01 这个方向到底在做什么
先用一个具体例子说清楚:
你有一段人物走路的视频,想把他外套换成某张参考图片里的羽绒服。如果用文字指令"把外套换成白色羽绒服"——到底是什么白?什么款式?什么材质?文字说不清楚。但如果你能直接给一张羽绒服的照片当参考,模型就能精确复现你想要的效果:人物动作不变、背景不变,只有外套被替换为参考图中的款式。
这就是视频参考编辑(Reference-guided Video Editing)——用图片代替文字来指挥视频编辑,解决纯文本指令固有的"表达模糊性"。
核心技术挑战:
- 时序一致性:编辑后的视频帧与帧之间不能闪烁/跳变
- 参考保真度:输出要精确复现参考图的纹理/风格/身份,不能"大概像"
- 数据稀缺:训练需要(源视频、指令、参考图、目标视频)四元组数据,此前几乎不存在
本期 8 篇论文覆盖三个子方向:
| 子方向 | 论文 | 解决什么 |
|---|---|---|
| 参考引导编辑 | Kiwi-Edit, LIVE | 精确控制 |
| 统一编辑框架 | VACE, UniVideo, EditVerse | 一个模型做所有事 |
| 大规模编辑数据 | Ditto, OpenVE-3M, Señorita-2M | 训练数据瓶颈 |
02 前史:我们是怎么走到这里的
2023 年以前的视频编辑主要靠两条路线:
- 文本指令路线(InstructPix2Pix → InsV2V):给一段文字描述,模型自动编辑视频。问题:文字描述不够精确,"把头发变金色"——是麦田金还是铂金?不知道。
- 掩码+修复路线:用户手动画 mask 指定编辑区域。问题:交互复杂,不适合大规模应用。
2024 年的变化让参考引导变得可行:
有了这三个前置条件,2025 年开始出现系统性的视频参考编辑研究——数据集从无到百万级,模型从专用到统一,控制从文本到参考图像。
03 深度串讲:Kiwi-Edit — 参考引导的完整范式
来自: National University of Singapore, Show Lab | arXiv:2603.02175
一句话定位: 首个系统性解决"用参考图像引导视频编辑"数据+模型双瓶颈的工作。
核心架构:
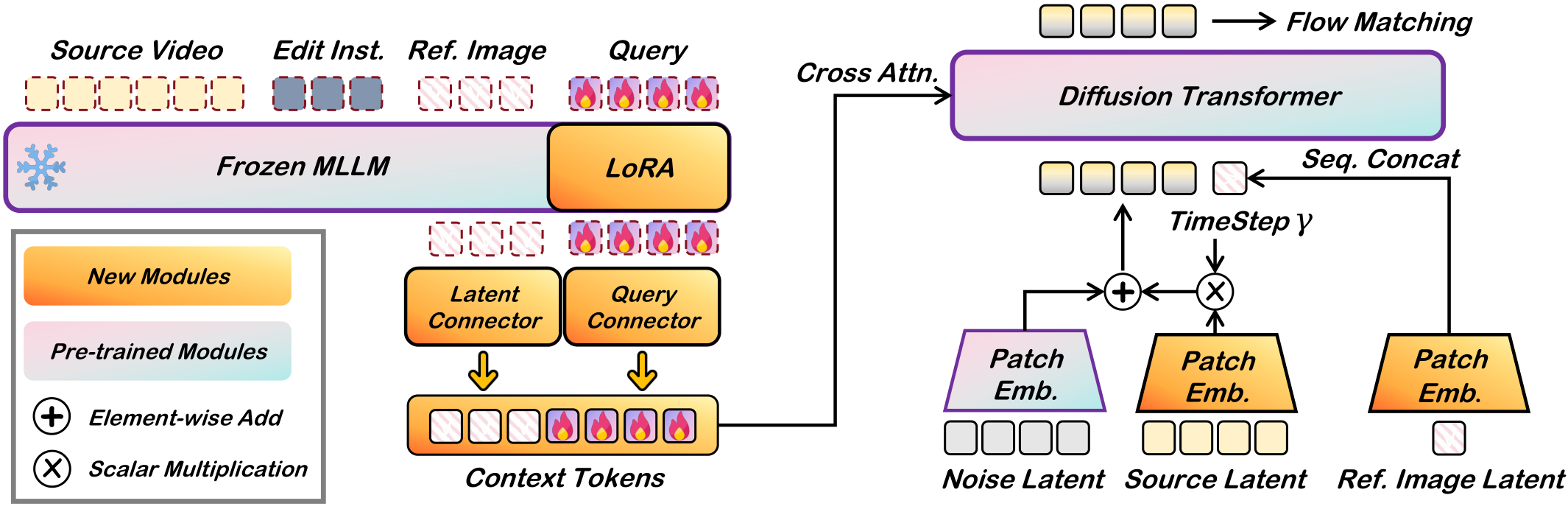
