搜索到
31
篇与
算法基础
的结果
-

-
-
Git常用命令总结 Git常用操作 git status # 确认下变更文件:新增、删除、更新? git diff # 确认下修改内容 git log # 查看commit记录 git add your_update_file #修改或者增加文件后,添加到git存储 git commit -m "做了什么修改" git push origin master:master #提交本地的master分支到远程仓库的git分支 git reflog #查看所有commit记录,包括被丢弃的commit,可以用于版本redo的用途 git commit --amend #追加文件到上次提交 git checkout --orphan new_branch # 新建独立的branch git branch -d branch_to_be_delete # 删除本地仓库branch git push <remote> --delete <branch> # 删除远程仓库branch git branch -m dev # 将当前分支重命名为dev 如何清除部分commit记录 git rebase -i start_commit_id end_commit_id # 合并commit记录 git rebase --abort #取消rebase 取消在git中track文件 git rm -r --cached file/folder # 删除记录,但不删除本地文件 git rm -r file/folder # 删除记录,并删除本地文件 git LFS 大文件管理(上传模型数据相关文件) lfs文件上传问题参考git lfs track *.pb #添加模型文件*.pb到LFS中 git lfs migrate import --include="*.so,*.pb" git lfs ls-files #查看添加到LFS的文件 git lfs push --all origin # 解决lfs文件上传问题 处理git pull时,文件冲突问题 git stash save git pull git stash pop git问题解决参考文章 Code Review/合作开发 Code Review introduction 忽略对git中某个文件的状态监控更新 git update-index --skip-worktree config.json # 监控 git update-index --no-skip-worktree config.json # 撤销操作 参考链接 详解 Git 大文件存储(Git LFS) git - 简易指南 廖雪峰Git教程
-
Blob in Caffe Class Blob A wrapper around SyncedMemory holders serving as the basic computational unit through which Layer, Net, and Solver interact. Caffe 由Blob、Layer、Net、Solver四大部分组成,其中Blob是之中最底层的结构。caffe的理念就是自下而上不断封装,使得上层代码不需要理会下层的具体操作,使代码变得清晰简洁。为了能够理解其它几层,我们需要从Blob开始。 首先,我们看看Blob类的声明,下面是Blob的成员变量 protected: shared_ptr<SyncedMemory> data_; shared_ptr<SyncedMemory> diff_; shared_ptr<SyncedMemory> shape_data_; vector<int> shape_; int count_; int capacity_;
-
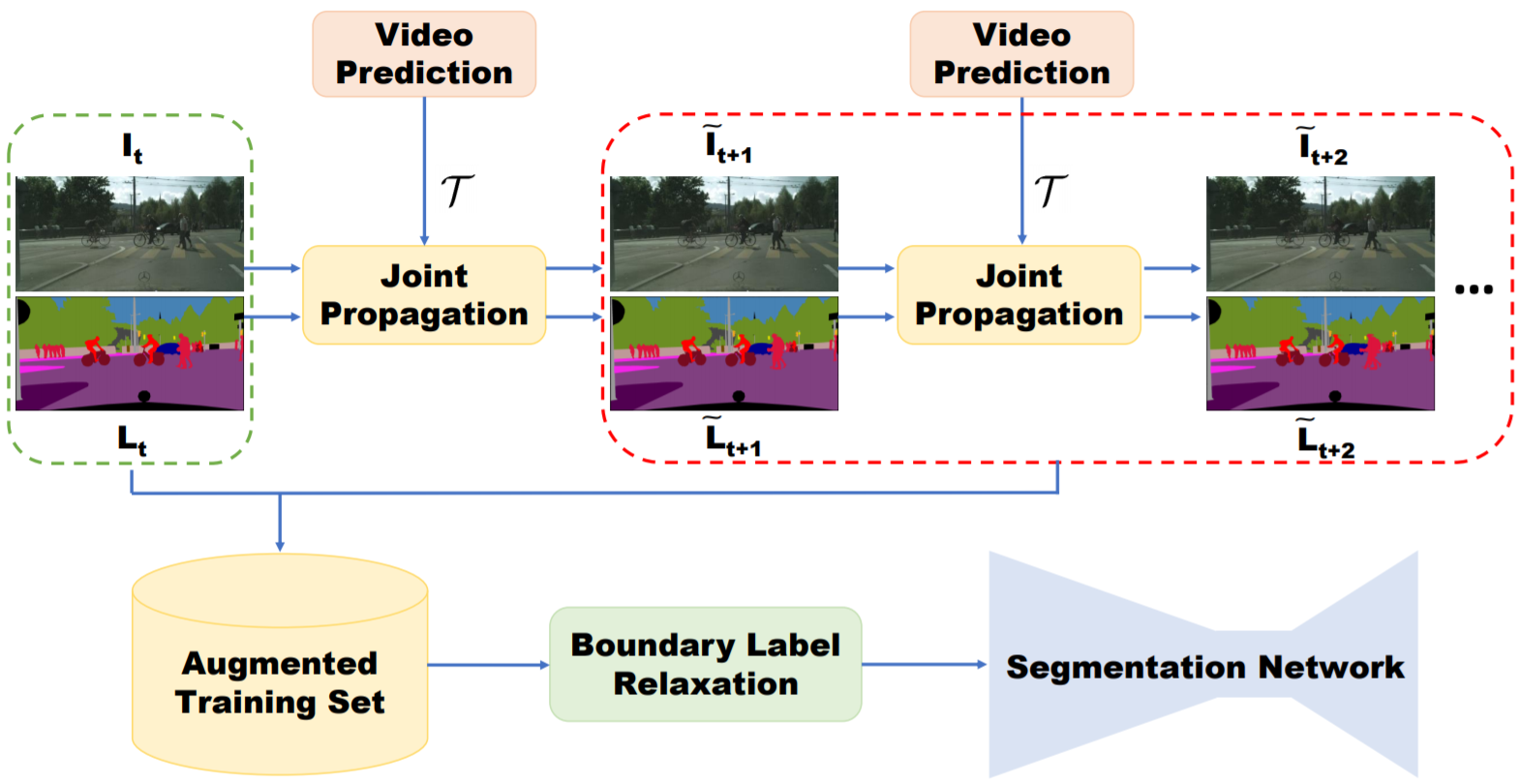
视频语义分割 1. Overview 如果对视频语义分割采用逐帧进行图像语义分割的方法存在两个问题:1. 逐帧处理没有考虑分割结果的时空一致性,造成视觉上分割结果在边缘上的剧烈抖动;2. 同一视频中的不同帧之间非常相似,用图像分割网络提取特征存在大量的计算冗余。基于这两点视频语义分割目前主要有两个研究方向: 提升精度,利用时序信息提升精度 视频数据生成辅助训练(少量标注); 利用时序视频帧自监督学习时序特征:star: 光流法用于图像/特征/标签的propagation;光流图用于网络输入:star: 在对图像逐帧分割后的refinement操作(后处理):optimization based label propagation(CRF); Filtering based label propagation(e.g. Bilateral filtering) CRF作为深度神经网络中的Layer进行端到端学习 提升速度,对时序上的特征进行重用(同一视频相邻时刻的图像帧的高层语义特征相似),以减少推断时间消耗。具体过程分为两步:先通过视频关键帧选择的策略(固定时间间隔、根据网络输出score判断、强化学习策略等策略),选择少量的视频帧作为关键帧,只在这些帧上进行特征提取(主要耗时操作);对于非关键帧,通过feature propagation(包括naive copy or warping based on optical flow or spatially variant convolution等)方法变换得到,以达到减少计算量的目的 视频处理中常采用的方法(不限于视频语义分割任务): 3D CNN: 用于行为识别,视频预测任务。参数量大 two stream(spatial stream, temporal stream): 将多帧光流和图像帧作为网络输入,两条支路处理 optial flow: 用作图像/语意标签/特征等的变换(双线性插值方法) RNN/LSTM: 长时时序信息传递 2. 主要评测集算法性能对比 source Method cityscapes(mIOU) CamVid(mIOU) time(sec/frame) link CVPR19 Improving Semantic Segmentation via Video Propagation and Label Relaxation 83.5(baseline deeplabv3+: 79.5) 81.7 - Pytorch ICCV17 PEARL: Video Scene Parsing with Predictive Feature Learning :star: 75.4 - 0.8 - CVPR18 Semantic Video Segmentation by Gated Recurrent Flow Propagation :star: 80.6 - 0.7s@512x512(PSP) TF ICCV17 Semantic Video CNNs through Representation Warping 80.5 70.3 3@1024x2048(PSP) Caffe CVPR18 Deep Spatio-Temporal Random Fields for Efficient Video Segmentation - 67/75(cityscape