搜索到
1
篇与
机器学习
的结果
-
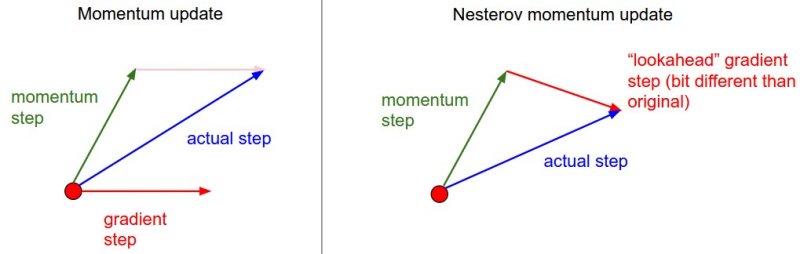
 一阶梯度优化方法小结 1. 前言 梯度下降法的基本原理是,通过对目标函数做泰勒展开,当变量的运动方向与梯度方向相同,目标函数值增长最快;负梯度方向,目标函数值减小最快。这里主要讨论将目标函数做一阶泰勒展开,也就是一阶梯度优化方法。利用二阶泰勒展开,即牛顿法需要计算Hessian矩阵的逆,计算量大,在深度学习中并不常用。BGD(Batch Gradient Decent)利用整个训练集计算梯度,优化速度慢,需要一次将所有数据加载进内存不适用于在线学习,因此,在神经网络的优化中常采用mini-batch SGD(Stochastic Gradient Descent)进行优化。SGD主要存在以下两个问题: 难以确定学习率,并且不同的参数需要不同大小的学习。SGD比BGD收敛更快,但在最优解附近可能调整过大,导致在最优点附近震荡,因此基于SGD的算法,随着迭代的进行,不断减小学习率来解决这个问题。例如Caffe中有poly,inv,step等策略来调整学习率 鞍点(各个方向,梯度为0)的存在使得基于梯度的优化方法,难以逃离鞍点 2. 主要内容 SGD+Momentum NAG AdaGrad RMSProp AdaDelta Adam 这里主要以尽可能简单的语言总结各个算法的内容,具体细节参考文末链接
一阶梯度优化方法小结 1. 前言 梯度下降法的基本原理是,通过对目标函数做泰勒展开,当变量的运动方向与梯度方向相同,目标函数值增长最快;负梯度方向,目标函数值减小最快。这里主要讨论将目标函数做一阶泰勒展开,也就是一阶梯度优化方法。利用二阶泰勒展开,即牛顿法需要计算Hessian矩阵的逆,计算量大,在深度学习中并不常用。BGD(Batch Gradient Decent)利用整个训练集计算梯度,优化速度慢,需要一次将所有数据加载进内存不适用于在线学习,因此,在神经网络的优化中常采用mini-batch SGD(Stochastic Gradient Descent)进行优化。SGD主要存在以下两个问题: 难以确定学习率,并且不同的参数需要不同大小的学习。SGD比BGD收敛更快,但在最优解附近可能调整过大,导致在最优点附近震荡,因此基于SGD的算法,随着迭代的进行,不断减小学习率来解决这个问题。例如Caffe中有poly,inv,step等策略来调整学习率 鞍点(各个方向,梯度为0)的存在使得基于梯度的优化方法,难以逃离鞍点 2. 主要内容 SGD+Momentum NAG AdaGrad RMSProp AdaDelta Adam 这里主要以尽可能简单的语言总结各个算法的内容,具体细节参考文末链接