搜索到
6
篇与
职场经验复盘
的结果
-
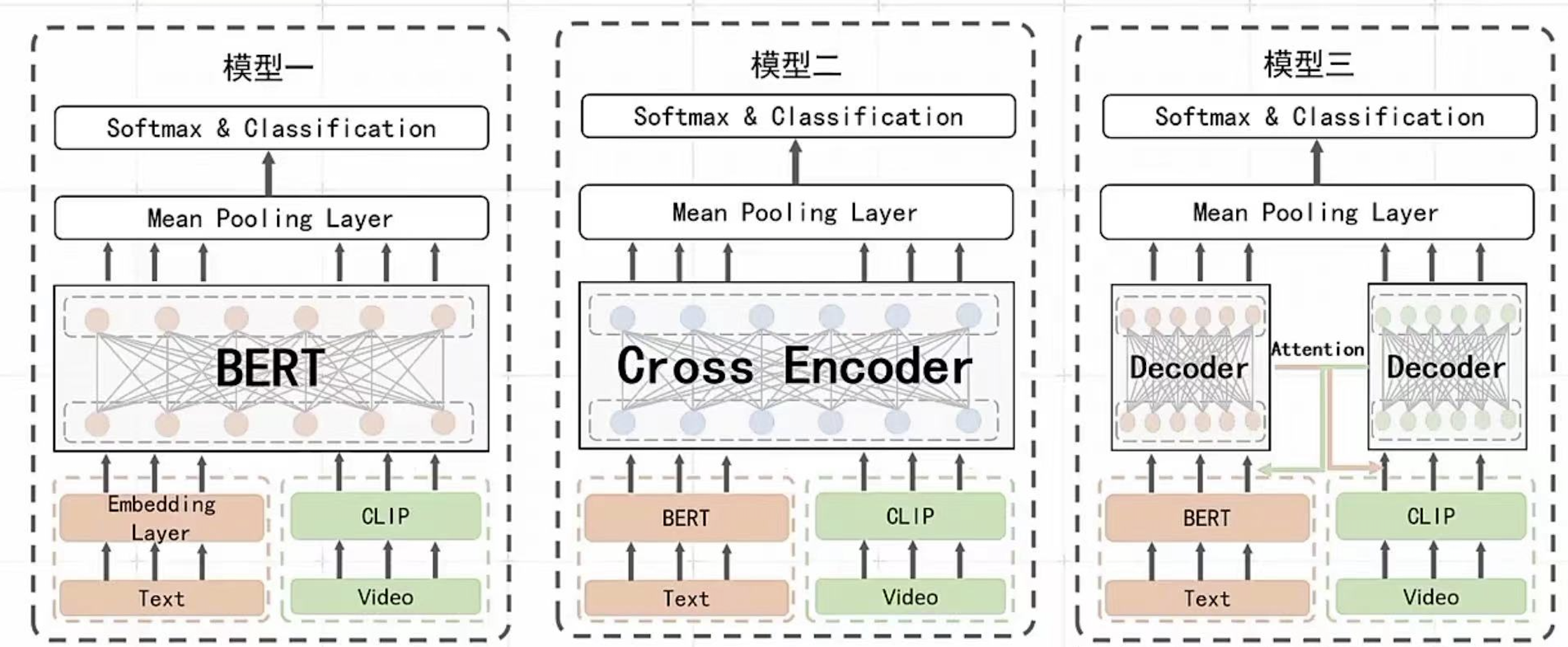
 2022年微信大数据比赛(多模态短视频分类)总结 写在前面 今天(2022.09.17), 微信大数据比赛进行了现场决赛答辩。由于工作内容和比赛比较相关,所以一直有关注。简单总结下听完线上现场答辩直播后的一些感受。近年来随着短视频的发展,多模态视频分类任务变得越来越火,多模态分类算法方案从最开始的: 多模态特征提取后简单concat拼接的baseline方案,演进到目前主流采用在大规模数据下进行预训练方式,来充分利用无标注数据获取更好的特征表示和将不同模态特征对齐,参赛选手都是基于预训练+Finetune方式来做的,但答辩现场给我影响最深刻的就是,评委张正友老师谈到的: 选手针对赛题本身问题做的优化太少。我们在做算法优化的时候,应该优先去做哪些算法优化点, 我相信这也是算法工程师经常遇到的问题。本文主要围绕这个谈谈个人的想法,最后总结下比赛中多模态分类里的一些上分优化点。 从数据分析问题出发还是“无脑堆好模型”? 这道赛题的难点如果去做数据分析,我们大概率会发现是这些问题:1) 数据类别分布不均衡;2) ASR/OCR/Title文本数据存在噪声(识别不准确 + 标签党视频文本不匹配等等),直接做对视频/文本对比学习可能噪声大;3)ASR/OCR相比较于标题而言噪声更大,如何区分处理不同类型的文本;4)标签体系是层次的,包括一级分类和二级分类,做层次分类可能对比模型精度能够有提升 5)标注数据GT是有噪声的, 如何做带噪学习训练,和标签数据清洗等方面。6) 如何利用大量无标注数据。这类问题每个都能找到很多论文来解决,但到底最后能对最终的评测指标能有多少提升却很难准确预估。 比赛的第一名GDY的方案,最大的不同的地方是利用单流/双流等差异性足够大的模型做集成,最后再利用模型蒸馏的想法将未标注的数据集利用起来。想法其实也很简单,利用好而不同的模型集成和模型蒸馏也是教科书里面会涉及的知识点,但就是这拉开了和其他选手之间的比分差距。对于数据分析能表现出来的问题,没有在最终方案中体现出来。比如数据不均衡问题,第一名没有做特殊处理优化,只是简单地使用了训练数据类别重采样,和利用蒸馏得到的伪标签样本进行类别平衡。 所以,这就引发我思考: 我们在做算法优化的时候,应该优先去做哪些算法优化。基于数据分析问题出发,还是直接无脑把先各种最好的模型堆叠起来,去快速不断尝试刷新指标。如果基于数据分析到的问题来解决问题,我们可能会采取以下一些方案: 比如标注数据GT带噪,可能最无脑的方式是顾一大批人,来人工把数据智能清洗一遍(有钱好办事) 更高效一点的方式,是利用聚类算法,基于规则对数据进行清洗 偏学术的做法,基于带噪训练的框架, 选择对噪声更鲁邦的损失函数等 这些针对具体问题出发的解决方法和“选择一个更好的模型”,那个应该优先做?对于选手来说,在限定时间的比赛阶段来看,能够快速做模型迭代是很重要的。对在岗工程师而言,如果抓不住主要矛盾,而导致项目不能在deadline前完成也不好交差。 一些想法(欢迎留言讨论) 我觉得 数据分析 + 堆好模型两个都很重要,在不同的时期,需要给两者分配不同的权重 1.