pretrain) 0.08@321x321 - CVPR16 Feature space optimization for semantic video segmentation - 66.1 >10s c++ CVPR17 [Video Propagation Networks(VPN)](CVPR17 Paper [Code(Caffe)):star: - 69.5 0.38 + classifier预测时间 Caffe CVPR19 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video:star: 75.5 69.3 0.87 MXNet CVPR18 DVSNet: Dynamic Video Segmentation Network 70.4 - 0.12 TF CVPR18 Low-Latency Video Semantic Segmentation:star2: 76.8 - 0.17 - CVPR17 DFF: Deep feature flow for video recognition 69.2 - 0.18 MXNet CVPR17 Budget-Aware Deep Semantic Video Segmentation - - 50%计算量/90%准确率 - ECCV16 Clockwork Convnets for Video Semantic Segmentation 64.4 - - Caffe 3. 算法细节介绍 3.1 提升精度方向(7) 3.1.1 视频数据生成辅助训练(2) Improving Semantic Segmentation via Video Propagation and Label Relaxation. CVPR19 算法简介:主要提出了一种通过视频预测进行数据扩充的方法。给定稀疏标注的数据集(每隔一定视频帧数才进行标注,总标注语言标签帧数小于总视频帧数),利用视频帧$I_{1:t+1}$和光流$F_{2:t+1}$得到运动向量(利用3D卷积实现),再结合当前帧$I_{t}$进行插值,输出预测的图像帧$\tilde{I_{t+1}}$,对于语义标签$\tilde{L_{t+1}}$同理,最后将预测得到的图像帧$\tilde{I_{t+1}}$、语义标签$\tilde{L_{t+1}}$加入分割图像训练集辅助训练。此外,为了避免生成的数据在边界上的标签不准确,本文提出Boundary Label Relaxation,即将边界上的像素概率从one-hot编码变成多类别(像素周围区域类别集合)概率和为1的监督信号;该方法最后仍然使用图像语义分割网络DeeplabV3+逐帧处理视频 可以借鉴的点:视频生成用于视频数据训练集扩充;Boundary Label Relaxation改善边界预测问题(在物体边缘的标注不准确引起的问题) PEARL: Video Scene Parsing with Predictive Feature Learning. ICCV2017 算法简介:该方案以历史图像帧预测未来图像帧(Frame Prediction),引导网络学习出时序相关(结构变化,运动变化)的特征。该学习过程利用视频图像帧进行自监督,不需要进行标注,适用于目前视频语义分割数据集匮乏的现状。视频预测任务采用GAN进行实现(生成器的第一层卷积层采用Group conv以适应多帧输入)。为了使得学习到的特征进一步适应语义分割任务,提出了利用历史帧预测未来图像帧的语义标签任务(Predictive Parsing),并采用上一过程中的生成器作为初始化参数。最后通过AdapNet(单层带ReLU的1x1卷积)融合时序信息特征$EN_{PPNet}$和当前帧的特征$EN_{IPNet}$,预测当前帧的分割结果。mIOU结果在cityscape数据集上提升6% 可以借鉴的点:利用历史帧预测当前帧学习到的特征能够挖掘视频中的时序信息,并且该方法不需要人工标注,对于处理视频任务是一种值得借鉴的预训练方法,隐式地将时序信息(运动信息/外观信息)集成在特征上 3.1.2 光流法(feature propagation)(2) 方法 优点 缺点 光流法(a) 可以用于大位移预测 受限于光流估计算法的精度,光流估计错误会出现累计误差;双线性插值的方法只考虑四个点,容易受到噪声影响;对于遮挡部分在下一帧出现的情况,遮挡部位的光流向量未定义造成错误 predicted sampling kernel(b) 变换时能够很好地保证物体形状的一致性(边缘预测准确) 由于所预测的位移范围与kernel尺寸相关,所以该方法不能处理大位移,否则大位移时需要大量显存 spatially-displaced convolution(c) 结合二者特点,能够在小kenel size的情况下预测大位移,节省计算资源 - 光流法的问题: 被遮挡部分再次出现问题 Semantic Video CNNs through Representation Warping. ICCV17 算法特点:本方案的基本思想是通过光流对前一帧图像的卷积特征进行warp操作,通过双线性插值方法得到与当前图像帧特征在空间上对齐的特征,然后将二者进行线性加权叠加。这里光流的计算采用DISFlow(5ms@CPU,原始光流)+FlowCNN(输入原始光流和图像对,输出refined的光流估计,通过语义分割标签图进行监督学习) 可以借鉴的点: 相比较于视频逐帧图像分割流程,该方法引入了历史帧特征提升性能,并且只增加了少量计算量(光流计算和双线性插值操作); 该算法只用到了两帧之间的光流,即只考虑了极短时间内图像的变化,结合多帧进行长时间和短时间的图像特征融合可以考虑作为改进的方向 光流法:目前现有视频语义分割文献中光流估计以FlowNet2网络为主流(300 ms/frame),考虑到效率时使用其它非深度网络方法 Semantic Video Segmentation by Gated Recurrent Flow Propagation. CVPR18 算法简介:通过光流法进行插值的方法得到的结果不总是可靠,例如被遮挡物体在下一帧重新出现的情况,被遮挡区域处的光流值是不定的,因为前后帧之间找不到对应点。本文采用GRU(Gated Recueeent Unit, LSTM的变种)门限思想,对于不准确的光流估计,通过Gate限制信息流动。光流估计的准确性通过$I_{t}$和$\hat{I_{t}}$(利用$I_{t-1}$和计算的光流结果wrap得到)之间的差值判断。与Netwrap不同光流插值方式不同,STGRU不对CNN的中间特征变换,而是直接对历史帧预测的语义分割概率$h_{t-1}$进行warp。利用光流网络(FlowNet)将前一帧预测的语义分割概率$h_{t-1}$与当前帧对齐得到$w_t$,结合当前帧语义分割结果$x_t$作为GRU的输入,最后得到当前帧的输出类别概率估计。 可以借鉴的点: 对光流估计进行置信度估计,避免不准确的光流估计对结果造成影响。 3.1.3 CRF(2) Deep Spatio-Temporal Random Fields for Efficient Video Segmentation. CVPR18 算法简介:将CRF作为深度神经网络中的一层,参与前向反向传播,区别于3D-CRF;用线性方程解替代平均场近似; 可以借鉴的点:CRF参与网络端到端训练,在性能和速度上均优于CRF后处理的方法。 