浅层的融合 explicit channel resolution embedding(ECRE):借鉴超分辨率中的上采样方式(sub-pixel Upsample) semantic embedding branch(SEB): 将不同深层特征进行上采样,然后与浅层特征相乘融合 densely adjacent prediction(DEP): 可以理解为卷积核为$k \times k$固定参数$\frac{1}{k \times k}$的group conv [DeepLabv3+]: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Adaptive Affinity Fields for Semantic Segmentation [PSANet]: Point-wise Spatial Attention Network for Scene Parsing [ESPNet]: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation [BiSeNet]: Bilateral Segmentation Network for Real-time Semantic Segmentation CVPR 2018 [DFN]: Learning a Discriminative Feature Network for Semantic Segmentation(Face++). [Paper] [Code(tensorflow)] The Lovász-Softmax loss:A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. [Paper] [Code] [EncNet]: Context Encoding for Semantic Segmentation Context Contrasted Feature and Gated Multi-Scale Aggregation for Scene Segmentation DenseASPP for Semantic Segmentation in Street Scenes Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation Awesome Instance Segmentation Latest YOLACT:Real-time Instance Segmentation. [Paper] CVPR 2020 BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation GITHUB CODE PolarMask: Single Shot Instance Segmentation with Polar Representation GITHUB CODE CVPR 2019 Hybrid Task Cascade for Instance Segmentation. [Paper] [Code(pytorch)] Mask Scoring R-CNN. [Paper] 算法简介:Mask Scoring R-CNN是对Mask-RCNN的改进,文章的出发点在于mask-rcnn采用分类的得分作为检测结果和分割结果与GT重合程度的得分,但是在实际应用中常常出现,分类得分高,但是检测结果和分割结果并不好的问题。为了更准确的评估分割结果的好坏,文章在Mask-RCNN的基础上提出一个MaskIOU分支,该分支以ROI区域的分割Mask和ROIAlign的特征作为输入,预测输出该ROI predicted mask与GT mask 之间的IOU score。结合IOU score 和classification score,判断该ROI输出mask的精确程度 值得借鉴的点: CVPR 2018 Path Aggregation Network for Instance Segmentation. [Paper] [Code(pytorch)] COCO2017 Winner :fire: Masklab: Instance segmentation by refining object detection with semantic and direction features ICCV 2017 Mask R-CNN. [Paper] CVPR 2017 End-to-End Instance Segmentation with Recurrent Attention.