项目初期: 数据分析很重要,把事情做对而不是做最好。在工业界做算法开发,不像参加比赛,已经有人给我们准备好了训练和测试集。这些都需要我们自己构建(或外包标注团队),标注数据很可能有错标/缺失的问题,这个时候我们需要结合数据分析把数据做对,而不是疯狂堆好模型。不同的模型在有问题的数据上的测试结果可能就是随机数,不可信。 2.项目中期: 抓住主要矛盾,优先做最大投入产出比的事。 这个时候不能陷入到细节中,要有大局意识,找到投入产出比最大的方面进行优化。但如何找到主要矛盾也是门学问,我觉得主要依赖两点: 足够的经验积累和有效的数据分析。在比赛中,我们无法通过数据分析提前知道模型蒸馏是不是投入产出比最大的优化点,这部分只能试,但试的前提的有自己的insight,知道为什么试这个方案,这个方案预期能带来哪些增益,这就依赖于我们历史积累的经验和读过的论文来大致估计这部分的增益。数据分析也是项目中期需要特别关心的。包括混淆矩阵/PR指标/具体badcase归类等。 3.项目后期: 问题针对性优化,到这个时候已经基本满足业务需求了,基本是精益求精的时候,就更需要结合具体问题逐个击破(对于业务而言,这个时候再做任何模型优化,可能投入产出比并不大~) 多模态分类算法优化点总结 下面主要从数据处理、模型选取、优化tricks、模型集成等方面归纳总结下方案 1.数据处理: 视频抽帧在训练阶段随机采样,增加训练的多样性 文本可以采用分词而不是分字的方式,缓解文本长度过长问题,roberta-base-word-chinese-cluecorpussmall 2.模型选取: 模型选取,能选large就不选base,选择预训练数据集大和模型规模大的模型(clip-large) R2D2 参考BEIT3等 3.优化tricks防止过拟合: EMA模型平均,这个按经验一般有1%左右提升 FGM 文本对抗训练 Finetune时加预训练任务防止过拟合 RDrop: 一致性约束 4.模型集成: 好而不同,选择差异性大的好模型进行集成(单流&双流), 有利于模型蒸馏; 只用单个模型预测的伪标签,自己学自己,提升效果可能不理想 5.模型加速 TensorRT量化,可用选择对backbone模型进行量化,具体的分类模型在量化后的特征上进行训练,以保证精度不降的情况下提升模型推理效率 FasterTransformer Fp16推理 6.预训练任务选择 选手基本都是基于后验评测指标来综合考虑是否加mlm/mfm/vtm等预训练任务 参考链接 复赛结束后微信群内参赛选手讨论内容
2022年微信大数据比赛(多模态短视频分类)总结 写在前面 今天(2022.09.17), 微信大数据比赛进行了现场决赛答辩。由于工作内容和比赛比较相关,所以一直有关注。简单总结下听完线上现场答辩直播后的一些感受。近年来随着短视频的发展,多模态视频分类任务变得越来越火,多模态分类算法方案从最开始的: 多模态特征提取后简单concat拼接的baseline方案,演进到目前主流采用在大规模数据下进行预训练方式,来充分利用无标注数据获取更好的特征表示和将不同模态特征对齐,参赛选手都是基于预训练+Finetune方式来做的,但答辩现场给我影响最深刻的就是,评委张正友老师谈到的: 选手针对赛题本身问题做的优化太少。