Feature space optimization for semantic video segmentation. CVPR16 算法简介:将2D-CRF(特征维度: 位置,颜色)扩展成3D-CRF(特征维度: 位置,颜色,时刻),论文主要贡献在于对CRF中的特征空间选择(难点: 特征空间上,同一时刻的同一物体和不同时刻的同一个物体内的点的在特征空间上应该是邻近的,但是由于遮挡、摄像头运动等原因难以满足要求) 可以借鉴的点:: 对语义分割网络逐帧处理结果的后处理操作,该算法比较耗时(10秒/帧),不适合大规模数据处理 3.1.4 Filtering based propagation(1) Video Propagation Networks. CVPR17 Paper 算法简介: 文章提出一种双边滤波器网络对逐帧处理得到的分割结果进行refine的方法Video Propagation Networks(VPN,可以理解为图像语义分割在时间维度上的后处理操作,在时间维度上的平滑滤波)。VPN由双边滤波器网络(Bilateral Network)和常规卷积网络(Spatial Network)构成。VPN以当前帧之前的历史帧的分割结果$O_{t-T:t-1}$和历史帧图像$I_{t-T:t}$为输入,输出当前帧的预测结果$O_{t}$。狭义的双边滤波器采用高斯核函数和位置颜色(x,y,r,g,b)作为特征,本文采用可学习的滤波器组和位置颜色时间(x,y,r,g,b,t)作为特征。本文利用permutohedral lattice(一种对双边滤波的加速方法,可进行反向传播)双边滤波器网络进行加速。 可以借鉴的点:该方法属于后处理操作,任意的视频分割方法均可采用该方法进行结果提升。基于双边滤波的后处理方法相比较于基于优化的方法(CRF)而言,具有速度快的优势。缺点是网络的输入为分割网络的输出结果,不能进行端到端学习。 狭义上的双边滤波器(边缘保持滤波器):滤波器参数由空间域和像素域的核函数乘积构成。在平坦区域,不同位置像素域数值接近,主要由空间核函数作用;在边缘区域,不同位置像素值差别大,主要由像素域核函数起作用,所以起到了保留边缘的平滑滤波器效果。 3.2 提升速度方向(6) 提升速度方向的文章,算法流程基本分两步: 确定关键帧,并在关键帧上利用深度网络计算特征 利用特征传递的方法,将关键帧特征变换到当前需要处理的视频帧上,再输出当前帧分割结果 视频语义分割算法的主要耗时在步骤1中的深度网络特征提取,提升速度方向的算法通过高效的特征传递方法减少特征提取计算量 Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. CVPR19 算法简介:每隔几帧,从视频中选择关键帧。关键帧的卷积网络特征(高准确率的特征网络)在一定的时间间隔内通过光流进行特征的重利用,与当前帧的卷积特征(Update Branch,轻量级特征网络)进行融合,输出当前帧的预测结果; 与DFF的区别在于,Accel进行了关键帧特征在一段时间内的累积wrap,而DFF直接从关键帧特征wrap到当前帧。 可以借鉴的点: 针对任务的要求(效率 vs 准确率),可以模块化定制选择不同Update feat特征网络;关键帧特征在多帧间逐步变换 DFF: Deep feature flow for video recognition. CVPR17 算法简介:每隔几帧,从视频中选择关键帧。利用关键帧特征和光流进行特征重用,避免对当前帧进行特征提取。特征传递不是逐帧依次累计进行,而是直接计算关键帧,和当前帧的光流进行变换。 可以借鉴的点: 算法丢弃了对当前帧进行特征提取,而是直接由关键帧特征变换得到。在视频内容变化快的情况下,会忽略当前视频帧中的细节,因此适用于场景变化慢、细节变化小的场景。 Low-Latency Video Semantic Segmentation. CVPR18 算法简介:文章主要有两个贡献点: 1. 特征传递 ;2.基于预测图像差异的关键帧选择策略。1.关键帧选择策略:以关键帧和当前帧低层卷积特征之差为输入,预测图像的差异来决定是否更新关键帧(gt为语义标注的差异)。 2.特征传递:为了能够减少计算当前图像帧的高层卷积特征,采用spatially variant convolution(自适应空间卷积,每一个位置的卷积权重不同,且卷积权重通过网络预测得到)将关键帧的高层卷积特征propagate到当前帧 可以借鉴的点::提出一种不同于光流法的特征传递方法,较光流法的优点在于具有空间的约束先验(关键帧中某一物体在当前帧的对应位置的固定邻域范围内,具有空间上的约束); 缺点是不能用于快速运动,运动范围受限于预测卷积kernel的大小,而kernel过大会导致过高的显存消耗 DVSNet: Dynamic Video Segmentation Network. CVPR18 算法简介:文章的主要出发点是视频中的图像帧,不同图像区域随着时间的变化,图像区域变化的程度不同。首先将图片划分成多个区域,再利用关键帧和当前帧的特征传递思想,对于变化慢的区域可以采用光流wrap关键帧对应区域的分割结果(小模型,速度快)得到当前帧中该区域的预测结果;对于变化区域快的区域可以直接通过分割网络(大模型,慢)得到该区域的预测结果。为了能够评估区域变化的快慢,采用Decision network(输入为光流网络特征,回归wraped语义结果图与GT之间的相似度)进行对光流法wrap操作准确性的估计。如果估计得分高,选择spatial warping path,否则选择segmentation path。 可以借鉴的点:相比较于逐帧处理,速度提升大(约10倍,直接wrap预测结果而不是卷积网络的中间特征层),效果变差明显(mIOU下降7%),适用于视频中不同区域内容变化差异大的场景。 Budget-Aware Deep Semantic Video Segmentation. CVPR17 算法简介: 本文通过只计算关键帧图像分割概率,非关键帧通过单层卷积求得(输出最邻近关键帧与非关键帧的图像差分和关键帧的分割概率,输出非关键帧的预测概率结果),其中关键帧的选择通过强化学习进行决策 可以借鉴的点:在对计算资源有严格的限制的情况下适用 Clockwork Convnets for Video Semantic Segmentation. ECCV16 算法简介:直接复制特征(卷积网络深层特征在一段时间间隔内的特征复用),简单粗暴,牺牲精度换效率 可以借鉴的点: 为了提升速度牺牲了过多精度,不推荐 4. 结论 4.1 改进设计原则 利用现实应用场景视频进行自监督的预训练(特征提取),学习时序信息(物体外形变化/运动变化)和适应现实场景 利用光流/spatially-displaced convolution等方法进行特征传递,融合两帧或多帧/长时(LSTM)特征。将任务分为特征提取backbone和任务相关的分支,对backbone进行特征传递,可以适用于所有的视频相关任务。 对光流估计进行置信度判断(类似MaskScore RCNN的思想,利用预测结果和特征输出得分),Gated限制噪声特征的传递(光流估计不准确,视频镜头切换等情况) 判断关键帧,用作加速(可选) Reference 知乎文章 视频语义分割介绍