[Paper] ECCV 2016 Instance-sensitive fully convolutional networks Awesome Panoptic Segmentation CVPR 2019 Panoptic Segmentation. [Paper] Learning to Fuse Things and Stuff. [Paper] Attention-guided Unified Network for Panoptic Segmentation. Panoptic Feature Pyramid Networks. UPSNet: A Unified Panoptic Segmentation Network DeeperLab: Single-Shot Image Parser An End-to-End Network for Panoptic Segmentation PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things Awesome Video Object Segmentation 视频分割 VS 语义图片分割: 相邻帧得到相似的结果(时间冗余度和视觉抖动) VOS Performance(mean region similarity) Algorithm DAVIS(16val/17) YouTube-VOS Youtube-Obj(mIOU) Speed(FPS) RVOS(CVPR19) -/48.0 - - 22.7 STCNN(CVPR19) 83.8/58.7 - 79.6 0.256 FEELOVS(CVPR19) 81.1/- 1.96 SiamMask(CVPR19) 35 FAVOS(CVPR18) -/54.6 - - - OSVOS(CVPR17) 79.8/56.6 - - 0.1~5 MaskTrack(CVPR17) 80.3/- - 71.7 <1.0 OnAVOS(BMVC17) 86.1/- CVPR 2019 RVOS: End-to-End Recurrent Network for Video Object Segmentation. [Paper] [Code(pytorch)] 特点: 多目标视频分割;one-shot and zero-shot VOS spatial(Instance) and temporal(video) Recurrent Netorrk STCNN: Spatiotemporal CNN for Video Object Segmentation. [Paper] [Code(pytorch)] 主要由两个支路构成,Temporal Coherence Branch ,利用GAN进行无监督的预训练(输入前4帧, 预测输出当前帧, 生成器的目标为最小化生成图片与当前帧的MSE和最大化判别器的损失),网络的目的是学习时序的一致性;另外一条支路为Spatial Segmentation Branch,融合当前帧和历史帧的多尺度特征,得到当前帧的预测结果 FEELOVS: Fast End-to-End Embedding Learning for Video Object Segmentation. [Google] [Paper] [Code(tensorflow)] SiamMask: Fast Online Object Tracking and Segmentation: A Unifying Approach. [Paper] [Code(Pytorch)] MHP-VOS: Multiple Hypotheses Propagation for Video Object Segmentation. [Paper] 解决目标被遮挡或消失 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. [Paper] A Generative Appearance Model for End-To-End Video Object Segmentation. [Paper] [Code(Pytorch)] ECCV 2018 YouTube-VOS: Sequence-to-Sequence Video Object