(图片来源:论文 Figure 4,Kiwi-Edit 整体模型架构。左侧 MLLM 处理交错多模态序列(源视频帧+文本指令+参考图像),右侧通过 Query Connector 蒸馏编辑意图 + Latent Connector 提取参考视觉特征,双管齐下注入 DiT 生成编辑视频。)
从图中可以看到两条并行路径的设计逻辑:Query Connector 从 MLLM 中蒸馏出"要编辑什么"的高层语义(编辑意图),Latent Connector 从参考图像提取"编辑成什么样"的像素级视觉特征(外观细节)。为什么要分成两条路?因为"理解指令"和"复现外观"是两个正交维度——你可以用同一条指令搭配不同参考图得到完全不同的结果。
数据 Pipeline(解决四元组数据从 0 到 47.7 万):
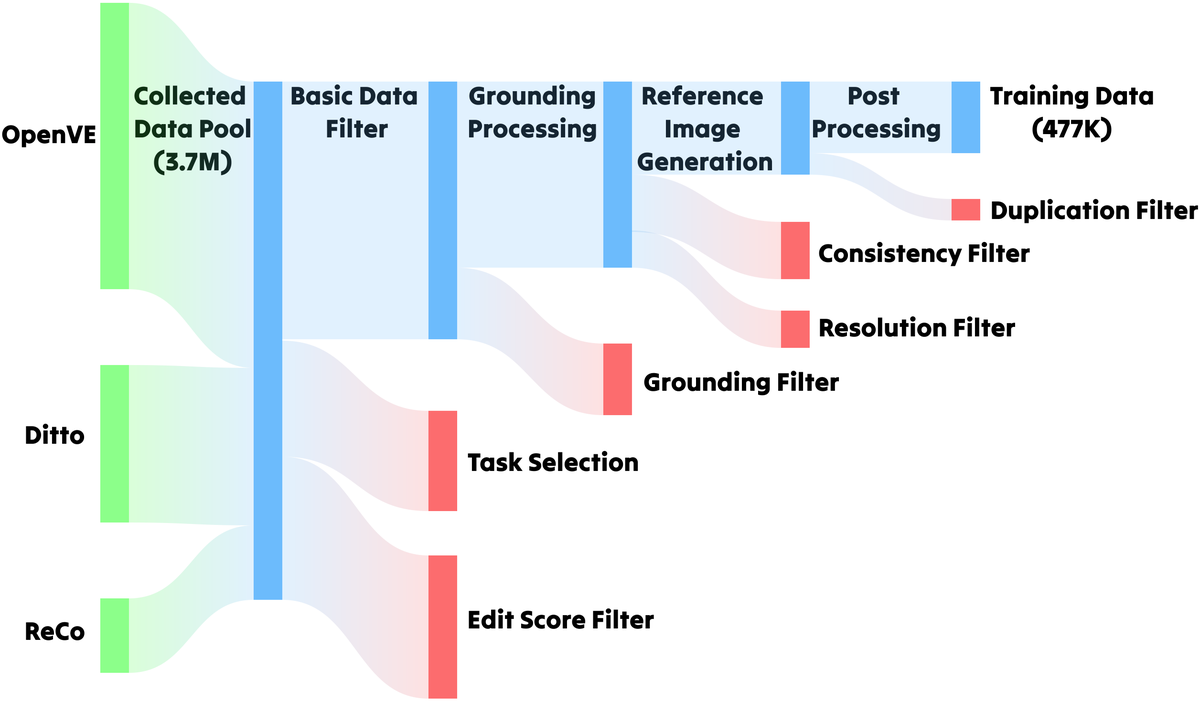
(图片来源:论文 Figure 2,RefVIE 数据集构建 4 阶段流程。从 370 万原始编辑对出发,经过 EditScore 质量过滤 → 指令感知分割 → 参考图像合成 → 语义验证去重。)
这条 pipeline 的巧妙之处在于把已有的二元组(源→目标)转化为四元组(源+指令+参考→目标):从编辑结果中反向提取参考图像,而不是从头收集四元组数据。这使得数据构建成本从"不可能"降到了"可扩展"。
核心方法拆解:
训练数据怎么来?设计 4 阶段 pipeline:(1) 从 Ditto-1M/ReCo/OpenVE-3M 收集 370 万原始编辑对;(2) EditScore 模型过滤低质量样本;(3) MLLM 解析编辑指令 → Grounding + SAM 分割出编辑区域 → 图像生成模型合成该区域的参考图像;(4) 语义验证 + 全局去重。最终产出 47.7 万高质量四元组 RefVIE 数据集。
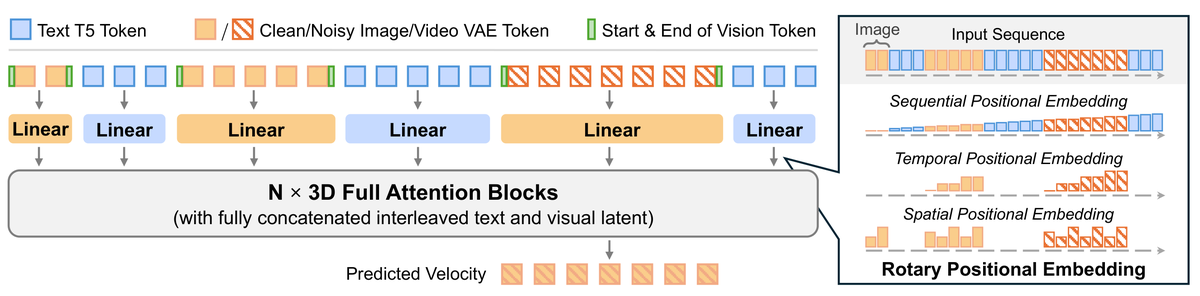
模型怎么设计?基于 Wan-TI2V-5B 骨干,冻结 MLLM(Qwen2.5-VL)处理源视频帧+文本+参考图像的交错序列,通过 Query Connector(learnable query 蒸馏编辑意图)和 Latent Connector(VAE 提取参考图像 latent)双通道注入 DiT。三阶段渐进训练:图像编辑 → 指令视频编辑 → 参考视频编辑。
关键数字:
- 47.7 万四元组训练数据(从零开始构建的新数据格式)
- 全面超越 VIVA、InsV2V、Ditto、VACE 等全部基线