-
光流法到FlowNet 1. 光流法 首先,简单回顾下什么是光流估计。对于相邻的前后两帧图像x和y, 光流估计的目标是估计出y中每个像素点与在图像x上对应点的偏移量。我们讨论的是二维图像,所以这里的对于每个像素的偏移量由大小和方向表示。 如上图所示,左下角估计出的光流图像,色调表示偏移量的方向,色调的强度代表偏移量的大小。传统的光流估计法以LK光流法为代表, LK光流法主要由三个假设和利用最小二乘法求解每个像素点的偏移量(大小和方向)构成。其中三个假设为: 亮度恒定(建立等式) 相邻帧为小位移(能够进行泰勒级数展开) 局部小块具有运动一致性(每个像素点存在两个变量,但只有一个方程,所以需要假设多个像素点的偏移量一致,联立多个方程进行最小二乘法求解一致的偏移量) 具体公式见维基百科LK光流法
-
Python标准库threading threading 用来管理一个进程中的并行操作(线程) 在python中简单使用线程 import threading def worker(): print('Worker') threads = [] for i in range(5): t = threading.Thread(target = worker) threads.append(t) t.start() target参数是线程调用的函数,threading.Thread还可以通过name指定线程名称,args指定调用函数传入的参数。 start()函数,开始执行线程。另外,theading 中daemon(设置线程是否为后台线程)、join(后台线程阻塞)也是常用的用法。此处就不一一举例了。 线程同步 多线程的程序面临一个重要的问题,由于线程之间的资源是共享的,当不同线程访问共享资源时可能出现访问冲突(例如消费者和生产者的执行)。另外,当线程之间可能需要等待某个事件发生后,才被激活而执行(例如行人、车辆必须等待绿灯才能通过) theading中有lock、Rlock、condtion、Semaphore、Event实现线程的同步,当然各个方法还是有不同的特点。 首先,我们通过一个简单的栗子来感受下,多线程不进行同步可能出现的问题。 import threading import time count =0 def addcount(): global count for i in range(1000): count += 1 for i in range(10): t = threading.Thread(target=addcount) t.start() time.sleep(3) print count 理论上上述代码的结果应该是1000*10,但是当我们运行程序发现每次的结果都不同,并且结果都小于10000。对全局变量的修改可以分为取值和赋值两个阶段,假设某一时刻count=100,如果按照方式①Thread1取值(temp1=100)-->Thread1赋值(count=temp1+1)-->Thread2取值(temp2=101)-->Thread2赋值(count=temp2+1)这种方式,运行结果count为102。但是如果线程的顺序变为方式②Thread1取值(temp1=100)-->Thread2取值(temp2=100)-->Thread1赋值(count=temp1+1)-->Thread2赋值(count=temp2+1),运行结果count为101。 如果想要使得程序严格按照方式①的顺序运行,我们就需要进行线程的同步。 lock lock(锁)的工作原理: 所有的线程只有一把锁,谁抢到就执行哪个线程,当拥有锁的线程结束操作,需要释放锁让别的线程去竞争。 我们可以对上述的代码进行改写 import threading import time count =0 lock = threading.Lock() def addcount(): global count for i in range(1000): lock.acquire() count += 1 lock.release() for i in range(10): t = threading.Thread(target=addcount) t.start() time.sleep(3) print count 与原来的代码不同之处仅仅在于获取锁acquire()、释放锁release()的两个操作而已,Lock.acquire(blocking=True, timeout=-1),blocking参数表示是否阻塞当前线程等待,timeout表示阻塞时的等待时间 threading 中还有RLock与Lock功能类似,但是在同一个线程内可以多次调用RLCOK.acquire来获取锁,Lock如果多次accuire则会出现死锁的情况。 这样的RLock对比与Lock在哪些问题上有优势呢?(TO DO) GIL(Global Interpreter Lock) GIL 全局解释锁(TO DO) condtion condition 提供了比Lock更复杂的功能。线程只有满足一定条件后才能去竞争锁,不满足条件的线程处于等待池(当前线程调用condtion.wait()进入等待),直到收到通知(其它线程调用condition.notify())才退出等待状态,再开始去竞争锁。 下面以消费者和生产者为例(始终保证生产足够,但不过剩(产品数量限制在30以内):) ) import threading import time condition = threading.Condition() class Producer(threading.Thread): def run(self): while(1): global x print 'producer accquire lock' condition.acquire() print 'producer get lock' if x > 30: print 'x>need_max producer wait,and release lock' condition.wait() else: x = x + 5 print 'producing',x condition.notify() print 'producer done, notify others' condition.release() #print 'producer release lock' time.sleep(1) #暂停线程,避免与consumer争lock class Consumer(threading.Thread): def run(self): while(1): global x print 'consumer accquire lock' condition.acquire() print 'Consumer get lock' if x == 0: print 'x==0 consumer wait,and release lock' condition.wait() else: x = x - 1 print 'consuming ',x time.sleep(1) condition.notify() print 'consumer done, notify others' condition.release() #print 'consumer release lock' time.sleep(1) x = 5 p = Producer() c = Consumer() p.start() c.start() 上述代码首先从Thread中继承得到两个子类。