Segmentation. [Paper] [DatasetURL] Video object segmentation with joint re-identification and attention-aware mask propagation CVPR 2018 Motion-guided cascaded refinement network for video object segmentation. FAVOS: Fast and accurate online video object segmentation via tracking parts. Efficient video object segmentation via network modulation. CVPR 2017 OSVOS 可以认为是将语义分割方法适用到视频目标分割最直接的方法,由离线训练二分类网络(物体分割)+在线finetune构成。FusionSeg和MaskTrack用了光流信息和RGB输入图像进行互补,通过在网络的输入中加入传统方法计算的光流。FusionSeg的光流支路进行重新训练,和MaskTrack 直接沿用RGB支路的模型,前者的光流支路结果通过可学习的1*1卷积进行融合,而后者直接将光流支路得到的结果叠加求平均。 OSVOS: One-Shot Video Object Segmentation.[Paper] [Code(pytorch)] [Code(TensorFlow)] 算法流程图:ImageNet预训练+视频分割数据集DAVIS二分类训练+在线测试Finetune 特点:单帧处理,没有累计误差;通过Finetune+物体边缘损失约束,用时间换准确率 FusionSeg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos.[Paper] [Code(caffe)] 利用外观信息和运动信息构成two stream结构,实现视频目标分割 利用光流信息和当前帧的图像作为输入,够成two-stream结构,实现信息互补:ResNet101结构;最后采用不同大小的空洞卷积构成多尺度,最后通过逐点求极大值进行多分支结果融合。网络训练通过将不同分支分开单独训练后,再训练最后的融合层(1*1) 为了解决视频目标分割数据集不足的问题,提出利用预训练分割模型(VOC2012)+视频目标检测数据集(ImageNet VID)标注框进行筛选,再后处理得到训练数据,过程如下图: 缺点:光流采用传统方法估计得到,得到的带有噪声的光流输入图像可能使得训练不稳定,且会影响最后的输出结果 MaskTrack: Learning video object segmentation from static images. [Paper] [Code] 利用前一帧预测的mask和当前RGB图像作为输入,mask(t-1)指示了目标的位置,形状大小。训练通过对单张图像进行平移,形变生成训练数据图像对(RGBImg,mask);离线训练(静态图片平移形变生成的数据优于视频数据集,文中采用显著性检测数据集)+在线Finetue;此外可以加入光流信息互补提升性能,将RGB图像用光流图像替代,经过同样的卷积网络,得到输出概率与MaskTrack的输出概率得分进行平均(论文3.3节中) 特点: 速度慢(Finetune+光流计算耗时);前一帧的输入图像可以是粗糙的因此可以用目标检测算法相结合 Others OnAVOS: Online adaptation of convolutional neural networks for video object segmentation. [BMVC17] Awesome Video Instance Segmentation Reference Awesome-Panoptic-Segmentation Awesome Semantic Segmentation InstanceSegmentation 漫谈全景分割 视频分割在移动端的算法进展综述 Segmentation.X Deep-Learning-Semantic-Segmentation 自动驾驶入门日记-5-视频语义分割 ECCV2020 segmentation
-
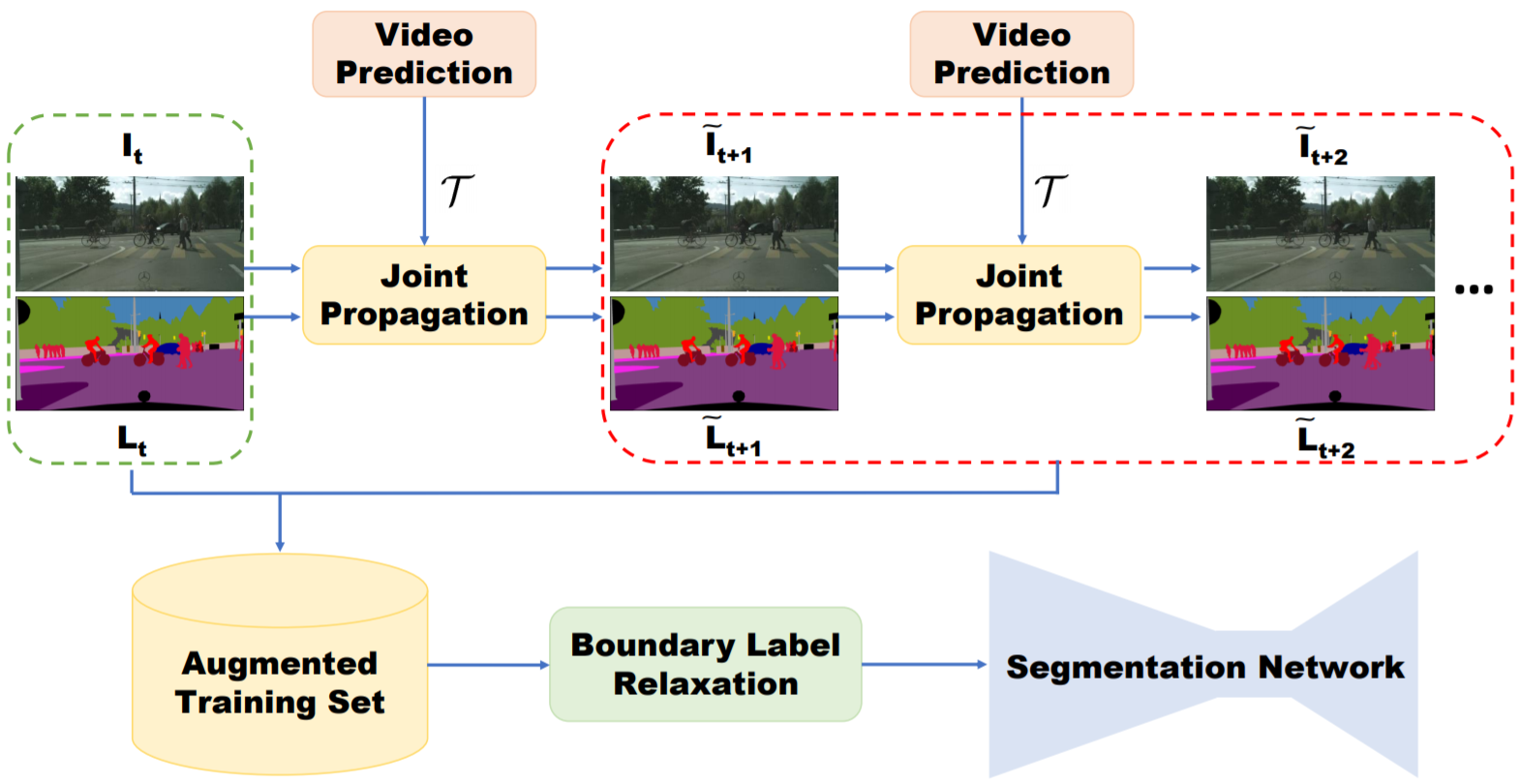