- 数据集 + 模型权重 + HuggingFace Demo 全开源
亮点与不足:
✓ 开创性解决四元组数据稀缺问题,pipeline 可直接复用扩展
✓ 双连接器解耦语义理解和视觉复现两个正交维度
✓ 全套开源,复现门槛极低
✗ 参考图像由图像模型合成,上限受限于图像生成模型能力
✗ 参考图与文本指令矛盾时行为未充分讨论
✗ 数据集可能继承 Pexels 等上游数据的场景偏差
一句话结论: 强烈推荐 — 参考引导视频编辑的"InstructPix2Pix 时刻",数据+模型的完整范式奠基者。
04 深度串讲:VACE — 一个模型替代 12 个
来自: 阿里通义实验室 | arXiv:2503.07598
一句话定位: 基于 Wan 架构的全能视频创编模型,统一条件接口支持 12+ 种任务的任意组合。
核心架构:
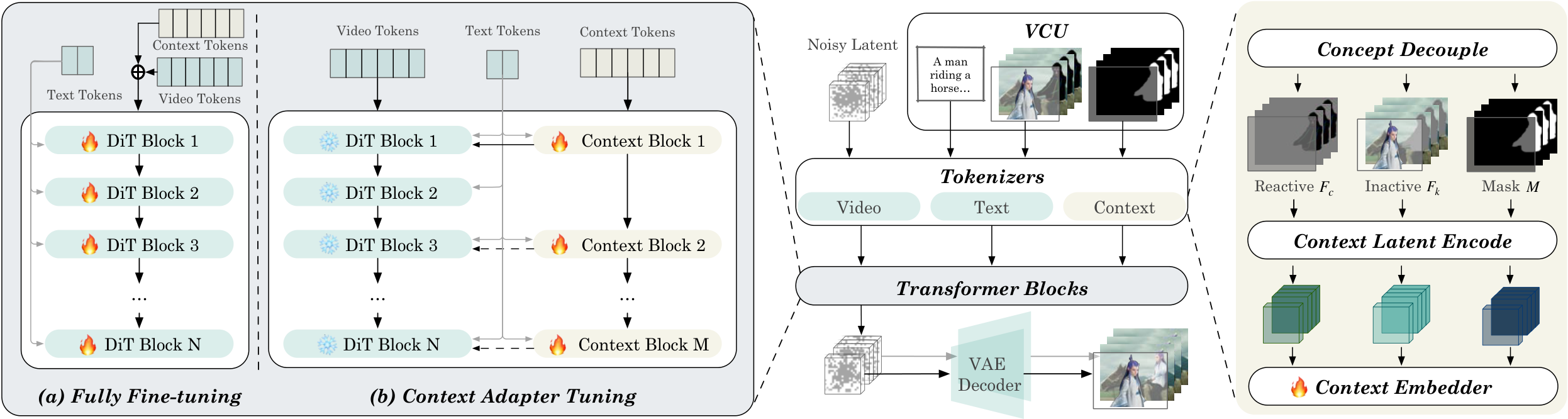
(图片来源:论文 Figure 4,VACE 方法框架。帧和掩码通过 Concept Decoupling 分离自然视频内容与控制信号,经过 VAE 编码后与噪声 latent 一起输入 DiT(Diffusion Transformer);Context Adapter 按任务类型注入概念。)
图中的关键设计是 Concept Decoupling(概念解耦):它把输入分成两部分——"原始视频内容"和"控制条件"。为什么这很重要?因为模型必须区分"什么东西要保留不变"(源视频背景/运动)和"什么东西是控制信号"(深度图/掩码/参考图),否则会混淆两者。
解决的核心问题:
目前部署视频编辑需要一堆模型:修复用 A、深度控制用 B、参考生成用 C、风格迁移用 D——12+ 个模型服务,成本极高。更糟的是这些模型无法组合——你不能同时"用深度图控制结构 + 用参考图指定外观 + 修复某个区域"。
VACE 的核心赌注:设计一个 Video Condition Unit(VCU,视频条件单元)作为统一接口,不管输入是什么模态(文本/图像/掩码/深度图/骨骼图),都编码为统一格式注入 DiT。关键创新:Context Adapter 为每种任务学习一个轻量适配器(参数极少),使得新增任务不需要重新训练整个模型。运行时可以把任意任务的条件叠加使用——训练时是单任务,推理时任意组合。
关键数字:
- 12 种子任务同时支持:inpaint, outpaint, reference, depth, pose, sketch, canny, style...