线程Thread类的继承只需要实现run方法即可。run方法在线程执行start启动线程被调用。Producer与Consumer的结构基本相同,只是判断进入wait或notify的条件不一样而已。当生产者当生产的量大于一定的阈值,调用wait进入等待状态,此时Consumer获得lock,消耗一个产品,并通知生产者继续生产。执行的结果如下所示,产品x的数量始终保持在30左右。 Consumer get lock consuming 22 consumer done, notify others producer get lock producing 27 producer done, notify others producer accquire lockconsumer accquire lock producer get lock producing 32 producer done, notify others Consumer get lock consuming 31 consumer done, notify others producer accquire lock producer get lock x>need_max producer wait,and release lock consumer accquire lock Consumer get lock consuming 30 consumer done, notify others consumer accquire lockproducer accquire lock Semaphore (TO DO) Event 事件对象是实现线程之间安全通通信的一种简单的方法。Event内部管理着一个内部标志,调用者可以用set()和clear()方法控制这个标志。其他线程可以使用wait()暂停直到设置这个标志,即线程调用wait()等待,调用的线程被阻塞,直到event被set或timeout,才继续执行。 以车辆等待红绿灯为例。 import threading import time class VehicleThread(threading.Thread): def __init__(self,threadName,event): threading.Thread.__init__(self,name=threadName) self.event = event def run(self): time.sleep(int(self.getName()[7:])) print self.getName(),'arrive,wait for green light' self.event.wait() print self.getName(),'passed' green_light_event = threading.Event() vehicleThreads = [] for i in xrange(10): vehicleThreads.append(VehicleThread('vehicle'+str(i),green_light_event)) for t in vehicleThreads: t.start() while threading.activeCount() > 2: #在python中除了主线程还有一个Thread-1, #IPython运行有5个线程?(Thread-5 Thread-1 MainThread Thread-4 IPythonHistorySavingThread) green_light_event.clear() time.sleep(3) print "green light appera!!! let's GO" green_light_event.set() time.sleep(1) # for t in threading.enumerate(): # print t.getName() thread与Queue的联合使用 (TO DO) 参考链接 Python Standard Library Python Standard Library-threading Python Moudle of the Week--threading Python 标准库学习 GIL Queue and Thread
-
python 迭代器&生成器 __iter__为python中的内建函数,如果想要定义的对象是iterable,你就需要定义__iter__ next(__next__)常与__iter__共同使用,构成迭代器(iterator) 带有yield关键字的函数为生成器(generator) 为了理解这几个关键字和迭代器、生成器。我们从一个常用的斐波那契数列(Fibinacci)开始 常规实现Fibinacci序列生成 def fib(max): n,a,b = 0,0,1 fib_list = [] while n < max : fib_list.append(b) a,b = b, a+b n = n +1 return fib_list
-
Pandas学习笔记 DataFrame 常用方法 Groupby的用法 Apply的用法 axis参数可用于指定按行处理还是按列处理 遍历DataFrame方法 DataFrame访问行列 # 根据row index name索引 df.loc[INDEX_NAME] # 根据column name 索引 df[COLUMN_NAME] DataFrame和Dict的相互转换 Dict to DataFrame: pandas.DataFrame.from_dict Series 常用方法 一些不常用的操作 # 对未命名column进行重命名 data.rename(columns={'Unnamed: 0':'new column name'}, inplace=True) 参考链接 Pandas 官方教程 Pandas 官方API Pandas教程 | 超好用的Groupby用法详解 Pandas|常见用法整理 10min快速入门
-
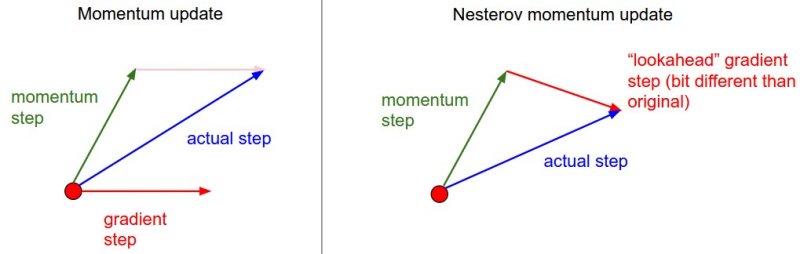