视频语义分割 1. Overview 如果对视频语义分割采用逐帧进行图像语义分割的方法存在两个问题:1. 逐帧处理没有考虑分割结果的时空一致性,造成视觉上分割结果在边缘上的剧烈抖动;2. 同一视频中的不同帧之间非常相似,用图像分割网络提取特征存在大量的计算冗余。基于这两点视频语义分割目前主要有两个研究方向: 提升精度,利用时序信息提升精度 视频数据生成辅助训练(少量标注); 利用时序视频帧自监督学习时序特征:star: 光流法用于图像/特征/标签的propagation;光流图用于网络输入:star: 在对图像逐帧分割后的refinement操作(后处理):optimization based label propagation(CRF); Filtering based label propagation(e.g. Bilateral filtering) CRF作为深度神经网络中的Layer进行端到端学习 提升速度,对时序上的特征进行重用(同一视频相邻时刻的图像帧的高层语义特征相似),以减少推断时间消耗。具体过程分为两步:先通过视频关键帧选择的策略(固定时间间隔、根据网络输出score判断、强化学习策略等策略),选择少量的视频帧作为关键帧,只在这些帧上进行特征提取(主要耗时操作);对于非关键帧,通过feature propagation(包括naive copy or warping based on optical flow or spatially variant convolution等)方法变换得到,以达到减少计算量的目的 视频处理中常采用的方法(不限于视频语义分割任务): 3D CNN: 用于行为识别,视频预测任务。参数量大 two stream(spatial stream, temporal stream): 将多帧光流和图像帧作为网络输入,两条支路处理 optial flow: 用作图像/语意标签/特征等的变换(双线性插值方法) RNN/LSTM: 长时时序信息传递 2. 主要评测集算法性能对比 source Method cityscapes(mIOU) CamVid(mIOU) time(sec/frame) link CVPR19 Improving Semantic Segmentation via Video Propagation and Label Relaxation 83.5(baseline deeplabv3+: 79.5) 81.7 - Pytorch ICCV17 PEARL: Video Scene Parsing with Predictive Feature Learning :star: 75.4 - 0.8 - CVPR18 Semantic Video Segmentation by Gated Recurrent Flow Propagation :star: 80.6 - 0.7s@512x512(PSP) TF ICCV17 Semantic Video CNNs through Representation Warping 80.5 70.3 3@1024x2048(PSP) Caffe CVPR18 Deep Spatio-Temporal Random Fields for Efficient Video Segmentation - 67/75(cityscape pretrain) 0.08@321x321 - CVPR16 Feature space optimization for semantic video segmentation - 66.1 >10s c++ CVPR17 [Video Propagation Networks(VPN)](CVPR17 Paper [Code(Caffe)):star: - 69.5 0.38 + classifier预测时间 Caffe CVPR19 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video:star: 75.5 69.3 0.87 MXNet CVPR18 DVSNet: Dynamic Video Segmentation Network 70.4 - 0.12 TF CVPR18 Low-Latency Video Semantic Segmentation:star2: 76.8 - 0.17 - CVPR17 DFF: Deep feature flow for video recognition 69.2 - 0.18 MXNet CVPR17 Budget-Aware Deep Semantic Video Segmentation - - 50%计算量/90%准确率 - ECCV16 Clockwork Convnets for Video Semantic Segmentation 64.4 - - Caffe 3. 