- 运行时任意子任务组合(首次实现)
- 与各专用模型对比:可比甚至超越
- 已集成到阿里通义视频产品线(工业验证)
亮点与不足:
✓ 一个模型替代 12+ 专用模型,部署成本降低 10 倍+
✓ 任务组合泛化是独特卖点(深度+参考+修复一次完成)
✓ 已在产品线验证工业可行性
✗ 组合越多任务,单任务精度可能下降
✗ 开源版与阿里内部版能力差距不透明
一句话结论: 强烈推荐 — 视频编辑工业化的标杆,工程哲学清晰,产品验证充分。
05 深度串讲:UniVideo — 理解+生成+编辑三合一
来自: 快手可灵 + 滑铁卢大学 | arXiv:2510.08377 | ICLR 2026
一句话定位: 双流 MLLM-DiT 架构实现视频理解、生成、编辑三合一,支持零样本任务组合泛化。
核心架构:
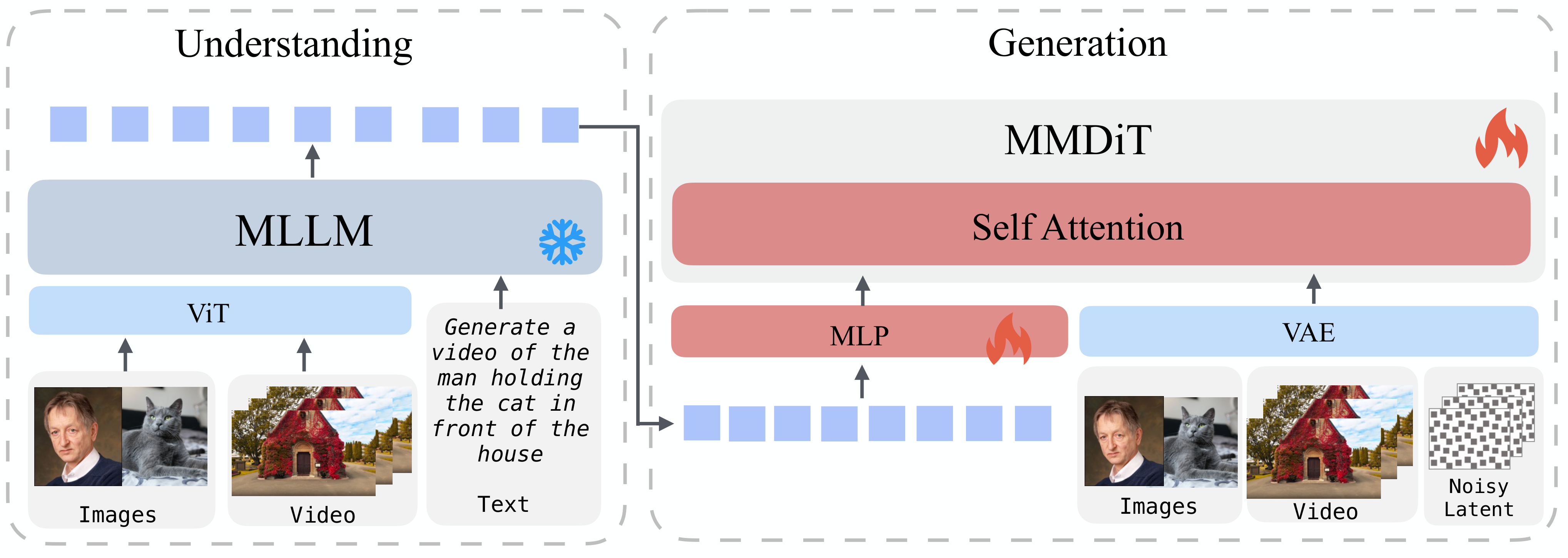
(图片来源:论文 Figure 2,UniVideo 整体架构。左侧 MLLM 流(基于 Qwen2.5-VL)负责理解多模态指令并进行推理,右侧 MM-DiT 流(基于 HunyuanVideo)负责视频生成/编辑。双流通过语义条件传递协作。)
为什么是"双流"而不是"一个模型"?因为"理解语言指令"和"生成像素视频"本质上是两种不同的能力——前者需要 language reasoning,后者需要 pixel synthesis。把它们强行塞进一个模型会互相拖累。UniVideo 的设计让 MLLM 专注理解,DiT 专注生成,各自保持最强项,通过交叉注意力传递条件。
独特能力:无掩码编辑
其他视频编辑方法都需要用户提供 mask 告诉模型"编辑哪里"。UniVideo 是唯一能仅根据文本指令自动定位编辑区域的方法——MLLM 流的推理能力让模型"理解"指令指向视频的哪个区域。
零样本组合泛化: 从未在视频上训练的编辑类型(环境变换、材质替换等),从图像编辑数据迁移后直接可用——说明模型真正学到了"编辑"的本质,而不只是记住训练数据。
关键数字:
- ICLR 2026 接收
- 唯一支持"无掩码编辑"
- 在文/图生视频、上下文编辑等多 benchmark 上 SOTA
- 代码+权重开源
亮点与不足:
✓ 三能力统一 + 无掩码编辑是独特差异化
✓ 零样本泛化证明模型学到了编辑本质
✗ 双流训练 GPU 需求极高(MLLM + HunyuanVideo),复现成本高