一阶梯度优化方法小结 1. 前言 梯度下降法的基本原理是,通过对目标函数做泰勒展开,当变量的运动方向与梯度方向相同,目标函数值增长最快;负梯度方向,目标函数值减小最快。这里主要讨论将目标函数做一阶泰勒展开,也就是一阶梯度优化方法。利用二阶泰勒展开,即牛顿法需要计算Hessian矩阵的逆,计算量大,在深度学习中并不常用。BGD(Batch Gradient Decent)利用整个训练集计算梯度,优化速度慢,需要一次将所有数据加载进内存不适用于在线学习,因此,在神经网络的优化中常采用mini-batch SGD(Stochastic Gradient Descent)进行优化。SGD主要存在以下两个问题: 难以确定学习率,并且不同的参数需要不同大小的学习。SGD比BGD收敛更快,但在最优解附近可能调整过大,导致在最优点附近震荡,因此基于SGD的算法,随着迭代的进行,不断减小学习率来解决这个问题。例如Caffe中有poly,inv,step等策略来调整学习率 鞍点(各个方向,梯度为0)的存在使得基于梯度的优化方法,难以逃离鞍点 2. 主要内容 SGD+Momentum NAG AdaGrad RMSProp AdaDelta Adam 这里主要以尽可能简单的语言总结各个算法的内容,具体细节参考文末链接
-
Developing new layers in caffe caffe官方的层更新的速度还是比较慢,有时不得不自己实现新的层。本文以实现L2 normalize为例(详细代码,可以查看CaffeLayers),简单记录下实现的过程。 实现新的层,主要步骤如下: 实现xx_layer.hpp 实现xx_layer.cpp 实现xx_layer.cu 修改caffe.proto(可选) 实现test_xx_layer.cpp(可选,推荐完成) 在实现的过程中顺便对C++的语法进行简要的复习。 normalize_layer.hpp 我们需要定义NormalizeLayer这个类,这个类需要从抽象类Layer 中继承。声明需要改写的虚函数。LayerSetUp() 、type() 、 限制该层的输入bottom和top个数 和 Forward_cpu() 、 Forward_gpu() Backward_cpu() 、Backward_gpu() 等。 NormalizeLayer() 构造函数NormalizeLayer()用Layerparameter& param作为形参,并调用父类的构造函数实现。 explicit NormalizeLayer(const Layerparameter ¶m) :Layer<Dtype>(param){} 注: explicit 可以避免构造函数被调用造成隐式转换,用explicit声明的构造函数只能用于直接初始化 LayerSetUp() 完成网络建立时,从prototxt中读取Layer的参数,可通过this->layerparam 访问该层的参数并对类的成员变量进行初始化并为网络的权重参数分配存储。 NormalizeLayer中没有参数,所以这一步可以省略掉。 virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>&top); type() type() 函数是一个返回层的层的种类的inline函数,形式如 virtual inline const char* type() const {return "Normalize";} Reshape() Reshape()与LayerSetUp的功能类似,但是LayerSetUp() 只在网络初始化时被调用,而reshape是在每次前向计算前,根据Bottom的大小动态计算Top的大小并分配存储(只要与Bottom大小相关的都要重新分配存储)。在此处,需要重新分配存储的是top和成员变量, 通过调用Blob的Reshape函数即可。 virtual void Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); Blobs数目相关 virtual inline int ExactNumBottomBlobs() const {return 1;} virtual inline int ExactNumTopBlobs() const {return 1;} 前向后项传播(CPU&GPU) virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); 类成员变量的声明 //保留前向的中间变量,可以减少反向传播中相同表达式的计算量 //squared_: bottom的平方(Elememt-wise) //norm_: 由样本特征的L2范数构成的向量(size: num) //sum_multiplier_: GPU实现辅助变量 Blob<Dtype> sum_multiplier_, norm_, squared_; normalize_layer.cpp 实现normalize_layer.hpp中相关函数的定义, 在normalize_layer.cpp 中,我们需要对前向Forward_cpu,后向Backward_cpu,Reshape进行实现。 Reshape template <typename Dtype> void NormalizeLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ top[0]->Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[0]->height(), bottom[0]->width()); squared_.Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[0]->height(), bottom[0]->width()); } Forward_cpu 前向操作比较简单即 y=x/||x|| template <typename Dtype> void NormalizeLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top){ const Dtype* bottom_data = bottom[0]->cpu_data(); Dtype* top_data = top[0]->mutable_cpu_data(); Dtype* squared_data = squared_.mutable_cpu_data(); int n = bottom[0]->num(); int d = bottom[0]->count() / n; caffe_sqr<Dtype>(n*d, bottom_data, squared_data); for (int i=0; i<n; ++i) { Dtype normsqr = caffe_cpu_asum<Dtype>(d, squared_data+i*d)+(Dtype)1e-10; caffe_cpu_scale<Dtype>(d, pow(normsqr, -0.5), bottom_data+i*d, top_data+i*d); } } Backward_cpu 这里先简单介绍下NormalizeLayer的反向求导。 $E=f(y_{1},y_{2},...y_{n})$ $E=f(y_{1}(x_{1},s(x_{1},x_{2},...,x_{i})),y_{2}(x_{2},s(x_{1},x_{2},...,x_{i},...x_{n})),y_{i}(x_{i},s(x_{1},x_{2},...,x_{i},...x_{n}))$ 其中$s =\left \| x\right \| = \sqrt{x_{1}^{2}+x_{2}^{2}+...