我们在做算法优化的时候,应该优先去做哪些算法优化点, 我相信这也是算法工程师经常遇到的问题。本文主要围绕这个谈谈个人的想法,最后总结下比赛中多模态分类里的一些上分优化点。 从数据分析问题出发还是“无脑堆好模型”? 这道赛题的难点如果去做数据分析,我们大概率会发现是这些问题:1) 数据类别分布不均衡;2) ASR/OCR/Title文本数据存在噪声(识别不准确 + 标签党视频文本不匹配等等),直接做对视频/文本对比学习可能噪声大;3)ASR/OCR相比较于标题而言噪声更大,如何区分处理不同类型的文本;4)标签体系是层次的,包括一级分类和二级分类,做层次分类可能对比模型精度能够有提升 5)标注数据GT是有噪声的, 如何做带噪学习训练,和标签数据清洗等方面。6) 如何利用大量无标注数据。这类问题每个都能找到很多论文来解决,但到底最后能对最终的评测指标能有多少提升却很难准确预估。 比赛的第一名GDY的方案,最大的不同的地方是利用单流/双流等差异性足够大的模型做集成,最后再利用模型蒸馏的想法将未标注的数据集利用起来。想法其实也很简单,利用好而不同的模型集成和模型蒸馏也是教科书里面会涉及的知识点,但就是这拉开了和其他选手之间的比分差距。对于数据分析能表现出来的问题,没有在最终方案中体现出来。比如数据不均衡问题,第一名没有做特殊处理优化,只是简单地使用了训练数据类别重采样,和利用蒸馏得到的伪标签样本进行类别平衡。 所以,这就引发我思考: 我们在做算法优化的时候,应该优先去做哪些算法优化。基于数据分析问题出发,还是直接无脑把先各种最好的模型堆叠起来,去快速不断尝试刷新指标。如果基于数据分析到的问题来解决问题,我们可能会采取以下一些方案: 比如标注数据GT带噪,可能最无脑的方式是顾一大批人,来人工把数据智能清洗一遍(有钱好办事) 更高效一点的方式,是利用聚类算法,基于规则对数据进行清洗 偏学术的做法,基于带噪训练的框架, 选择对噪声更鲁邦的损失函数等 这些针对具体问题出发的解决方法和“选择一个更好的模型”,那个应该优先做?对于选手来说,在限定时间的比赛阶段来看,能够快速做模型迭代是很重要的。对在岗工程师而言,如果抓不住主要矛盾,而导致项目不能在deadline前完成也不好交差。 一些想法(欢迎留言讨论) 我觉得 数据分析 + 堆好模型两个都很重要,在不同的时期,需要给两者分配不同的权重 1.项目初期: 数据分析很重要,把事情做对而不是做最好。在工业界做算法开发,不像参加比赛,已经有人给我们准备好了训练和测试集。这些都需要我们自己构建(或外包标注团队),标注数据很可能有错标/缺失的问题,这个时候我们需要结合数据分析把数据做对,而不是疯狂堆好模型。不同的模型在有问题的数据上的测试结果可能就是随机数,不可信。 2.项目中期: 抓住主要矛盾,优先做最大投入产出比的事。 这个时候不能陷入到细节中,要有大局意识,找到投入产出比最大的方面进行优化。但如何找到主要矛盾也是门学问,我觉得主要依赖两点: 足够的经验积累和有效的数据分析。