算法细节介绍 3.1 提升精度方向(7) 3.1.1 视频数据生成辅助训练(2) Improving Semantic Segmentation via Video Propagation and Label Relaxation. CVPR19 算法简介:主要提出了一种通过视频预测进行数据扩充的方法。给定稀疏标注的数据集(每隔一定视频帧数才进行标注,总标注语言标签帧数小于总视频帧数),利用视频帧$I_{1:t+1}$和光流$F_{2:t+1}$得到运动向量(利用3D卷积实现),再结合当前帧$I_{t}$进行插值,输出预测的图像帧$\tilde{I_{t+1}}$,对于语义标签$\tilde{L_{t+1}}$同理,最后将预测得到的图像帧$\tilde{I_{t+1}}$、语义标签$\tilde{L_{t+1}}$加入分割图像训练集辅助训练。此外,为了避免生成的数据在边界上的标签不准确,本文提出Boundary Label Relaxation,即将边界上的像素概率从one-hot编码变成多类别(像素周围区域类别集合)概率和为1的监督信号;该方法最后仍然使用图像语义分割网络DeeplabV3+逐帧处理视频 可以借鉴的点:视频生成用于视频数据训练集扩充;Boundary Label Relaxation改善边界预测问题(在物体边缘的标注不准确引起的问题) PEARL: Video Scene Parsing with Predictive Feature Learning. ICCV2017 算法简介:该方案以历史图像帧预测未来图像帧(Frame Prediction),引导网络学习出时序相关(结构变化,运动变化)的特征。该学习过程利用视频图像帧进行自监督,不需要进行标注,适用于目前视频语义分割数据集匮乏的现状。视频预测任务采用GAN进行实现(生成器的第一层卷积层采用Group conv以适应多帧输入)。为了使得学习到的特征进一步适应语义分割任务,提出了利用历史帧预测未来图像帧的语义标签任务(Predictive Parsing),并采用上一过程中的生成器作为初始化参数。最后通过AdapNet(单层带ReLU的1x1卷积)融合时序信息特征$EN_{PPNet}$和当前帧的特征$EN_{IPNet}$,预测当前帧的分割结果。mIOU结果在cityscape数据集上提升6% 可以借鉴的点:利用历史帧预测当前帧学习到的特征能够挖掘视频中的时序信息,并且该方法不需要人工标注,对于处理视频任务是一种值得借鉴的预训练方法,隐式地将时序信息(运动信息/外观信息)集成在特征上 3.1.2 光流法(feature propagation)(2) 方法 优点 缺点 光流法(a) 可以用于大位移预测 受限于光流估计算法的精度,光流估计错误会出现累计误差;双线性插值的方法只考虑四个点,容易受到噪声影响;对于遮挡部分在下一帧出现的情况,遮挡部位的光流向量未定义造成错误 predicted sampling kernel(b) 变换时能够很好地保证物体形状的一致性(边缘预测准确) 由于所预测的位移范围与kernel尺寸相关,所以该方法不能处理大位移,否则大位移时需要大量显存 spatially-displaced convolution(c) 结合二者特点,能够在小kenel size的情况下预测大位移,节省计算资源 - 光流法的问题: 被遮挡部分再次出现问题 Semantic Video CNNs through Representation Warping. ICCV17 算法特点:本方案的基本思想是通过光流对前一帧图像的卷积特征进行warp操作,通过双线性插值方法得到与当前图像帧特征在空间上对齐的特征,然后将二者进行线性加权叠加。