+x_{n}^{2}},y_{i}=\frac{x_{i}}{s}$,n表示向量的维度 $\frac{\partial E}{\partial x_{i}} =\frac{\partial E}{\partial y_{i}}*\frac{\partial y_{i}}{\partial x_{i}}+\sum_{j=1}^{n} \frac{\partial E}{\partial y_{j}}*\frac{\partial y_{j}}{\partial s}*\frac{\partial s}{\partial x_{i}} =\frac{\partial E}{\partial y_{i}}*(\frac{1}{s}+\sum\_{j=1}^{n}(-\frac{x_{j}}{s^2})*(\frac{x_{j}}{s}))=\frac{\partial E}{\partial y_{i}}*\frac{1}{s}(1-\sum_{j=1}^{n}y_{j}^{2})=\frac{\partial E}{\partial y_{i}}*\frac{1}{s}(1-y \cdot y)$ void NormalizeLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down,const vector<Blob<Dtype>*>& bottom){ const Dtype* top_diff = top[0]->cpu_diff(); const Dtype* top_data = top[0]->cpu_data(); const Dtype* bottom_data = bottom[0]->cpu_data(); Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); int n = top[0]->num(); int d = top[0]->count() / n; for (int i=0; i<n; ++i) { Dtype a = caffe_cpu_dot(d, top_data+i*d, top_diff+i*d); caffe_cpu_scale(d, a, top_data+i*d, bottom_diff+i*d); caffe_sub(d, top_diff+i*d, bottom_diff+i*d, bottom_diff+i*d); a = caffe_cpu_dot(d, bottom_data+i*d, bottom_data+i*d); caffe_cpu_scale(d, Dtype(pow(a, -0.5)), bottom_diff+i*d, bottom_diff+i*d); } } 实例化模板类 #ifdef CPU_ONLY STUB_GPU(NormalizeLayer); #endif INSTANTIATE_CLASS(NormalizeLayer); REGISTER_LAYER_CLASS(Normalize); STUB_GPU 定义GPU的前向后向操作 INSTANTIATE_CLASS 实例化模板类 REGISTER_LAYER_CLASS 完成类的注册(工厂模式) normalize_layer.cu caffe中将大部分数学操作都实现了GPU和CPU两种版本,例如,caffe_cpu_dot 和 caffe_gpu_dot,所以一般的层的GPU实现只需要把CPU实现的函数改成对应的GPU版本就可以。 修改caffe.proto(可选) 由于Normalize该层没有需要设置的参数,所以caffe.proto并不需要修改. 实现test_normalize_layer.cpp 为了验证自己编写层的正确性,我们通过在test中测试层的前向和反向操作。caffe中运用Google C++ Testing Framework 来进行测试。关于gtest,可以参考gtest in caffe 编写完测试文件,重新编译,进行测试 $ make $ make test $ make runtest GTEST_FILTER='NormalizeLayerTest/*' Note:最后一条命令行不要漏了/* ! Reference caffe wiki--Development caffe wiki--Simple Example: Sin Layer math_functions help test_gradient_check_util
-
Caffe之Cuda C caffe中能够很方便地切换CPU或者GPU模式,但是如果我们想要develop 新的层,则需要写cpp和cu文件,相比之下theano比caffe的扩展方便地多。首次读Caffe的代码,简单记录学习下cu文件如何实现。 CUDA C CUDA C最简单的形式就是C语言而已,如果不涉及GPU的操作,当然这样也还是能够被NVIDIA的编译器NVCC所编译。 __global__ void kernel(void){} CUDA 中 __global__ 表明该函数在device(GPU)设备上运行,并且由host(CPU)调用。例如一个加法程序 __global__ void add(int* a, int* b, int*c) { *c = *a + *b; } int main(void) { int a,b,c; int *gpu_ptr_a,gpu_ptr_b,gpu_ptr_c; int size = sizeof(int); cudaMalloc((void**)&gpu_ptr_a,size); cudaMalloc((void**)&gpu_ptr_b,size); cudaMalloc((void**)&gpu_ptr_c,size); a = 2; b = 7; cudaMemcpy(gpu_ptr_a,&a,size,cudaMemcpyHostToDevice); cudaMemcpy(gpu_ptr_b,&b,size,cudaMemcpyHostToDevice); add<<<1,1>>>(gpu_ptr_a,gpu_ptr_b,gpu_ptr_c); cudaMemcpy(&c,gpu_ptr_c,size,cudaMemcpyDeviceToHost); cudaFree(gpu_ptr_a); cudaFree(gpu_ptr_b); cudaFree(gpu_ptr_c); return 0; } 内存管理 CUDA对device(GPU )的内存管理主要通过cudaMalloc()、cudaFree()、cudaMemcpy() 进行管理。另外,从上述代码我们可以看到,add() 函数的调用比较奇怪相对于C语言来说,需要用add<<<M,N>>> 这种形式表明这是一个从host(CPU)代码调用device的代码,并且括号中的数值表明,M个block,每个block有 N个线程, 所以这个函数总共有M*N个线程。 CUDA 并行操作 CUDA中用来实现并行操作的有block 和thread 两个模块。 block在代码中用blockIdx.x 指示。blockIdx.x为cuda中内建(build-in)的变量,它表明正在执行状态下的block的index。