✗ 推理延迟大,实用化需解决效率问题
一句话结论: 值得关注 — 学术价值极高(ICLR 2026),但实用化还需时间。
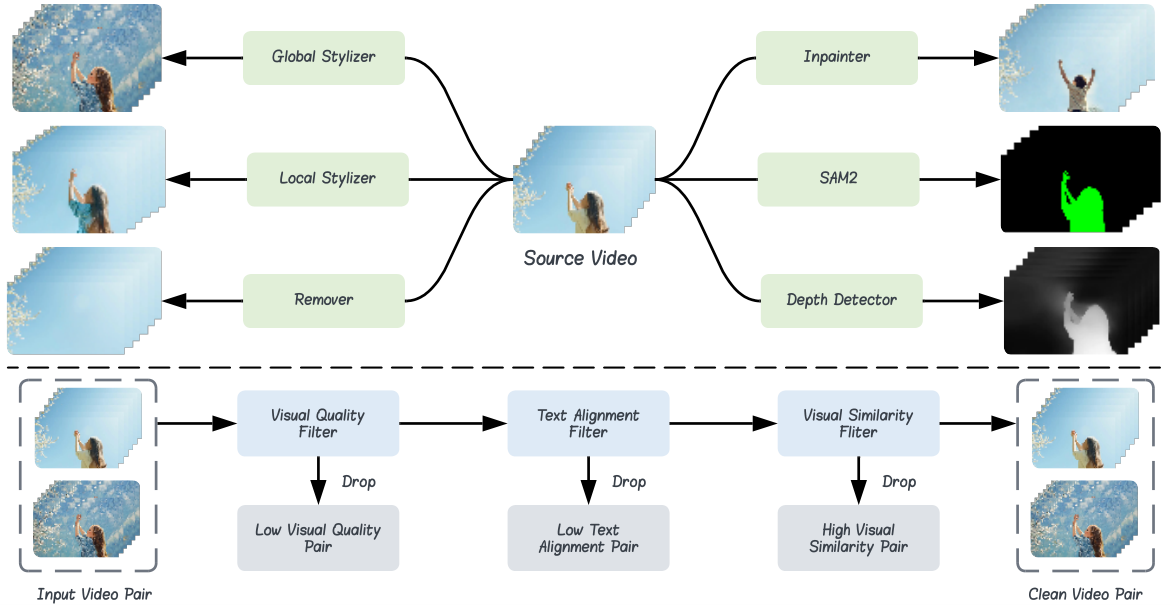
06 数据派:三大数据集如何把数据从十万级推到百万级
数据是这个方向最核心的驱动力。下面这张表最直观:OpenVE-Edit 仅 5B 参数,因为训练数据够好,在 OpenVE-Bench 上全面超越 14B 模型——数据质量 > 模型规模。
Ditto — 首次验证视频编辑的数据 Scaling Law
(图片来源:论文 Figure 2,Ditto 可扩展数据合成流程。VLM(视觉语言模型)密集描述 → 编辑指令生成 → 关键帧编辑 → I2V(图生视频)传播 → 质量过滤。)
Ditto(港科大+蚂蚁)的核心洞察:视频编辑性能瓶颈在数据而非架构。用 Qwen2-VL 对源视频生成密集描述,两步提示策略生成编辑指令,图像编辑模型编辑关键帧,I2V 模型传播到完整视频。关键实验:数据量从 100K → 500K → 1M 持续带来性能提升,无饱和迹象。基于 CogVideoX 架构,权重开源。
OpenVE-3M — 5B 参数超越 14B 的数据为王
(图片来源:论文 Figure,OpenVE-3M 与现有数据集的规模和类型覆盖对比。)
OpenVE-3M(浙大+字节):300 万对、8 种编辑类型(6 种空间对齐 + 2 种非空间对齐)。配套 OpenVE-Bench(431 对,3 维度评估,与人类评价高度对齐)。全套代码/数据/模型/评测开源,复现门槛极低。
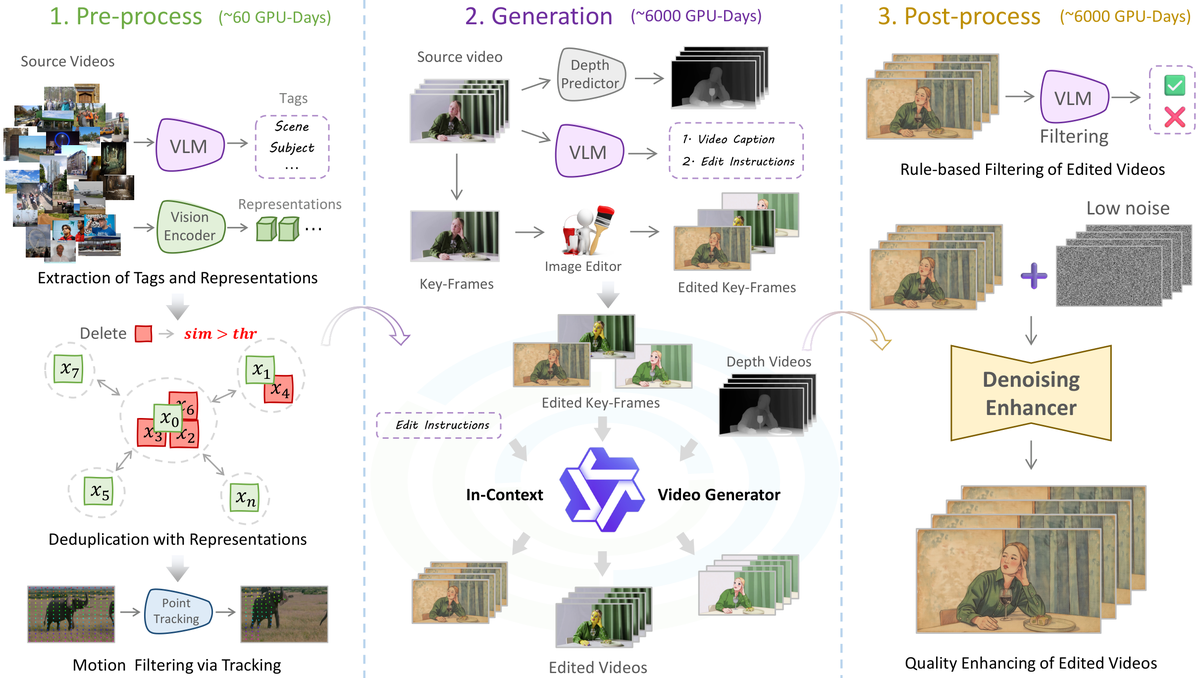
Señorita-2M — 专家模型各司其职
(图片来源:论文 Figure,Señorita-2M 的专家模型合成策略。4 种专用编辑专家分别生成各自擅长类型的数据。)
Señorita-2M(港中文+清华)用"专家模型合成"替代通用模型:训练 4 种专用编辑专家——Global Stylizer(全局风格化)、Local Stylizer(局部编辑)、Text-guided Inpainter(修复)、Object Remover(目标移除),各自生成最擅长类型的高质量数据。200 万对 18 种编辑任务。是 Kiwi-Edit 和 LIVE 的核心上游数据。
三大数据集对比:
| 数据集 | 规模 | 编辑类型数 | 合成策略 | 特色 | 开源 |
|---|---|---|---|---|---|
| Ditto-1M | 100万 | 通用 | 通用模型 | 首验 scaling law | ✓ |
| OpenVE-3M | 300万 | 8 | 多源+严格过滤 | 5B超14B | ✓ |
| Señorita-2M | 200万 | 18 | 专家模型 | 类型最丰富 | ✓ |
07 统一架构补充:EditVerse + LIVE
EditVerse — 用 In-Context Learning 统一所有编辑
(图片来源:论文 Figure 1,EditVerse 框架。文本/图像/视频统一为交错 token 序列,通过 ICL(In-Context Learning,给模型看示例对让它学会编辑)实现零任务特定设计。)
Adobe 的 EditVerse 走了最优雅的一条路:把所有编辑统一为 ICL 问题——给模型看一组"编辑前→编辑后"示例对,它自动学会如何编辑新输入,不需要为每种任务设计专门的条件接口。4D 位置编码(空间 3D + 模态维度)支持任意分辨率和模态混合。23.2 万视频编辑样本训练后展现 emergent 能力:训练未见的编辑组合也能完成。
局限:Adobe 闭源限制社区验证;ICL 序列化导致长视频 token 数爆炸。
LIVE — 图像编辑知识低成本迁移到视频
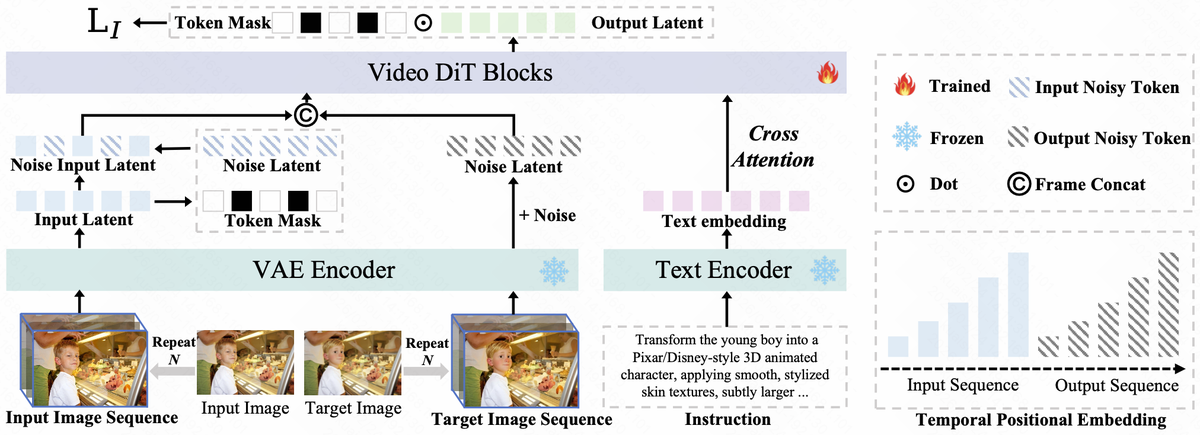
(图片来源:论文 Figure,LIVE 的 Frame-wise Token Noise + 课程学习。将图像编辑对复制为伪视频序列,通过帧级噪声注入打破静态偏置。)
LIVE(快手+南开)解决一个很实际的问题:图像编辑数据有几千万对(类型丰富),视频编辑数据只有百万级(类型有限)。能不能用图像编辑知识增强视频?难点在于:简单把图像复制成视频帧会让模型学会输出"静态画面"(静态偏置)。
LIVE 的 Frame-wise Token Noise 策略:对伪视频序列中的特定帧注入噪声作为"推理 token",迫使模型调用预训练视频生成能力来创造合理的时序变换——从而把图像编辑的多样性"桥接"到视频域。在 LIVE-Bench(60+ 种挑战任务)上达到 SOTA,特别是在图像编辑常见但视频数据稀缺的任务上优势显著。
08 跨论文定量对比
虽然这 8 篇论文使用的 benchmark 不完全统一,但我们仍能汇总一些可比的数据:
编辑质量(指令视频编辑):
| 方法 | CLIP-T ↑ | CLIP-F ↑ | 时序一致 ↑ | 参数量 | 数据量 |
|---|---|---|---|---|---|
| InsV2V (baseline) | 0.248 | 0.935 | 0.961 | — | 40万 |
| Ditto | 0.267 | 0.951 | 0.972 | CogVideoX | 100万 |
| Kiwi-Edit | 高于Ditto | 高于Ditto | — | Wan-5B | 47.7万(四元组) |
| OpenVE-Edit | 超越14B模型 | 超越14B模型 | — | 5B | 300万 |
| LIVE | SOTA on LIVE-Bench | — | — | — | 图+视频联合 |
注:精确数字来自各论文自报,benchmark 不完全一致(Ditto 和 Kiwi-Edit 有直接对比),仅供参考整体趋势。
统一模型能力覆盖:
| 能力 | VACE | UniVideo | EditVerse |
|---|---|---|---|
| 文本编辑 | ✓ | ✓ | ✓ |
| 参考引导 | ✓ | ✓ | ✓(ICL方式) |
| 深度/姿态控制 | ✓ | ✗ | ✗ |
| 视频修复 | ✓ | ✗ | ✓ |
| 视频理解/问答 | ✗ | ✓ | ✗ |
| 无掩码编辑 | ✗ | ✓ | ✗ |
| 任务组合 | ✓ 任意 | ✓ 部分 | ✓ ICL |
| 图像+视频统一 | ✗ | ✗ | ✓ |
| 开源 | 部分 | ✓ | ✗ |
| 产品化 | ✓ 阿里 | ✗ | ✗ |
09 技术全景与趋势信号
三派定位与融合:
| 维度 | 数据派 | 统一架构派 | 参考引导派 |
|---|---|---|---|
| 代表 | Ditto, OpenVE, Señorita | VACE, UniVideo, EditVerse | Kiwi-Edit, LIVE |
| 解决 | "用什么数据训练" | "怎么用一个模型部署" | "怎么精确控制" |
| 核心方法 | 合成 pipeline + 质量过滤 | 统一条件接口 / ICL / 双流 | 双模态条件注入 |
三派正在融合:Kiwi-Edit 建立在 Ditto/Señorita 数据之上;VACE 支持参考引导模式;LIVE 用图像数据增强视频。