这里光流的计算采用DISFlow(5ms@CPU,原始光流)+FlowCNN(输入原始光流和图像对,输出refined的光流估计,通过语义分割标签图进行监督学习) 可以借鉴的点: 相比较于视频逐帧图像分割流程,该方法引入了历史帧特征提升性能,并且只增加了少量计算量(光流计算和双线性插值操作); 该算法只用到了两帧之间的光流,即只考虑了极短时间内图像的变化,结合多帧进行长时间和短时间的图像特征融合可以考虑作为改进的方向 光流法:目前现有视频语义分割文献中光流估计以FlowNet2网络为主流(300 ms/frame),考虑到效率时使用其它非深度网络方法 Semantic Video Segmentation by Gated Recurrent Flow Propagation. CVPR18 算法简介:通过光流法进行插值的方法得到的结果不总是可靠,例如被遮挡物体在下一帧重新出现的情况,被遮挡区域处的光流值是不定的,因为前后帧之间找不到对应点。本文采用GRU(Gated Recueeent Unit, LSTM的变种)门限思想,对于不准确的光流估计,通过Gate限制信息流动。光流估计的准确性通过$I_{t}$和$\hat{I_{t}}$(利用$I_{t-1}$和计算的光流结果wrap得到)之间的差值判断。与Netwrap不同光流插值方式不同,STGRU不对CNN的中间特征变换,而是直接对历史帧预测的语义分割概率$h_{t-1}$进行warp。利用光流网络(FlowNet)将前一帧预测的语义分割概率$h_{t-1}$与当前帧对齐得到$w_t$,结合当前帧语义分割结果$x_t$作为GRU的输入,最后得到当前帧的输出类别概率估计。 可以借鉴的点: 对光流估计进行置信度估计,避免不准确的光流估计对结果造成影响。 3.1.3 CRF(2) Deep Spatio-Temporal Random Fields for Efficient Video Segmentation. CVPR18 算法简介:将CRF作为深度神经网络中的一层,参与前向反向传播,区别于3D-CRF;用线性方程解替代平均场近似; 可以借鉴的点:CRF参与网络端到端训练,在性能和速度上均优于CRF后处理的方法。 Feature space optimization for semantic video segmentation. CVPR16 算法简介:将2D-CRF(特征维度: 位置,颜色)扩展成3D-CRF(特征维度: 位置,颜色,时刻),论文主要贡献在于对CRF中的特征空间选择(难点: 特征空间上,同一时刻的同一物体和不同时刻的同一个物体内的点的在特征空间上应该是邻近的,但是由于遮挡、摄像头运动等原因难以满足要求) 可以借鉴的点:: 对语义分割网络逐帧处理结果的后处理操作,该算法比较耗时(10秒/帧),不适合大规模数据处理 3.1.4 Filtering based propagation(1) Video Propagation Networks. CVPR17 Paper 算法简介: 文章提出一种双边滤波器网络对逐帧处理得到的分割结果进行refine的方法Video Propagation Networks(VPN,可以理解为图像语义分割在时间维度上的后处理操作,在时间维度上的平滑滤波)。VPN由双边滤波器网络(Bilateral Network)和常规卷积网络(Spatial Network)构成。VPN以当前帧之前的历史帧的分割结果$O_{t-T:t-1}$和历史帧图像$I_{t-T:t}$为输入,输出当前帧的预测结果$O_{t}$。狭义的双边滤波器采用高斯核函数和位置颜色(x,y,r,g,b)作为特征,本文采用可学习的滤波器组和位置颜色时间(x,y,r,g,b,t)作为特征。本文利用permutohedral lattice(一种对双边滤波的加速方法,可进行反向传播)双边滤波器网络进行加速。 可以借鉴的点:该方法属于后处理操作,任意的视频分割方法均可采用该方法进行结果提升。基于双边滤波的后处理方法相比较于基于优化的方法(CRF)而言,具有速度快的优势。缺点是网络的输入为分割网络的输出结果,不能进行端到端学习。 狭义上的双边滤波器(边缘保持滤波器):滤波器参数由空间域和像素域的核函数乘积构成。在平坦区域,不同位置像素域数值接近,主要由空间核函数作用;在边缘区域,不同位置像素值差别大,主要由像素域核函数起作用,所以起到了保留边缘的平滑滤波器效果。 3.2 提升速度方向(6) 提升速度方向的文章,算法流程基本分两步: 确定关键帧,并在关键帧上利用深度网络计算特征 利用特征传递的方法,将关键帧特征变换到当前需要处理的视频帧上,再输出当前帧分割结果 视频语义分割算法的主要耗时在步骤1中的深度网络特征提取,提升速度方向的算法通过高效的特征传递方法减少特征提取计算量 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. CVPR19 算法简介:每隔几帧,从视频中选择关键帧。