Cuda允许使用多维的索引,.x 为常用的一维索引。一个block可以切分成不同的threads。 thread 在代码中用 threadIdx.x表示线程的标号。thread是block的进一步划分,thread好处在于并行的block难以进行通信和同步(Communciate and Synchronize ),thread通过Shared Memory 在线程之间进行同步,在CUDA C用关键字__shared__ 表示。 #define N 512 __global__ void dot(int *a,int *b, int *c) { __shared__ int temp[N]; temp[threadIdx.x] = a[threadIdx.x] * b[threadIdx.x]; __syncthreads(); if(0 == threadIdx.x) { int sum = 0; for(int i=0; i<N; i++) { sum += temp[i] ; } *c = sum; } } 上述代码实现了向量点积的过程。 涉及到多线程操作和内存共享的问题,必须要考虑线程之间的同步。__syncthreads() 实现的就是这个目的,只有当所有的线程运行到了__syncthreads() 处(即共享的temp[N]已经运算完成)线程才能继续向下执行,否者temp[N] 还没写完就去读,sum得到的结果就未知了。 sigmoid_layer.cu 简析 cu文件的组成: host(CPU)调用的函数Forward_gpu()和Backward_gpu() 在device(GPU)上计算的核函数(由CPU中的函数调用) 实例化函数模板,包括Forward_gpu()和Backward_gpu() 下面以sigmoid_layer的CUDA实现进行简要分析。 template <typename Dtype> __global__ void SigmoidForward(const int n, const Dtype* in, Dtype* out) { CUDA_KERNEL_LOOP(index, n) { out[index] = 1. / (1. + exp(-in[index])); } } 上面是sigmoid的前向传播函数的核函数,这里CUDA_KERNEL_LOOP其实是定义在在device_alternate.hpp 的宏,CUDA_KERNEL_LOOP的详细解释可以参考这篇问答 #define CUDA_KERNEL_LOOP(i, n) \ for (int i = blockIdx.x * blockDim.x + threadIdx.x; \ i < (n); \ i += blockDim.x * gridDim.x) 但是caffe中与此处 的解释不太相同。caffe中固定每个block中线程的个数, 即然后根据元素的个数动态分配block的数目,定义如下 // CUDA: use 512 threads per block const int CAFFE_CUDA_NUM_THREADS = 512; // CUDA: number of blocks for threads. inline int CAFFE_GET_BLOCKS(const int N) { return (N + CAFFE_CUDA_NUM_THREADS - 1) / CAFFE_CUDA_NUM_THREADS; } 所以利用CAFFE_GET_BLOCKS 方法,线程的个数始终大于或等于元素个数N,故不存在一个线程 for循环处理多个元素。在CUDA_KERNEL_LOOP 中,只有在线程的个数小于元素个数N的情况下for循环才起效。 Forward_gpu() 、 Backward_gpu() 调用核函数实现就不展开介绍了。 最后cu文件还需要对Forward_gpu()和Backward_gpu() 进行显示实例化(instantiation)。 INSTANTIATE_LAYER_GPU_FUNCS(SigmoidLayer); 上述代码是Caffe中定义的一个宏,具体展开如下 #define INSTANTIATE_LAYER_GPU_FORWARD(classname) \ template void classname<float>::Forward_gpu( \ const std::vector<Blob<float>*>& bottom, \ const std::vector<Blob<float>*>& top); \ template void classname<double>::Forward_gpu( \ const std::vector<Blob<double>*>& bottom, \ const std::vector<Blob<double>*>& top); #define INSTANTIATE_LAYER_GPU_BACKWARD(classname) \ template void classname<float>::Backward_gpu( \ const std::vector<Blob<float>*>& top, \ const std::vector<bool>& propagate_down, \ const std::vector<Blob<float>*>& bottom); \ template void classname<double>::Backward_gpu( \ const std::vector<Blob<double>*>& top, \ const std::vector<bool>& propagate_down, \ const std::vector<Blob<double>*>& bottom) #define INSTANTIATE_LAYER_GPU_FUNCS(classname) \ INSTANTIATE_LAYER_GPU_FORWARD(classname); \ INSTANTIATE_LAYER_GPU_BACKWARD(classname) caffe中定义的都是函数模板,是不会参与编译的,所以只有把函数实例化(INSTANTIATE),编译器才会编译函数模板。类似的,我们在sigmoid_layer.cpp 文件中,代码最后的 INSTANTIATE_CLASS(SigmoidLayer); 也是同样的道理,将模板类实例化。 //------common.hpp #define INSTANTIATE_CLASS(classname) \ char gInstantiationGuard##classname; \ template class classname<float>; \ template class classname<double> reference [pdf] GPU Technology conference----CUDA C [pdf] CUDA范例精解通用GPU编程 caffe CUDA 相关宏定义 under-the-hood-caffe sigmoid_layer.cu caffe 中的一些编程规范