在比赛中,我们无法通过数据分析提前知道模型蒸馏是不是投入产出比最大的优化点,这部分只能试,但试的前提的有自己的insight,知道为什么试这个方案,这个方案预期能带来哪些增益,这就依赖于我们历史积累的经验和读过的论文来大致估计这部分的增益。数据分析也是项目中期需要特别关心的。包括混淆矩阵/PR指标/具体badcase归类等。 3.项目后期: 问题针对性优化,到这个时候已经基本满足业务需求了,基本是精益求精的时候,就更需要结合具体问题逐个击破(对于业务而言,这个时候再做任何模型优化,可能投入产出比并不大~) 多模态分类算法优化点总结 下面主要从数据处理、模型选取、优化tricks、模型集成等方面归纳总结下方案 1.数据处理: 视频抽帧在训练阶段随机采样,增加训练的多样性 文本可以采用分词而不是分字的方式,缓解文本长度过长问题,roberta-base-word-chinese-cluecorpussmall 2.模型选取: 模型选取,能选large就不选base,选择预训练数据集大和模型规模大的模型(clip-large) R2D2 参考BEIT3等 3.优化tricks防止过拟合: EMA模型平均,这个按经验一般有1%左右提升 FGM 文本对抗训练 Finetune时加预训练任务防止过拟合 RDrop: 一致性约束 4.模型集成: 好而不同,选择差异性大的好模型进行集成(单流&双流), 有利于模型蒸馏; 只用单个模型预测的伪标签,自己学自己,提升效果可能不理想 5.模型加速 TensorRT量化,可用选择对backbone模型进行量化,具体的分类模型在量化后的特征上进行训练,以保证精度不降的情况下提升模型推理效率 FasterTransformer Fp16推理 6.预训练任务选择 选手基本都是基于后验评测指标来综合考虑是否加mlm/mfm/vtm等预训练任务 参考链接 复赛结束后微信群内参赛选手讨论内容 -
-
-
一些提升工作效率和个人能力的tips 个人能力篇 开会 确定会议主题,避免发散,浪费大部分人的时间 确定会后TODO,此次开会才真正有意义 做事方法论 有很好的产品和技术思维,能够引导产品向技术方向 做事有章法,明确优先级;以问题为出发点,不会拿锤子找钉子 表达能力 表达和工作有逻辑性,层次分明 复杂的东西讲简单,简单的东西讲深刻 向上管理: 业务开会沟通后,及时向上同步总结进展,todo和时间点 项目进度管理 明确事项,在尽可能舒适的情况下,确定交付的目标和时间点 带人篇 如何确认实习生工作是否到位,是否有问题? 确保训练数据没有问题,每个任务都需要写notebook可视化数据,double-check 如何帮助实习生高效完成任务 ⭐️⭐️⭐️ 协助盘点 TODO List 面对具有挑战性问题,亲身下场,建立规则和流程 文档 + git代码管理 设置任务优先级,明确目标 设置截至时间(需要特别注意评估时间是否合理) 人员管理 让实习生说说内心的真实感受,不要让个人情绪影响工作 关注事情的进展,而不是重点管理他的时间,管理工作时间会让人很有压迫感 合作篇 如何与同事合作,让他愿意协助你 沉淀篇 多写文档,多写git,沉淀公用能力工具
-
-