关键帧的卷积网络特征(高准确率的特征网络)在一定的时间间隔内通过光流进行特征的重利用,与当前帧的卷积特征(Update Branch,轻量级特征网络)进行融合,输出当前帧的预测结果; 与DFF的区别在于,Accel进行了关键帧特征在一段时间内的累积wrap,而DFF直接从关键帧特征wrap到当前帧。 可以借鉴的点: 针对任务的要求(效率 vs 准确率),可以模块化定制选择不同Update feat特征网络;关键帧特征在多帧间逐步变换 DFF: Deep feature flow for video recognition. CVPR17 算法简介:每隔几帧,从视频中选择关键帧。利用关键帧特征和光流进行特征重用,避免对当前帧进行特征提取。特征传递不是逐帧依次累计进行,而是直接计算关键帧,和当前帧的光流进行变换。 可以借鉴的点: 算法丢弃了对当前帧进行特征提取,而是直接由关键帧特征变换得到。在视频内容变化快的情况下,会忽略当前视频帧中的细节,因此适用于场景变化慢、细节变化小的场景。 Low-Latency Video Semantic Segmentation. CVPR18 算法简介:文章主要有两个贡献点: 1. 特征传递 ;2.基于预测图像差异的关键帧选择策略。1.关键帧选择策略:以关键帧和当前帧低层卷积特征之差为输入,预测图像的差异来决定是否更新关键帧(gt为语义标注的差异)。 2.特征传递:为了能够减少计算当前图像帧的高层卷积特征,采用spatially variant convolution(自适应空间卷积,每一个位置的卷积权重不同,且卷积权重通过网络预测得到)将关键帧的高层卷积特征propagate到当前帧 可以借鉴的点::提出一种不同于光流法的特征传递方法,较光流法的优点在于具有空间的约束先验(关键帧中某一物体在当前帧的对应位置的固定邻域范围内,具有空间上的约束); 缺点是不能用于快速运动,运动范围受限于预测卷积kernel的大小,而kernel过大会导致过高的显存消耗 DVSNet: Dynamic Video Segmentation Network. CVPR18 算法简介:文章的主要出发点是视频中的图像帧,不同图像区域随着时间的变化,图像区域变化的程度不同。首先将图片划分成多个区域,再利用关键帧和当前帧的特征传递思想,对于变化慢的区域可以采用光流wrap关键帧对应区域的分割结果(小模型,速度快)得到当前帧中该区域的预测结果;对于变化区域快的区域可以直接通过分割网络(大模型,慢)得到该区域的预测结果。为了能够评估区域变化的快慢,采用Decision network(输入为光流网络特征,回归wraped语义结果图与GT之间的相似度)进行对光流法wrap操作准确性的估计。如果估计得分高,选择spatial warping path,否则选择segmentation path。 可以借鉴的点:相比较于逐帧处理,速度提升大(约10倍,直接wrap预测结果而不是卷积网络的中间特征层),效果变差明显(mIOU下降7%),适用于视频中不同区域内容变化差异大的场景。 Budget-Aware Deep Semantic Video Segmentation. CVPR17 算法简介: 本文通过只计算关键帧图像分割概率,非关键帧通过单层卷积求得(输出最邻近关键帧与非关键帧的图像差分和关键帧的分割概率,输出非关键帧的预测概率结果),其中关键帧的选择通过强化学习进行决策 可以借鉴的点:在对计算资源有严格的限制的情况下适用 Clockwork Convnets for Video Semantic Segmentation. ECCV16 算法简介:直接复制特征(卷积网络深层特征在一段时间间隔内的特征复用),简单粗暴,牺牲精度换效率 可以借鉴的点: 为了提升速度牺牲了过多精度,不推荐 4. 结论 4.1 改进设计原则 利用现实应用场景视频进行自监督的预训练(特征提取),学习时序信息(物体外形变化/运动变化)和适应现实场景 利用光流/spatially-displaced convolution等方法进行特征传递,融合两帧或多帧/长时(LSTM)特征。将任务分为特征提取backbone和任务相关的分支,对backbone进行特征传递,可以适用于所有的视频相关任务。 对光流估计进行置信度判断(类似MaskScore RCNN的思想,利用预测结果和特征输出得分),Gated限制噪声特征的传递(光流估计不准确,视频镜头切换等情况) 判断关键帧,用作加速(可选) Reference 知乎文章 视频语义分割介绍