4 个趋势信号:
10 实操建议
如果你是研究者:
- 训练数据:OpenVE-3M + Señorita-2M 组合 = 最大规模可用训练数据
- 统一建模:UniVideo 双流架构值得作为 baseline
- 参考引导:Kiwi-Edit 的数据 pipeline 可直接复用扩展更大规模四元组
如果你是工程师:
- 生产部署首选 VACE(一模型 12+ 任务,阿里已验证)
- 参考引导体验:Kiwi-Edit 有 HuggingFace Demo 可快速验证
- 训练自己的模型:OpenVE-3M 全套开源,上手最快
如果你是产品经理:
- 编辑交互正从"文本输入框"升级为"参考图片+文本",需要重设计 UI
- 统一模型意味着一个 API 覆盖所有编辑场景,降低接入成本
11 批判性总结
值得兴奋的: 数据 scaling 系统验证,统一建模三路线同时验证,参考引导完整范式建立。
需要冷静的: 所有百万级数据都是模型合成的——合成数据天花板在哪?没人知道。统一模型在极端精细编辑上是否匹配专用模型?推理效率是所有方案的硬伤。
缺失的: 没人讨论编辑交互设计(用户如何选择编辑方案);实时编辑几乎没人触碰;长视频(>30秒)一致性是公认难题但被回避。
12 入门路线图
🟢 快速了解(30 分钟):
- 读本文 01-02 段了解方向全貌
- 看 08 段跨论文对比表理解格局
🟡 深入理解(半天):
- 精读 Kiwi-Edit 论文(参考引导的完整范式,数据+模型双线)
- 在线体验 Kiwi-Edit HuggingFace Demo
- 读 VACE 论文理解统一架构思路
🔴 动手研究(1 周):
- 下载 OpenVE-3M 数据集,在 5B 基座上训练 baseline
- 复现 LIVE 的 Frame-wise Token Noise 策略(代码清晰)
- 用 VACE 开源版搭建多任务编辑 pipeline
- 尝试用 Kiwi-Edit 的 4 阶段 pipeline 扩展自己的四元组数据
背景阅读:
- InstructPix2Pix (2023) — 指令编辑的开山之作
- ControlNet (2023) — 条件注入的基础范式
- HunyuanVideo / CogVideoX — 视频生成基座模型
作者:人工智能炼丹君
日期:2026-05-09
声明:个人观点,仅供参考。数据来源于原始论文,如有偏差以原文为准。